💻 Vibe Coding
本次分享是 Vibe Coding 的实战篇,将给大家介绍产品经理如何通过与 AI 协作,手搓百宝箱新知识库、百灵管理后台等产品 Demo,在一行代码都没写的情况下提交 5 万行代码。
主要内容:
- 从 idea 或者一句话需求开始 Coding:网页版“谁是卧底”助手
- 从设计稿或已有页面开始 Coding:百宝箱知识库 Demo
- 项目进阶:Spec Driven - 百灵管理后台 Demo
Demo
上周我用 Figma + Claude Code 大概花了 10 分钟生成了一个知识库功能的 MVP 版本,并且在项目组内做了快速沟通,以此优化了一个版本,在以前,这样的工作可能需要到下一个迭代,需要 2 周甚至更长。生成的代码不是完美的,但省下的时间让我能专注优化核心算法和用户体验,迭代了 3 个版本才用了不到 1 天。这个速度于我而言是非常爽的体验。
什么是 Vibe Coding
Vibe 这一概念,最早应该是 Karpathy 提出的,直译是「氛围」的意思。按 Karpathy 所述,这个「氛围」,指的是这种编程方式能让人完全沉浸在创作的氛围中,拥抱指数级增长,甚至忘记代码的存在。
虽然理解起来比较困难,但是这个描述相当精确。Vibe Coding 的精彩之处在于,整个过程非常的 chill,看着 AI 酷酷干活的同时,我可以背靠躺椅,开始估摸 AI 这一轮的产出,同时构思下一轮的 query。上一次听曦征的分享,了解到有人为 Vibe Coding 设计了个 icon,是真的很贴切。正所谓“从从容容,游刃有余”

