02: Token and Embedding: How Language Becomes Numbers

This is the second post in the “Understanding LLMs from First Principles” series. In the previous post, we looked at the first principle of LLMs: given the existing context, predict the next token. But what is a token? How does a model “see” language through tokens? Humans read characters, words, and sentences, while the model ultimately processes numbers. This post starts with token and embedding, opening the first conversion layer before language enters the model.
In the previous post, we said that a large language model repeats one basic operation:
Given the existing context, predict the next token.In the previous post, we used a rough definition: a token is the smallest indivisible content block from the model’s point of view. It may be a character, a word, punctuation, a code symbol, or another fragment of text.
When humans see the word “apple,” we may think of fruit, sweetness, the color red, the company Apple, Newton, a gift, or a specific personal memory. But a neural network cannot directly process the written word itself. A neural network performs mathematical computation, so its inputs and outputs must ultimately be numbers.
Before language can enter the model’s computation, text needs to be converted into numerical representations:
text
→ token
→ token id
→ embedding vectorFirst, continuous language is cut into discrete symbols from the model’s vocabulary. Then those symbols are mapped into vectors that the model can compute with.
This post explains “how the thing being predicted becomes computable.”
1. Why We Cannot Just Feed Sentences to a Model
Let’s think about neural networks in the plainest possible way.
Inside a model, there are matrix multiplications, additions, normalizations, and nonlinear transformations. No matter how conversational the outer product feels, the bottom layer is still numerical computation.
Natural language is not naturally numerical.
I like apples
我喜欢苹果
りんごが好きですThese sentences are close in meaning to a human reader, but inside a computer they start as different strings of characters. The model cannot directly process those strings, and it does not magically know how the characters relate to one another.
