02:Token 与 Embedding:语言如何变成模型能处理的数字
这是「用第一性原理理解大模型」系列的第 2 篇。上一篇我们讲了大模型的第一性原理:根据已有上下文,预测下一个 token。但 token 是什么?模型是怎么通过 token「看见」语言?人类阅读的载体是字、词和句子,它们如何被转换成模型能处理的数字。本文就从 token 和 embedding 开始,拆开语言进入模型之前发生的第一层转换。
上一篇我们说,大模型每一步都在做一件事:
根据已有上下文,预测下一个 token。我们把 token 先粗略理解为是「模型眼里不可分割的最小内容块」。它可能是一个字、一个词,也可能是标点、代码符号或别的字符片段。
但为什么好好的文字,需要把它变成 token 呢?
人类看到「苹果」两个字,会联想到水果、红色、甜味、手机公司、牛顿、礼物,甚至某一次具体的记忆。但大模型的神经网络不能直接处理「苹果」这个文字本身。神经网络做的是数学计算,它只能接收和输出数字。
为了让文字变成可被模型神经网络计算的数字,在进入模型之前,我们需要把它进行切分并进行编码,变成可被进行数学计算的 token,通常来说,需要经历以下转换:
文字 → token → token id → embedding 向量首先,把连续语言切成模型词表里的离散符号;然后,把这些符号变成模型能计算的向量。
本篇内容,将带大家一起了解文字在进入模型前都要做哪些准备工作,了解「被预测的东西,如何变成可计算对象」。
一、为什么不能直接把句子丢给模型
让我们把大模型的神经网络掰开来看,模型内部由很多矩阵乘法、加法、归一化和非线性变换。无论它外面包装得多像一个聊天对象,其底层逻辑依然是数字运算。
但自然语言不是天然的数字。
我喜欢苹果
I like apples
りんごが好きです这些句子对人来说表达了相近意思,但在计算机里,它们最开始只是不同字符组成的文本。模型不能直接处理这些文本,也不能凭空知道这些字符之间有什么关系。
为了让这些字符变得可被「计算」,我们需要把字符变成数字。我们先试试采用最简单的办法 —— 直接给每个字符或词片段进行独立编号,比如:我=01,喜=02,欢=03,苹=04,果=05。
稍微推演下,会发现这么编号,会遇到很多问题:
中文单字常常不是完整语义单位;
英文单词有词形变化和前后缀;
代码里有括号、缩进、变量名和运算符;
新词、错别字、emoji、URL 都可能出现;
不同语言之间没有天然对齐关系。因此我们需要一套更合理的转换方法:先把文本切成合适的内容块,再把这些内容块映射成模型能继续处理的编号。这个内容块既不能太粗,也不能太细。
我们把句子经过切割后出来的一串串「内容块」称作 token。换言之,token 是由人类语言切成的模型可以稳定处理的最小内容块。它不是语言学里的「词」,也不是固定意义上的「字」。它更像是模型词表里的一个基本符号单元。
具体来说,句子是如何被切割成 token 的呢?
二、Tokenizer:把连续语言切成离散 token
负责把句子切分成 token 的组件叫 tokenizer,也常被翻译成「分词器」。不过这里的「分词」不要理解成 jieba 那种按中文词语做语言学分词;主流 tokenizer 往往基于字节、字符或子词片段,有时会把相邻汉字合并成一个 token,有时也会拆得更细。
它做的事情可以粗略理解为:
输入一段文本 → 按照词表和切分规则拆成 token → 把每个 token 映射成一个整数编号比如这句话:
我喜欢苹果可能被切成:
我 / 喜欢 / 苹果也可能被切成:
我 / 喜 / 欢 / 苹 / 果英文也一样:
unbelievable可能不是一个完整 token,而是:
un / believable或:
un / believe / able不同模型使用的 tokenizer 不同,切法也不完全一样。tokenizer 需要根据模型自身特点来设计:词表大小、训练语料、支持语言、压缩效率和工程成本都会影响 tokenizer 的设计。
这也解释了很多使用大模型时的现象:
- 同样一句话,在不同语言里消耗的 token 数可能不同。中文、英文、代码、emoji、特殊符号的切分方式不同,所以计费和上下文占用也会不同
- 模型对某些罕见词、拼写错误、特殊格式可能表现不稳定。因为这些内容可能被拆得很碎,模型要在更细的符号片段上恢复意义
- 代码能力和 tokenizer 关系很大。代码里的空格、换行、括号、变量名、操作符,都会影响模型看到的 token 序列
所以 token 不是一个无关紧要的技术细节。它决定了模型观察语言的分辨率。
三、Token id:模型先看到的是编号,不是意义
token 被切出来以后,还不能直接进入神经网络。它会先被映射成一个整数编号,也就是 token id。
假设词表里有这些映射:
我 → 103
喜欢 → 5821
苹果 → 9174那么:
我喜欢苹果进入模型前可能会变成:
[103, 5821, 9174]到这里,有一个很容易误解的地方:
token id 本身没有语义。编号 9174 并不比编号 103「更大」或「更接近水果」。它只是词表里的一个索引。就像酒店房间号能指向一个房间,但房间号本身不包含这个房间里的家具、住客和关系。
如果模型只拿到这些整数,并把它们当普通数字计算,就会出问题。因为 9174 和 9175 的数值接近,并不代表它们的意义接近。
所以模型还需要下一步:把 token id 映射到 embedding。
四、Embedding:把离散符号变成可学习的向量
embedding 可以理解成每个 token 在高维空间里的一个向量表示。
更具体一点,模型内部有一张很大的表:
token id → embedding 向量假设一个模型的 embedding 维度是 4096,那么每个 token id 都会对应一个包含 4096 个数字的向量。
103 → [0.12, -0.07, 0.31, ...]