作为 PD,Vibe Coding 给我的最大价值点
- 想法验证(快速原型,自我迭代)
- 沟通效率
- 基于 demo 生成 PRD 文档、测试用例和评测集
实战分享
接下来,我将结合 3 个具体的案例,来分享 Vibe Coding 的三种方式:
- 从 idea 或者一句话需求开始:ChatGPT/Claude 网页 -> IDE(VSCode、Cursor)
- 从设计稿或已有页面开始:Figma/loveable 初始化 UI -> IDE (VSCode、Cursor)
- Spec Driven:Github Spec Kit
实战案例 1:网页版“谁是卧底”助手
Vibe Coding 把编程的门槛降到很低,既不需要懂规划设计,也不需要懂编码工程。一切只需要从 idea 或一句话需求开始。如今各家 LLM 都已经非常聪明,只需要给到它一个想法,AI 就能从各个维度帮忙完善方案。

以下是一个我和 claude 一起做一个随时卧底助手的 case:
👽 谁是卧底 - 网页版
- 简单,直接,效果还行
- 可以很方便地调整玩法逻辑,AI 能实现得很好
- 难以精细化地调整前端 UI
在反复对话了 3、4 次无果后,为了能够更精细化地调整 UI,我把代码下载到了本地,使用 VSCode + Cladue Code 插件继续优化。
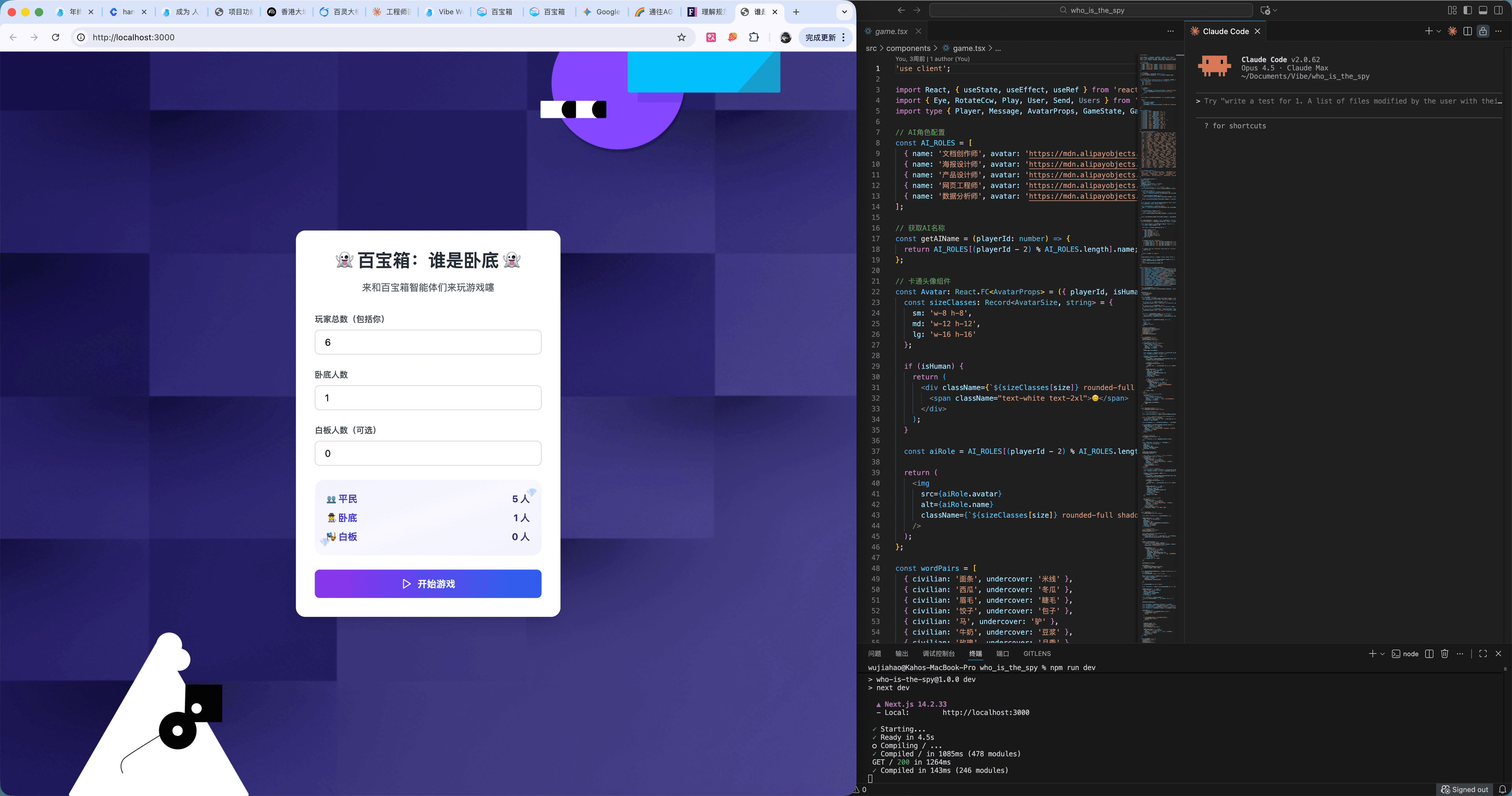