To make these characters computable, we need to turn them into numbers. Let’s start with the simplest possible idea: give each character or word fragment its own independent id, such as 我=01, 喜=02, 欢=03, I=06, like=07, and す=16.
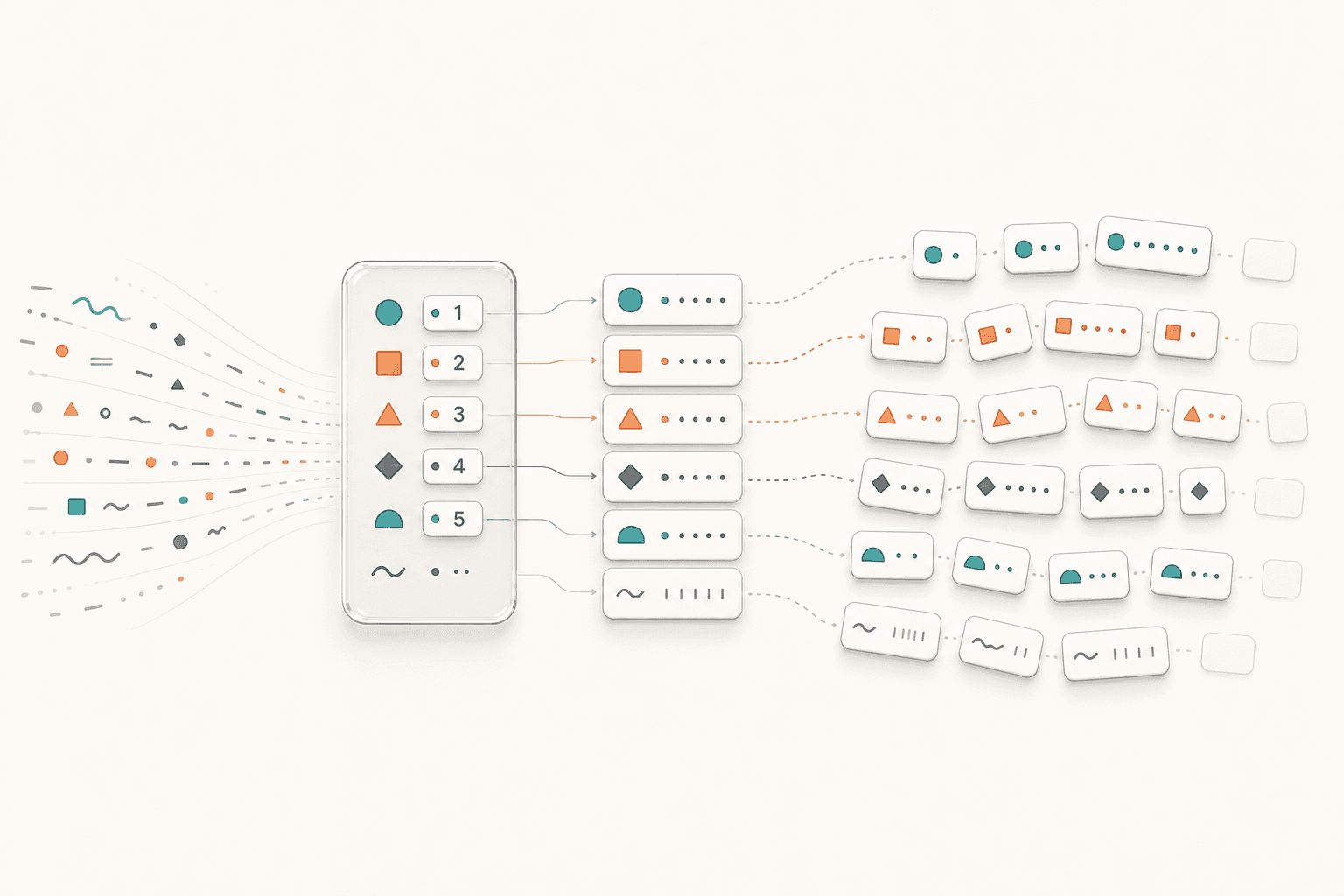
If we push this idea just a little further, we quickly run into problems:
One Chinese character is often not a complete semantic unit.
English words have prefixes, suffixes, and inflections.
Code contains brackets, indentation, variables, and operators.
New words, typos, emoji, and URLs may all appear.
Different languages do not have a natural one-to-one alignment.So we need a more reasonable conversion method: first split text into suitable content blocks, then map those content blocks to ids the model can continue processing. The block should be neither too coarse nor too fine.
We call the content blocks produced by splitting a sentence tokens. In other words, a token is one of the smallest stable content blocks cut from human language for the model to process. It is not necessarily a linguistic “word,” and it is not always a single character. It is more like a basic symbol in the model’s vocabulary.
So how is a sentence split into tokens?
2. Tokenizer: Cutting Continuous Language into Discrete Tokens
The component that cuts text into tokens is called a tokenizer.
Roughly speaking, it does this:
Take a piece of text
→ split it into tokens using a vocabulary and rules
→ map each token to an integer idFor example, this sentence:
I like applesmay be split like this:
I / like / applesThe Chinese sentence:
我喜欢苹果may be split like this:
我 / 喜欢 / 苹果or like this:
我 / 喜 / 欢 / 苹 / 果English words can also be split into pieces:
unbelievablemay become:
un / believableor:
un / believe / ableDifferent models use different tokenizers, so the exact split can differ. The reason is practical: vocabulary size, training data, supported languages, compression efficiency, and engineering constraints all shape tokenizer design.