5821 → [-0.44, 0.18, 0.09, ...]
9174 → [0.05, 0.62, -0.11, ...]这些数字不是人手写进去的,也不是词典定义。它们是在训练过程中学出来的。
一开始,embedding 可能只是随机数字。模型不断做 next token prediction,不断犯错、更新参数。为了更好地预测,模型会逐渐把经常出现在相似语境里的 token 调整到某种「更有用」的位置上。
这里的「位置」不是二维地图上的坐标,而是高维向量空间里的关系。
你可以先建立一个直觉:
相似语境中的 token,会学到相似的表示;
经常互相替换的表达,会靠得更近;
承担不同语法角色的 token,会形成不同方向;
代码符号、自然语言、数字和标点,也会各自形成结构。这就是 embedding 的关键价值:它把离散符号变成连续空间中的点,让模型可以计算「相似」「差异」「组合」「方向」。
五、Embedding 不是词典,而是关系空间
很多介绍会说 embedding 是「词义向量」。这个说法有帮助,但也容易让人误会。
embedding 不是把一个词的中文解释塞进向量里。它更像是一套为了预测任务而学出来的关系坐标。
比如,模型可能会在训练中逐渐学到:
猫 和 狗 经常出现在类似语境里;
巴黎 和 法国 有首都与国家的关系;
function 和 return 经常出现在代码上下文里;
因为 和 所以 常常连接因果结构;
question 和 answer 常常构成问答关系。这些关系不会以人能直接读懂的句子存在于 embedding 里。它们分散在很多维度上,和后续 Transformer 层里的计算一起发挥作用。
也就是说,embedding 不是知识库,不是词典,也不是概念卡片。
它更像是模型开始思考之前的「初始坐标系」:
先把每个 token 放到一个可计算的位置上,
再让后面的网络层根据上下文不断更新这些表示。这也解释了为什么相同 token 在不同句子里可以有不同含义。
单独看:
苹果它的初始 embedding 是固定的。但进入上下文以后:
我今天吃了一个苹果。
我买了一台苹果电脑。
苹果公司发布了新产品。模型会根据周围 token,不断更新这个位置上的表示。最后,「苹果」在不同句子里的上下文表示就不一样。
所以更准确地说:
embedding 给 token 一个初始表示;
Transformer 根据上下文,把初始表示更新成上下文表示。下一篇我们讲 Transformer 和 Attention 时,就会继续拆这个过程。
六、为什么向量能表达语义
这里可能会有一个直觉上的坎:
一串数字,为什么能表达意思?答案不是「数字天生有语义」,而是「训练目标迫使这些数字形成有用的结构」。
如果两个 token 经常在相似上下文里出现,那么为了更好地预测下一个 token,模型会倾向于给它们学出某种相似表示。
比如:
我养了一只猫,它喜欢睡觉。