上图就是我的一个工作界面,右侧与 Claude Code 对话(推荐使用 CLI 模式),左侧观察页面效果,中间留一列给自己手动调整代码的余地(虽然基本上用不上)。
分享一些在本地使用 Claude 的小心得:
TIP
- 一定要 /init,否则 Claude 无法理解项目全貌,项目重构过后最好也再 /init 一把
- 善用 Plan Mode,一旦某个问题模型反复 2-3 遍没能彻底根治的时候,此时就应该启用 Plan Mode 让模型先做好改动计划,且与你确认无误后再执行
- 重构优于修补,对于人而言重构可能很花力气,但模型不会累,一旦一个问题补丁来补丁去还有问题,可以尝试直接推倒重来
- CLI 模式也是可以粘贴图片的,善用图片可以让模型更好地理解设计
- 有一些更高阶的用法 Claude Skill 等还没有摸索过,大家如果了解的话可以互相分享下
接下来,我让 Claude Code 生成了 PRD,经过了大约 10 分钟的生成,Claude 完成了任务,经测试,此文档在其他 Vibe Coding 工具上可成功复刻游戏。
提示词:
请根据当前项目,生成一份详细的 PRD 文档,要求提供完整的技术规格,使其他 LLM 能够从零复刻此项目生成的 PRD 文档:
📄 谁是卧底助手 PRD(点击下载)
网页生成 vs 本地生成
采用 IDE + Claude Code 的方式虽然比单纯用网页端生成麻烦,但是生成的效果往往更好,排除端的因素,个人认为还有一个关键影响是在网页端,LLM 倾向于生成 SPA(单页应用),在本地,LLM 倾向于生成由 vite 打包的整个工程项目。