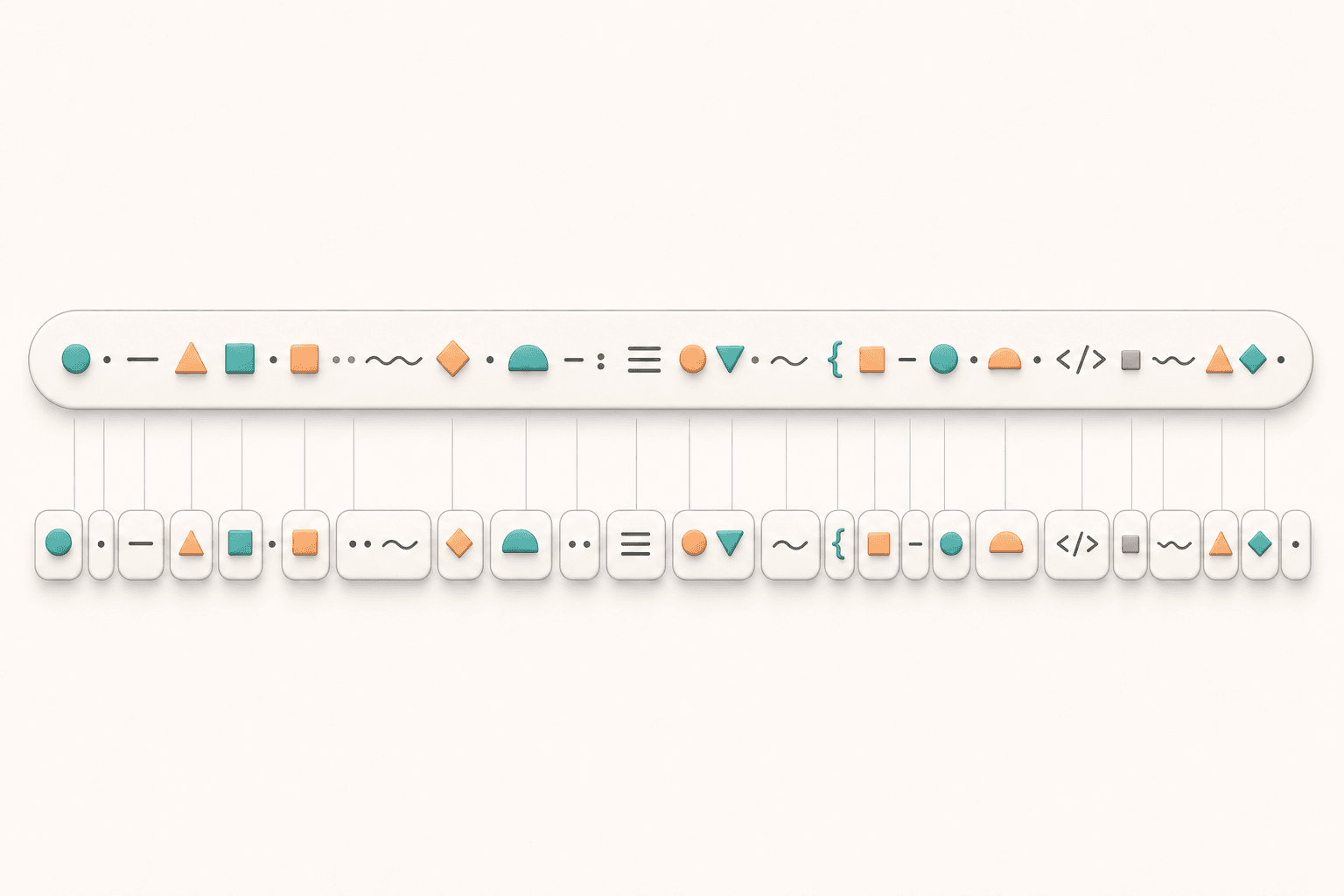
This explains several things you see when using LLMs.
First, the same meaning can consume different numbers of tokens across languages. Chinese, English, code, emoji, and special symbols are split differently, so they can occupy different amounts of context and cost.
Second, models may behave less predictably around rare words, typos, or unusual formats. Those strings may be split into many small fragments, forcing the model to recover meaning from smaller pieces.
Third, code ability is strongly affected by tokenization. Spaces, newlines, brackets, variable names, and operators all shape the token sequence the model sees.
Token is not a tiny implementation detail. It determines the resolution at which the model observes language.