我养了一只狗,它喜欢散步。在很多句子里,「猫」和「狗」都可能出现在宠物、动作、主人、食物、叫声等上下文中。模型为了预测这些句子,会学到它们之间的相似性。
但它也会学到差异:
猫会喵喵叫。
狗会汪汪叫。相似性和差异性一起构成了语义空间。
这和人类学习概念有一点像:我们不是通过背诵一个词典定义来理解所有词,而是在大量使用场景中逐渐建立关系。区别在于,模型没有身体经验,也没有主观体验;它建立的是统计关系和任务关系。
所以,不要把 embedding 神秘化。
它不是「模型的灵魂所在」。它只是一个非常有效的数学表示方式:让语言可以进入连续空间,让神经网络可以对语言做计算。
七、Tokenization 会影响产品体验
理解 token 和 embedding 以后,很多产品和工程问题会变得更清楚。
1. Token 是成本单位
大模型 API 常按 token 计费,是因为模型的输入和输出都以 token 为单位处理。你的上下文越长,输入 token 越多;模型回答越长,输出 token 越多。
这不仅仅是商业计价口径,也是模型运算方式本身。
2. 上下文窗口不是「字数窗口」
上下文窗口通常按 token 计算,而不是按字数或字符数计算。
所以同样是 1,000 个字符,不同语言、格式和内容类型可能占用不同 token 数。
这对长文总结、代码分析、PDF 问答、客服知识库都很重要。你以为塞进去的是「一篇文章」,模型看到的是「一串 token」。这串 token 是否过长、是否结构清晰、关键信息是否靠近问题,都会影响效果。
3. 提示词不是玄学,是输入分布设计
好的 prompt,本质上是在组织 token 序列。
你不是在对一个人喊话,而是在给概率模型提供上下文。清晰的角色、目标、约束、示例和输出格式,会让模型更容易把当前输入映射到它训练中见过的任务模式。
这就是为什么:
给示例通常有效;
结构化输入通常有效;
把需求拆开通常有效;
少用含糊指代通常有效;
关键信息放在靠近问题的位置通常有效。这些技巧背后的共同逻辑是:让 token 序列更容易被模型解释和利用。
4. 多语言体验不是自动均等的
不同语言在训练数据、tokenizer 切分、语料质量和任务分布上都可能不同。
这意味着模型在不同语言上的表现,不只取决于「是否支持这门语言」,还取决于这门语言在模型训练和表示空间里被学到了什么程度。
这也是为什么做双语产品时,不能只把英文 prompt 翻译成中文。你还要观察中文输入的 token 成本、表达习惯、术语一致性和输出风格。
八、常见误解
误解一:token 就是词。
不完全是。token 可能是词、字、词的一部分、标点、空格、代码片段或特殊符号。它是模型词表里的单位,不是自然语言里的固定单位。
误解二:token id 越接近,语义越接近。
不是。token id 只是索引。语义关系主要体现在 embedding 和后续上下文表示里。