以下都是 LLM 一把梭哈出来的效果,大家猜猜看哪个是 SPA,哪个是工程:
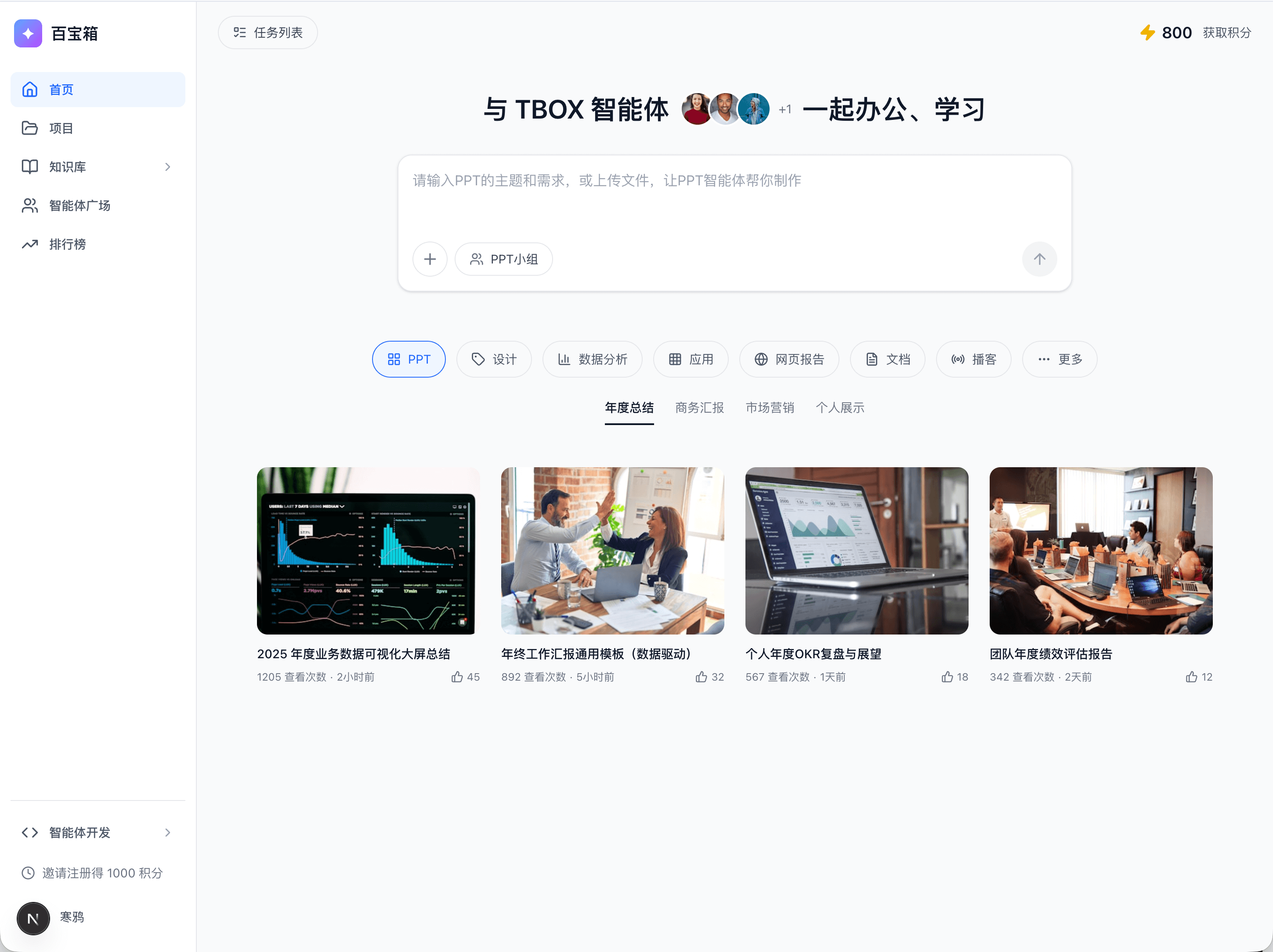
图:左为 SPA,右工程
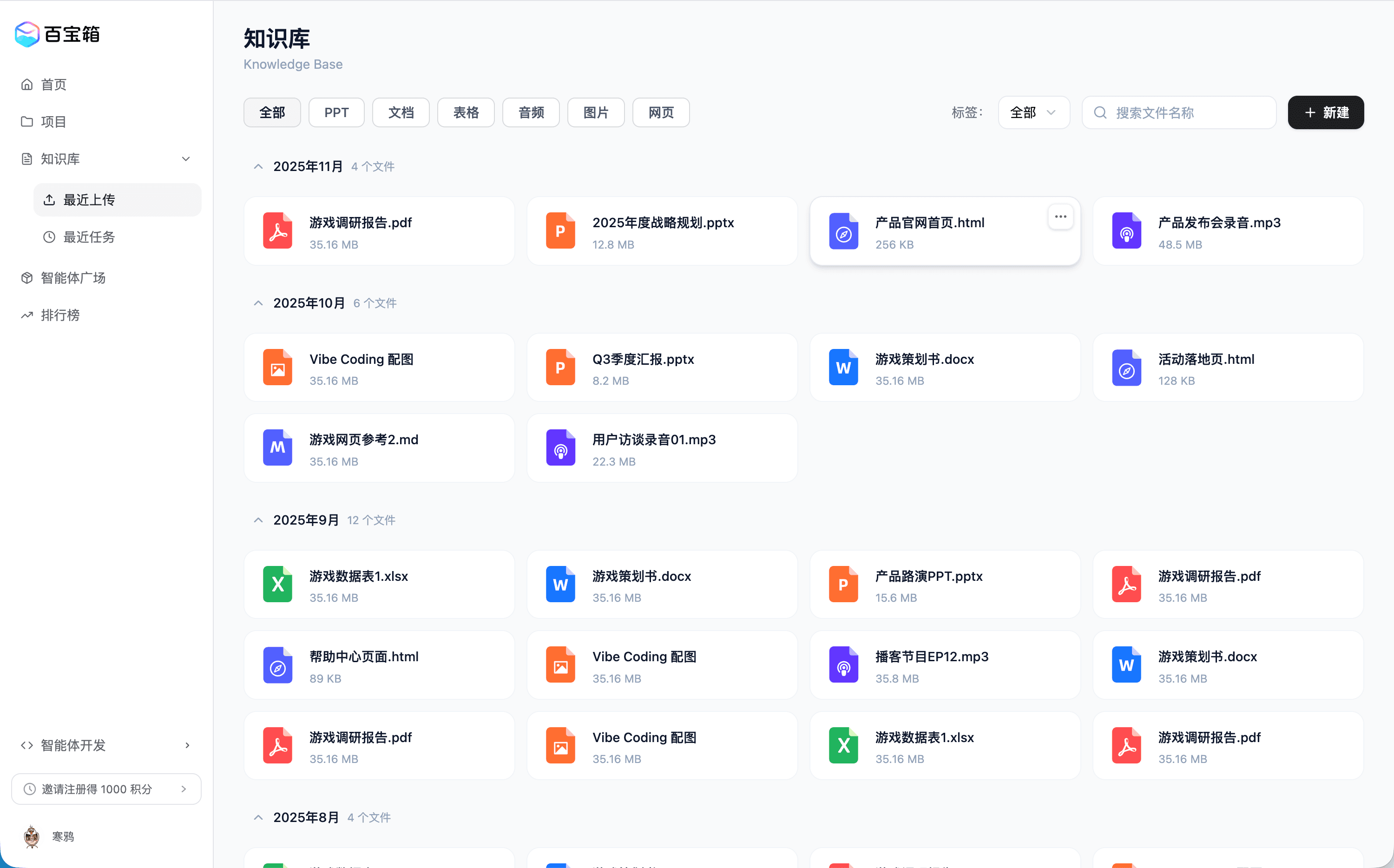
实战案例 2:百宝箱知识库 Demo
在咱们的日常工作中,能从 0 到 1 地开发一个新产品或新功能是少数,更多时候我们需要基于已有功能或页面进行迭代。此时会有一个严峻的问题摆在我们面前:
如何让模型精确地还原已有的功能设计?
接触过 Vibe Coding 的朋友们应该知道,让 LLM 准确还原设计稿,是一件非常困难的事。个人尝试过解决以下的方案来还原:
- 上传大量截图,仔细描述细节,经过多轮对话,接近理想细节(这仍然是目前最可行的方案)
- 上传前端代码,要求严格复刻(不可行)
- 使用 Claude Code 调用 Figma MCP 插件(还原相对准确,但要求使用 Figma 产出设计文件)
- 使用 Figma Make(Gemini 3 pro 版),上传少量截图,配合可视化编辑器还原
在这里,我会推荐大家使用 Figma make,Loveable,或者 Google AI Studio 的 APP 功能等在线的 Vibe Coding 工具,来实现准确的页面还原。
以下是一个我和 figma 按设计师的设计稿还原的知识库:
📖 百宝箱知识库设计 · Figma
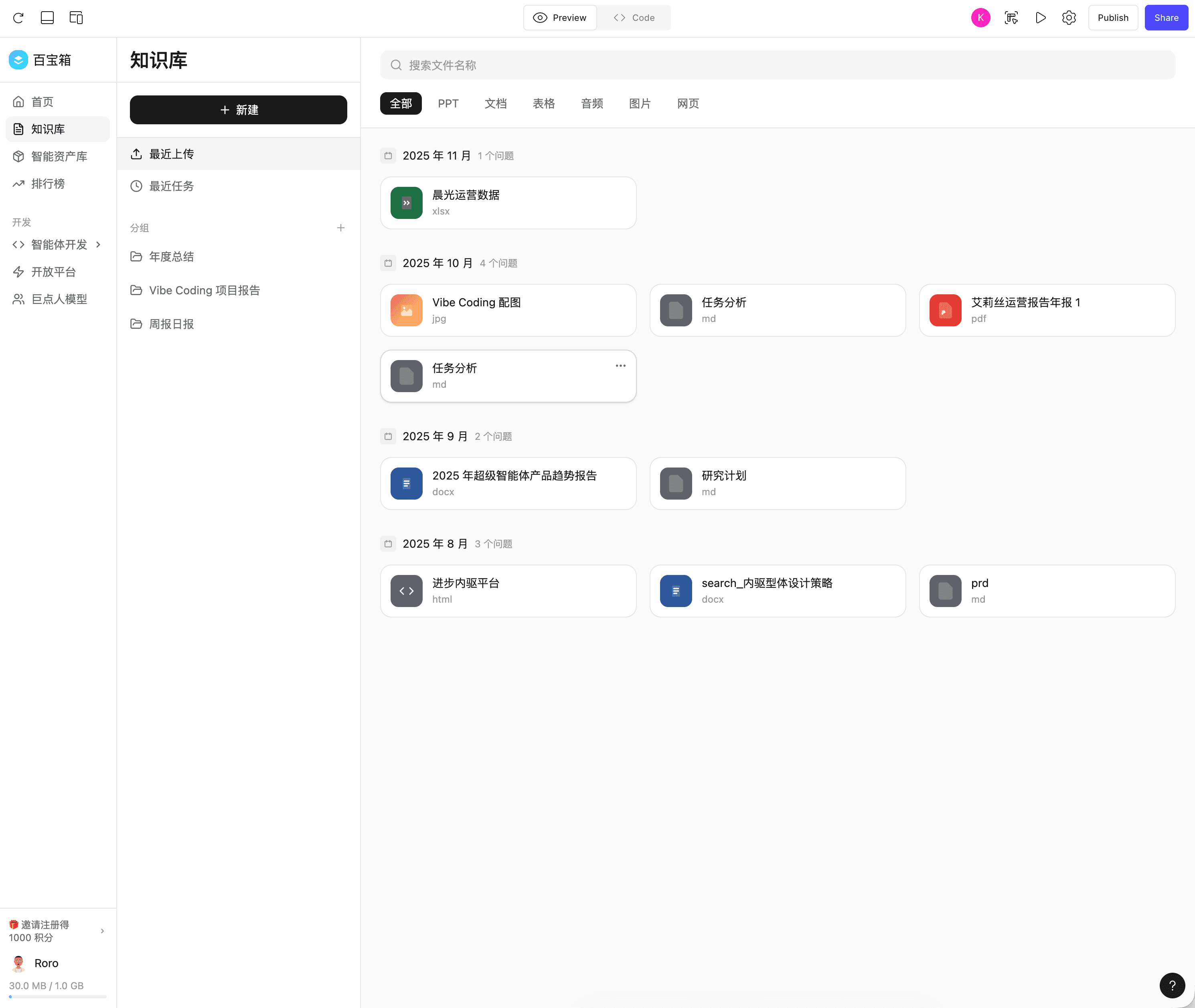