3. Token Id: The Model Sees an Index Before It Sees Meaning
After tokens are produced, they still cannot directly enter the neural network. Each token is first mapped to an integer called a token id.
Imagine the vocabulary contains these mappings:
I → 103
like → 5821
apples → 9174Then:
I like applesmay become:
[103, 5821, 9174]There is one easy misunderstanding here:
A token id itself has no semantic meaning.The id 9174 is not “larger” or “more fruit-like” than 103. It is just an index in the vocabulary. An ID number can point to a person, but the number itself does not contain that person’s personality, history, or relationships.
If the model treated token ids as ordinary numbers, it would learn strange things. The fact that 9174 and 9175 are numerically close does not mean their meanings are close.
That is why the model needs the next step: mapping token ids into embeddings.
4. Embedding: Turning Discrete Symbols into Learnable Vectors
An embedding is a vector representation of a token in a high-dimensional space.
More concretely, the model contains a large table:
token id → embedding vectorIf a model’s embedding dimension is 4096, then every token id maps to a vector containing 4096 numbers.
103 → [0.12, -0.07, 0.31, ...]
5821 → [-0.44, 0.18, 0.09, ...]
9174 → [0.05, 0.62, -0.11, ...]These numbers are not handwritten by engineers, and they are not dictionary definitions. They are learned during training.
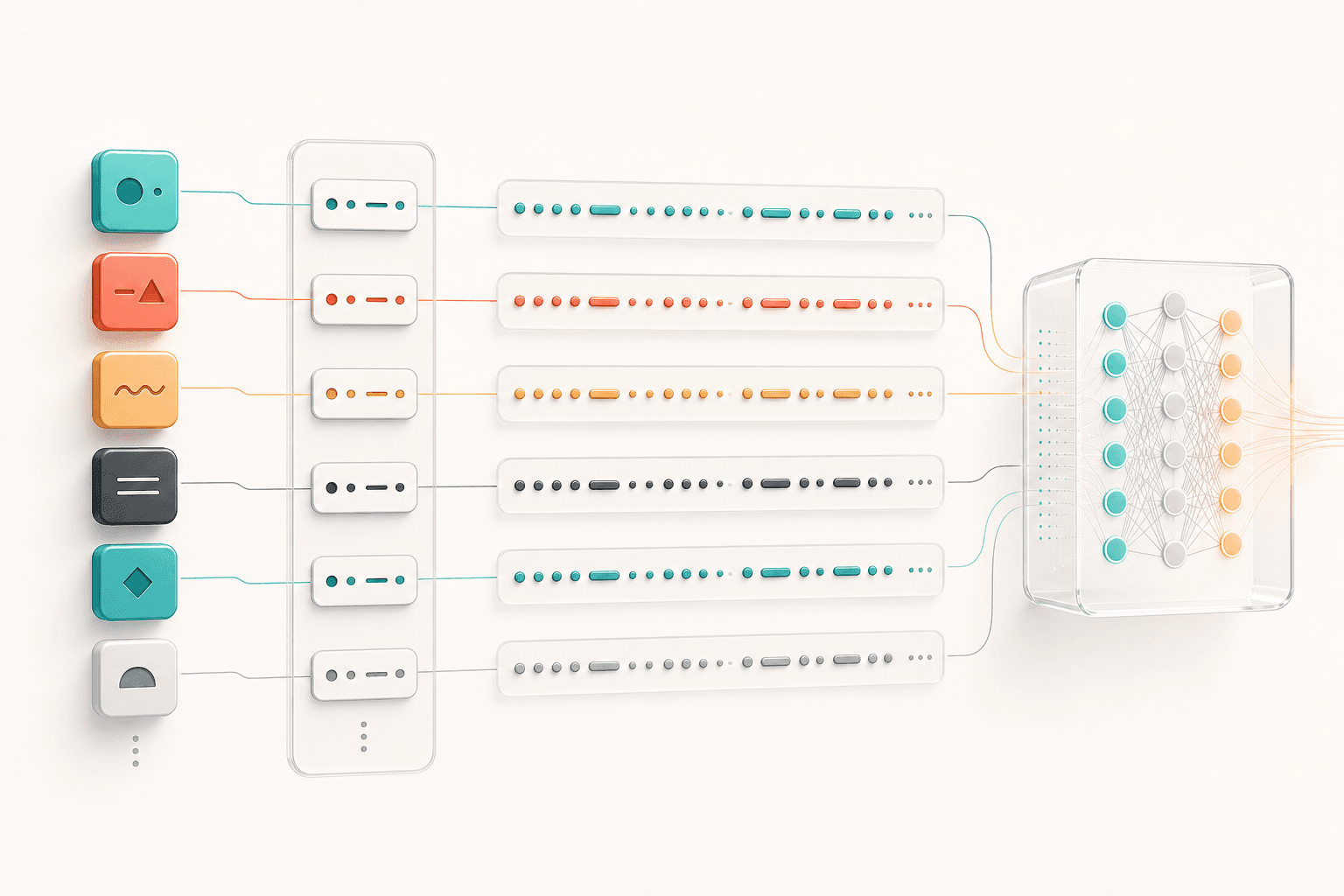
At the beginning, embeddings may be close to random numbers. The model repeatedly performs next-token prediction, repeatedly makes mistakes, and repeatedly updates its parameters. To predict better, it gradually adjusts tokens that appear in similar contexts toward representations that are useful for the task.