误解三:embedding 里直接存着知识。
也不准确。embedding 是初始表示,知识和能力分布在整个模型参数和计算过程里。它是入口,不是全部。
误解四:模型先把整句话翻译成意思,再开始回答。
不是。模型先把文本切成 token,映射成向量,再经过层层计算得到上下文表示,最后逐 token 预测输出。
九、总结:语言如何变成模型能处理的数字
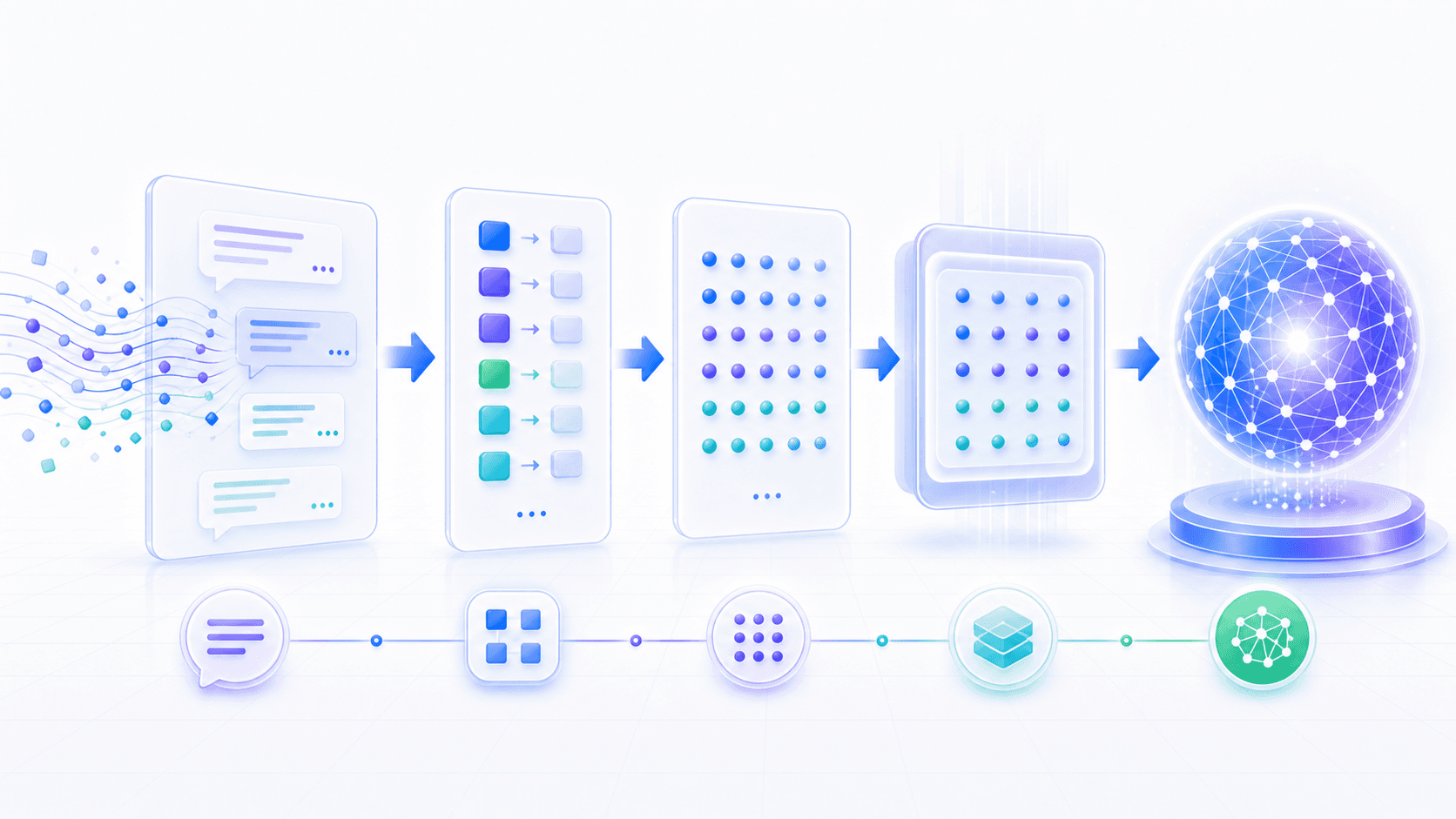
现在我们可以把整个过程压缩成一条链路:
文本
→ tokenizer 切分成 token
→ token 映射成 token id
→ token id 查表得到 embedding
→ embedding 进入 Transformer
→ Transformer 根据上下文更新表示
→ 模型输出下一个 token 的概率分布这条链里,token 解决的是「语言如何离散化」的问题;embedding 解决的是「离散符号如何进入连续计算」的问题。
如果再压缩成一句话:
Token 把语言切成模型能枚举的符号,embedding 把这些符号放进模型能计算的高维空间。
理解了这一点,后面的很多内容就有了地基。
为什么模型能处理相似表达?因为 embedding 和后续网络层能学习语境中的关系。
为什么上下文这么重要?因为初始 token 表示会被上下文不断重写。
为什么 prompt 结构会影响输出?因为你给模型的不是意图本身,而是一串会改变概率分布的 token。
为什么下一篇要讲 Transformer 和 Attention?因为 token 和 embedding 只是入口。真正让模型「看见上下文关系」的,是后面层层计算中的注意力机制。
十、技术附录:为什么 token id 不能直接表示语义
token id 看起来是数字,但它更像词表里的座位号。
token: 苹果
token id: 12345
embedding: [0.12, -0.03, 0.87, ...]真正进入神经网络连续计算的,不是 12345 这个编号本身,而是通过 embedding table 查到的一整组向量。编号相邻的两个 token,不代表语义相近;语义相近通常体现为 embedding 和后续上下文表示在高维空间里的关系相近。
所以,token id 解决的是「怎么索引词表」;embedding 解决的是「怎么让符号进入可学习的关系空间」。
十一、你应该能回答的三个问题
读完这一篇,可以试着用自己的话回答:
- token、token id 和 embedding 分别解决什么问题?
- 为什么 token id 是索引,而不是语义本身?
- 为什么同一句话在不同语言或不同 tokenizer 下,成本和表现可能不同?
下一篇,我们继续往下拆:Transformer 和 Attention 到底如何让模型在生成当前 token 时,知道应该参考上下文里的哪些信息。