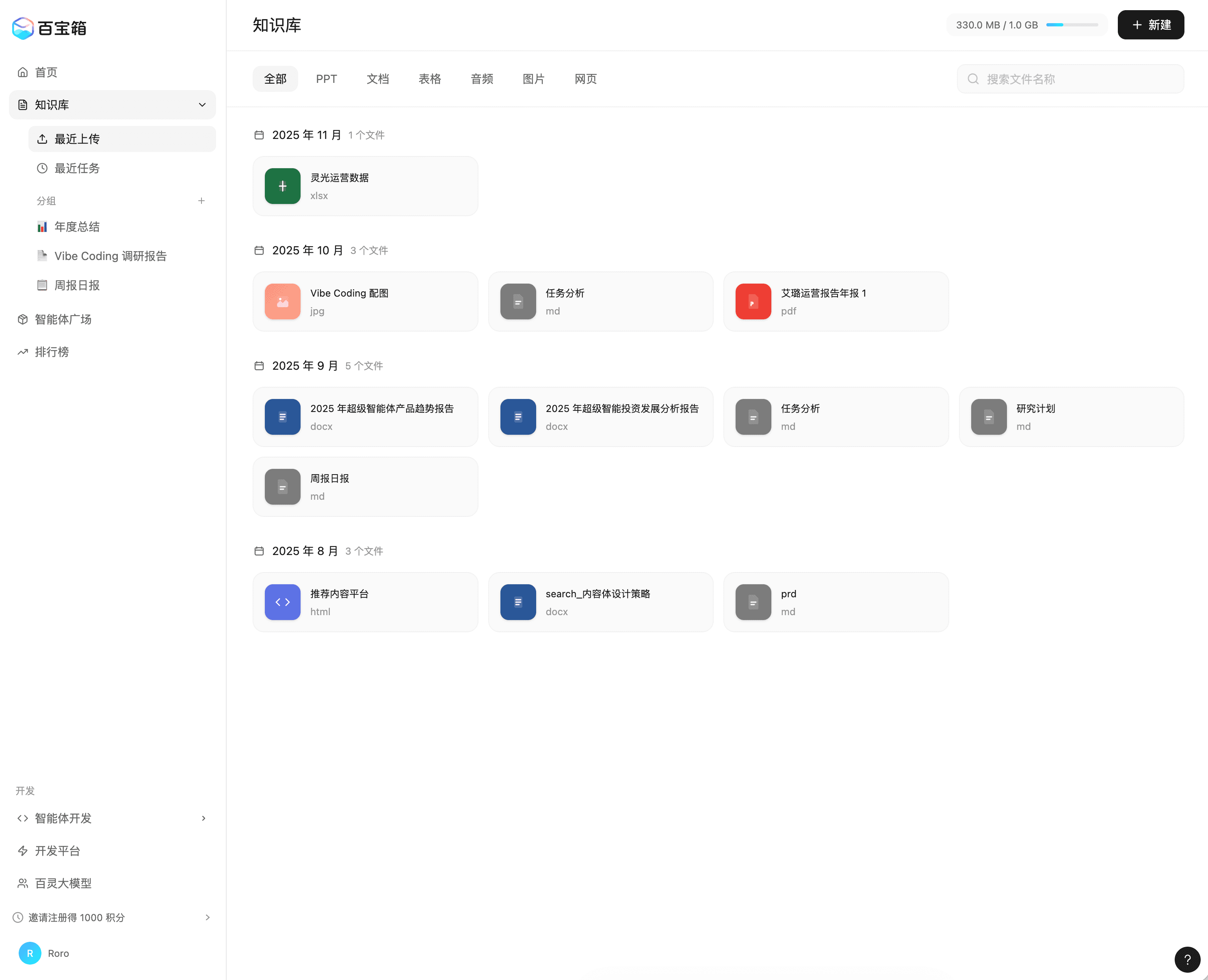
左图:版本 1,右图:版本 39
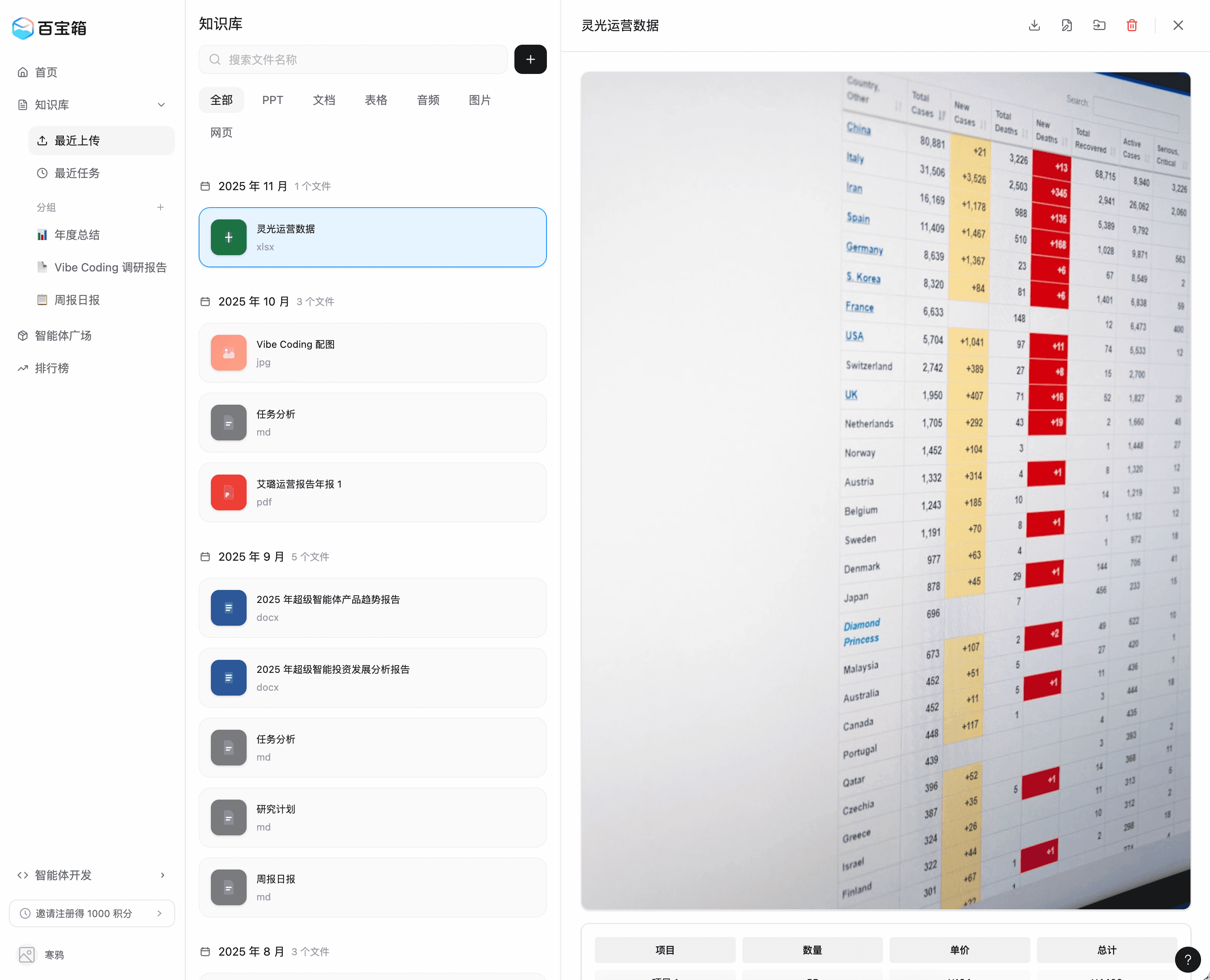
左图:版本 75,右图:版本 141
在此案例中,大家可看到:
- 页面大框架是对的,且已经基本实现了关键功能
- 可以配合可视化编辑器,进行精细调整
- 模型很聪明,基本不会碰伤不该被影响的区域,如果出现了危险动作,会和用户二次确认
- 缺点:用量太少
回顾 demo,其实大概是在第 35 轮开始,经过一番体验,我意识到了三栏模式不是一个好方案。快速调整了几个版本后,我拿最新的 demo 和团队小伙伴一起确认了下,新的方案应该是更好的方案。
后续就是不断地和模型调各处的细节样式,来来回回了 141 个回合,把订阅的用量打爆了,得到一个教训:从图片资源生成 UI 的时候可以用 Figma Make,并且调整到一个基本还原的状态,但后续的样式调整或者 UI 调整,还是下载到本地劳烦 Claude Code 吧 💦
实战案例 3:基于 Github Spec Kit 构建 Ling Studio 的管理后台
在介绍案例之前,先和大家对齐一下颗粒度:SDD(Spec Driven Development)。与这个快速发展领域中的许多新兴术语一样,“规范驱动开发”(SDD)的定义仍在不断变化。以下是我自行总结的定义:规范驱动开发是指在编写代码之前,先编写一份“规范”(可以理解为 PRD),然后再使用人工智能进行开发。规范将成为人类和人工智能的真理来源。