This “position” is not a coordinate on a two-dimensional map. It is a relationship inside a high-dimensional vector space.
A useful intuition is:
Tokens that appear in similar contexts tend to learn similar representations.
Expressions that can replace one another tend to move closer.
Tokens with different grammatical roles form different directions.
Code symbols, natural language, numbers, and punctuation also develop structure.This is the key value of embedding: it turns discrete symbols into points in a continuous space, so the model can compute similarity, difference, composition, and direction.
5. Embedding Is Not a Dictionary. It Is a Space of Relationships.
Many introductions describe embeddings as “meaning vectors.” That is helpful, but it can also mislead.
An embedding does not store a human-readable explanation of a word. It is more like a coordinate system of relationships learned for the prediction task.
During training, the model may gradually learn patterns like:
cat and dog often appear in similar contexts.
Paris and France have a capital-country relationship.
function and return often appear in code contexts.
because and therefore often connect causal structures.
question and answer often form a Q&A pattern.These relationships do not exist inside the embedding as sentences we can directly read. They are distributed across many dimensions and become useful together with the later Transformer layers.
In other words, an embedding is not a knowledge base, a dictionary, or a concept card.
It is closer to the model’s initial coordinate system:
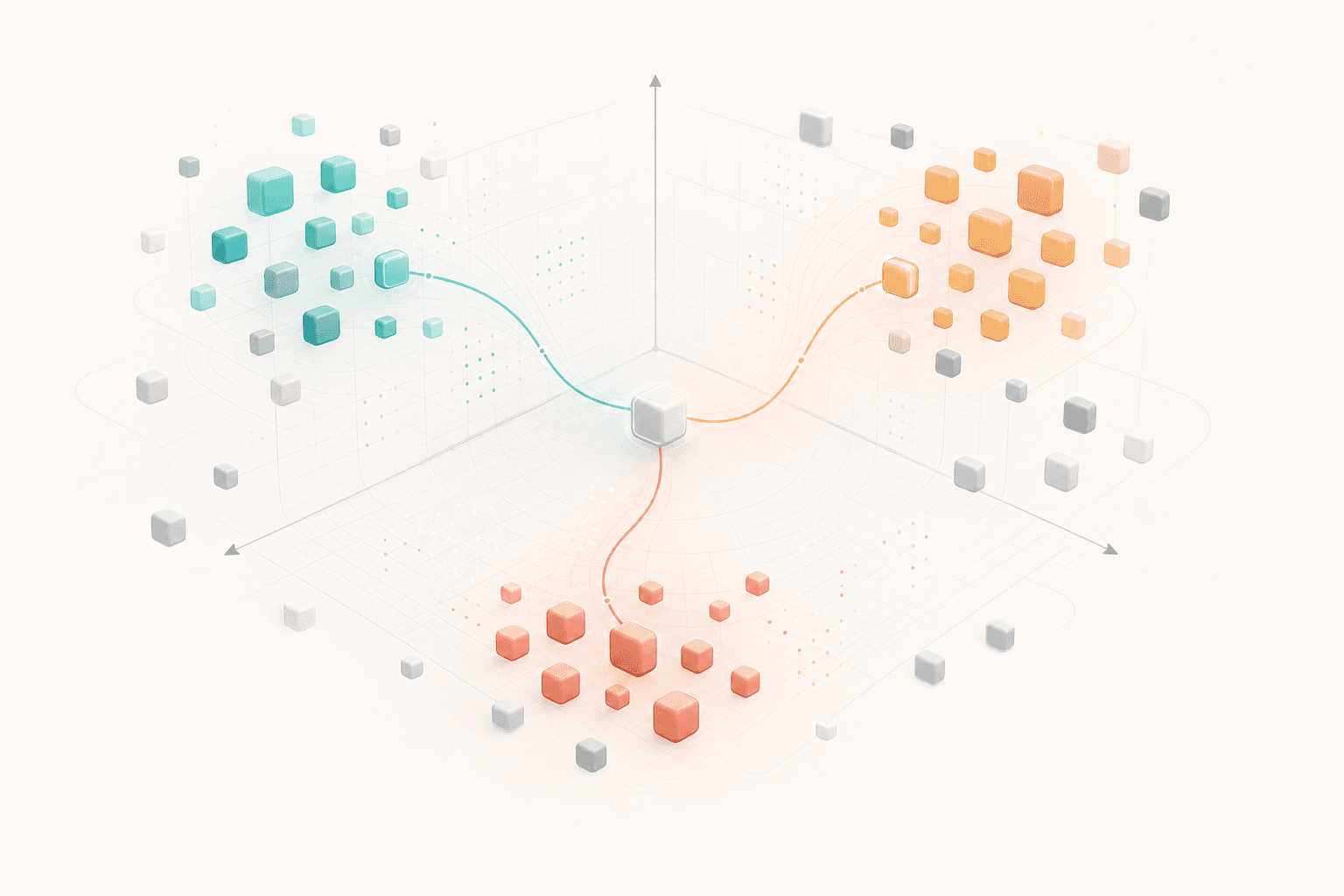
First put each token somewhere computable.
Then let later layers update those representations according to context.This also explains why the same token can mean different things in different sentences.
By itself:
applehas one initial embedding. But inside context:
I ate an apple today.
I bought a new Apple laptop.
Apple announced a new product.the model uses surrounding tokens to update the representation. By the time the token passes through the network, “apple” has different contextual representations in those three sentences.
So the more accurate picture is:
Embedding gives a token an initial representation.
The Transformer updates that representation using context.In the next post, when we discuss Transformer and Attention, we will continue this process.
6. Why Can Vectors Express Meaning?
There is an intuitive hurdle here:
How can a list of numbers express meaning?The answer is not “numbers naturally have semantics.” The answer is that the training objective forces those numbers to form useful structure.
If two tokens often appear in similar contexts, then to predict the next token well, the model tends to learn somewhat similar representations for them.
For example:
I have a cat. It likes to sleep.
I have a dog. It likes to walk.Across many sentences, “cat” and “dog” both appear in contexts about pets, actions, owners, food, and sounds. To predict such sentences, the model learns their similarities.
But it also learns their differences:
Cats meow.
Dogs bark.Similarity and difference together form the semantic space.