在这种研发模式里,产品迭代意味着我们需要不断地演进规范。自然语言组成的一系列文档,提升到了一个更高的层次,Vibe Coder 核心交付的是这些文档,而代码则是通过 AI 把文档翻译给机器以让其可被执行的解决方案。也就是说,规范是主要的源代码文件,随着时间的推移,只有规范会被人编辑,人永远不会触碰代码。
什么是 Spec
聊到这里大家可能会对什么是 Spec 似乎没有一个准确的定义,我所见过的最接近一致定义的是将规范比作“产品需求文档”。
Github Spec Kit
github/spec-kit: 💫 Toolkit to help you get started with Spec-Driven Development
虽然在概念层,大家只能达成一个模糊标准,但具体到工具上,各家是有很清晰的定义的,这个案例中,我们讲重点介绍 Github 自家的 spec kit,以下是它的定义:
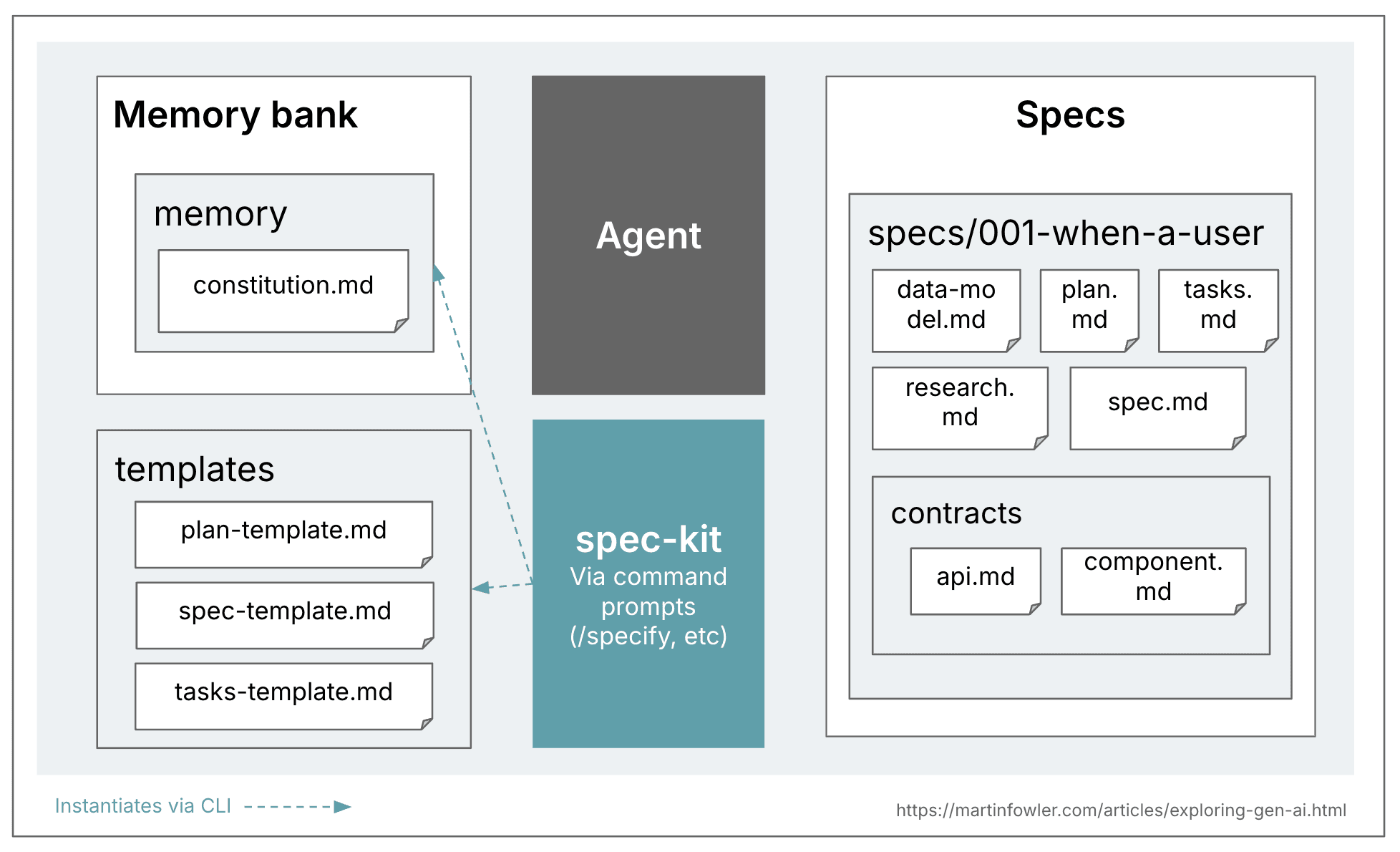
接下来我们将结合 Ling Studio 的实战案例,给大家展开介绍,首先是项目演示:
如何基于 Spec 一步步构建应用
传统研发模式:
原始需求获取(Deep Research Agent + Claude 辅助完善) -> 需求分析(需求分析智能体) -> 技术栈选型 -> 方案设计 (解决方案设计智能体) -> 原型图设计(手动画) -> 数据结构设计(大模型辅助) -> VibeCoding -> 前端微调(Vibe Coding) -> 前后端联调(Vibe Coding) -> 测试 -> 发布
SDD with Github Spce kit:
- 使用
/speckit.constitution定义项目的「宪法」:在这一步,我们需要明确项目的管理原则和开发指南,这些原则和指南将指导后续的所有后续开发。应用的每一次变更都会被要求遵循宪法。- 👉 Case:Ling Studio 的宪法
- 👉 每次提交记录都需要用中文来写
- 👉 Mock 内容需要使用中文,且遵循盘古之白
- 使用
/speckit.specify来描述你要构建的内容。重点在于 “是什么” 和 “为什么”,而不是技术栈。- 👉 Case:Ling Stuio 的规格定义
- 👉 每个 spec 的功能范围不宜过大
- 👉 以用户视角描述功能(User Story),用户旅程
- 👉 给出一些边缘 case(可选)
- 使用
/speckit.plan来提供技术栈和架构选择,制定实施计划。- 👉 Case:Ling Studio 的实施计划
- 👉 推荐框架:
- 前端框架:Next.js
- 前端组件:Shadcn/UI, Ant Design,前者大模型非常擅长,后者主要是考虑我们协作的上下游
- 后端语言:TypeScript、Python、Java
- 数据库、鉴权、存储等后端基建:Supabase
- 👉 在这一步,模型会进行联网搜索,找到一些好方案或者实现
- 👉 在这一步,可以同时输入数据结构设计(migration)给到模型
- 使用