This is a little like how humans learn concepts through use. We do not understand every word by memorizing a dictionary definition first. We gradually build relationships across many situations. The difference is that the model has no body, no lived experience, and no subjective feeling. What it builds is statistical and task-oriented structure.
So we should not mystify embedding.
It is not “where the model’s soul lives.” It is simply a very effective mathematical representation: language enters a continuous space, and neural networks can compute over it.
7. Tokenization Shapes Product Experience
Once you understand tokens and embeddings, many product and engineering issues become easier to reason about.
1. Token Is the Unit of Cost
LLM APIs often price by token because model input and output are processed by token. A longer context means more input tokens. A longer answer means more output tokens.
This is not only a billing convention. It reflects the computation itself.
2. A Context Window Is Not a Word Limit
Context windows are usually measured in tokens, not words or characters.
So 1,000 characters can occupy different numbers of tokens depending on language, format, and content type.
This matters for long-document summarization, code analysis, PDF Q&A, and customer-service knowledge bases. You may think you are feeding the model “one article,” but the model sees “one token sequence.” Whether that sequence is too long, clearly structured, and positioned near the question affects the result.
3. Prompting Is Not Magic. It Is Input Distribution Design.
A good prompt is, in a very literal sense, a well-organized token sequence.
You are not shouting instructions at a person. You are giving context to a probabilistic model. Clear roles, goals, constraints, examples, and output formats make it easier for the model to map the current input to task patterns it has learned during training.
This is why:
Examples usually help.
Structured input usually helps.
Breaking requirements into steps usually helps.
Avoiding vague references usually helps.
Putting key information close to the question usually helps.The shared logic is simple: make the token sequence easier for the model to interpret and use.
4. Multilingual Quality Is Not Automatically Equal
Different languages can differ in training data, tokenizer behavior, corpus quality, and task distribution.
That means a model’s performance in a language depends on more than whether the model “supports” that language. It depends on how well that language has been learned inside the model’s representation space.
This is why bilingual products should not merely translate English prompts into another language. You also need to observe token cost, expression habits, terminology consistency, and output style.
8. Common Misconceptions
Misconception 1: A token is a word.
Not necessarily. A token may be a word, a character, part of a word, punctuation, whitespace, a code fragment, or a special symbol. It is a model-vocabulary unit, not a fixed linguistic unit.
Misconception 2: If two token ids are numerically close, their meanings are close.
No. A token id is just an index. Semantic relationships mainly live in embeddings and later contextual representations.
Misconception 3: Embeddings directly store knowledge.
Not quite. Embedding is the initial representation. Knowledge and capability are distributed across the model’s parameters and computation. Embedding is the entrance, not the whole building.
Misconception 4: The model first translates the whole sentence into meaning, then answers.
No. The model first cuts text into tokens, maps them into vectors, computes contextual representations through layers, and finally predicts the next token step by step.
9. Returning to the Question: How Language Becomes Numbers
We can now compress the whole flow into one chain:
text
→ tokenizer splits it into tokens
→ tokens map to token ids
→ token ids look up embeddings
→ embeddings enter the Transformer
→ the Transformer updates representations using context
→ the model outputs a probability distribution over the next tokenIn this chain, token solves the problem of discretizing language. Embedding solves the problem of bringing discrete symbols into continuous computation.
Compressed into one sentence:
Tokens cut language into symbols the model can enumerate; embeddings place those symbols into a high-dimensional space the model can compute over.
Once this is clear, many later ideas get a foundation.
Why can models handle similar expressions? Because embeddings and later layers can learn relationships across contexts.
Why does context matter so much? Because an initial token representation is repeatedly rewritten by its surrounding context.
Why does prompt structure affect output? Because you are not giving the model pure intent; you are giving it a token sequence that changes the probability distribution.
Why is the next post about Transformer and Attention? Because token and embedding are only the entrance. The mechanism that lets a model “see” relationships across context is attention inside the Transformer.
Next, we will open that layer: how do Transformer and Attention let the model decide which parts of the context to reference when generating the current token?