/speckit.tasks从实施计划中创建可执行的任务列表- 👉 Case:Ling Studio 的任务列表
- 👉 务必仔细阅读 task.md,他是交付给模型 Coding 前的最后一环,如果方案有偏差,务必通过多轮对话完成调整。
- 使用
/speckit.implement执行所有任务- 👉 Case:Ling Studio 的执行记录
- 👉 模型不会一口气执行完所有任务,在执行过程中可以随时补充细节,更改需求,在改到满意了以后,务必让大模型按最新的方案更新 /spec 下的各个文档(多么痛的领悟)
- 👉 及时 Commit,及时 Commit,及时 Commit(多么痛的领悟)
- 及时验收,提交代码,合并分支,再起新分支做新迭代,无限进步
于我而言,这个模式的好处:
优点
- 流程通过工具规范化
- 能对“大”型项目进行有效拆解
- 对于不同复杂度的任务推荐的方式
- 简单 UI 调整:直接用嘴描述 or 手动调整
- 页面级别的重构 or 小功能的实现:plan mode
- 大功能 or 涉及前后端(或数据库)的大重构:spec-kit
- 对于不同复杂度的任务推荐的方式
- 工作留痕,有文档,能记录
不足之处:
缺点
- 对于简单地 UI 调整和功能调整,spce-kit 不会主动修改 spec.md 和 task.md 等关键文档,需要提醒
- 真的很耗 token
- 对于生产级系统、安全敏感、复杂架构,虽然 spec 看上去有所涉及,但不确定是否足够
- 只到了 Ant Code,但还没走到生产
最后强行升华的部分
