03: Transformer and Attention: How Models “See” Context
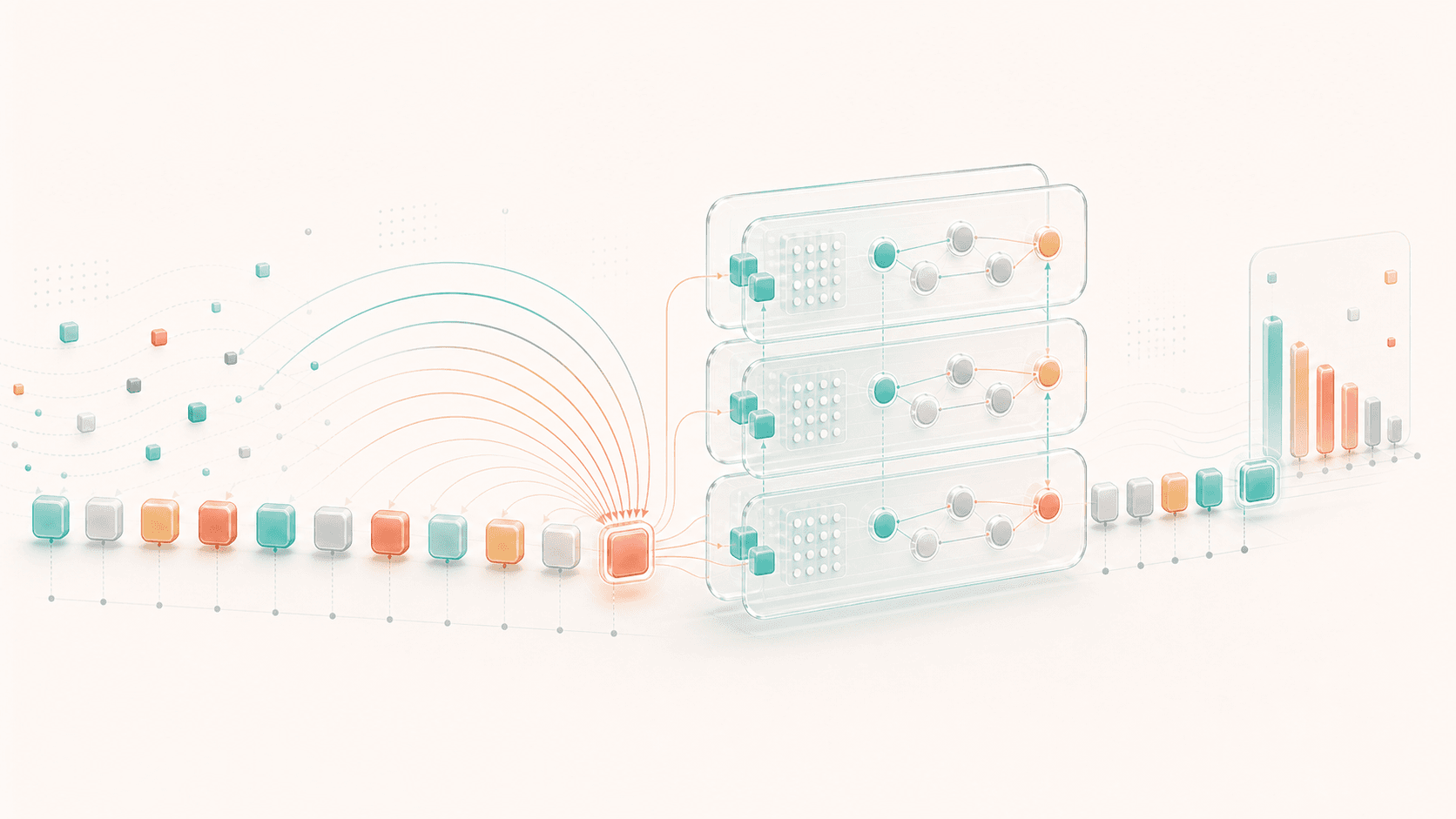
This is the third post in the “Understanding LLMs from First Principles” series. In the previous post, we looked at tokens, token ids, and embeddings: language is split into tokens, then mapped into vectors that a model can compute with. But those vectors start as isolated initial representations. What lets a model understand which words relate to which words, which part of the prompt matters right now, and how the current question connects to earlier context is Transformer and Attention. This post opens that box: how does a model “see” context?
At the end of the previous post, we had this chain:
Text
→ token
→ token id
→ embedding vector
→ Transformer
→ probability distribution over the next tokenNow comes the next question:
If embeddings already turn tokens into vectors,
why do we still need a Transformer?Because the meaning of a token often does not live inside the token alone. It lives in its relationship with the surrounding context.
Look at these three sentences:
I ate an apple.
I bought an Apple laptop.
Apple announced a new product.The string “Apple” is similar, but the meaning changes. The token’s initial embedding can only provide a starting point. The actual meaning has to be rewritten by the surrounding context.
Here is a more typical example:
Ming put the backpack on the chair because it was too heavy.What does “it” refer to?
Most people would say the backpack, not the chair, because “too heavy” is more likely to describe the backpack.
When humans read this sentence, we naturally connect “it,” “backpack,” and “too heavy.” The model has to do something structurally similar: inside a sequence of tokens, it needs to discover which tokens relate to which other tokens, then use those relationships to update each token’s representation.
That is the problem Transformer is built to solve:
Given a sequence of token vectors, how can they use context to become new vectors that fit that context better?
1. A Model Builds Understanding by Merging Context
Start with one idea: after a sentence enters the model, the model cannot read its intended “meaning” all at once.
At the start, the sentence is split into tokens, and each token carries an initial vector. This initial vector only represents the token itself. It has not yet formed relationships with the surrounding context.
Paris / is / the / capital / of / France / . / It / is / known / for / the / Eiffel / TowerAt the beginning, the vector for “It” only knows that it is a pronoun. It does not yet know what it refers to.
This context-connection problem is exactly what Transformer is trying to solve. It does not collapse the whole sentence into one blob and produce a single overall meaning. Instead, it lets every position repeatedly ask:
To understand this position,
which earlier or later tokens should I pull information from?So the “It” position can absorb information from positions like “Paris,” “France,” and “capital.” After several Transformer layers, the vector at the “It” position is no longer just an isolated pronoun vector. It now carries contextual information that says, in effect, “this probably refers to Paris.”
In other words, the model is not working with a fixed list of “word meanings.” It is working with vectors at each token position, and those vectors absorb more context layer by layer:
early layers: each position captures some local relationships;
middle layers: positions exchange more information;
deeper layers: each position carries richer context;
final state: the model uses these contextual states to predict the next token.The same thing happens in code. For example:
function add(a, b) {
return a +To predict the next token, the current position cannot only notice that return and a + appeared before it. It also needs to know that the function parameters included b, and bring that information into the current generation position. The important relationship crosses several tokens.
Without this contextual updating, the model would only see isolated symbols. With Transformer, each position gradually carries information about how it relates to other positions in the context.
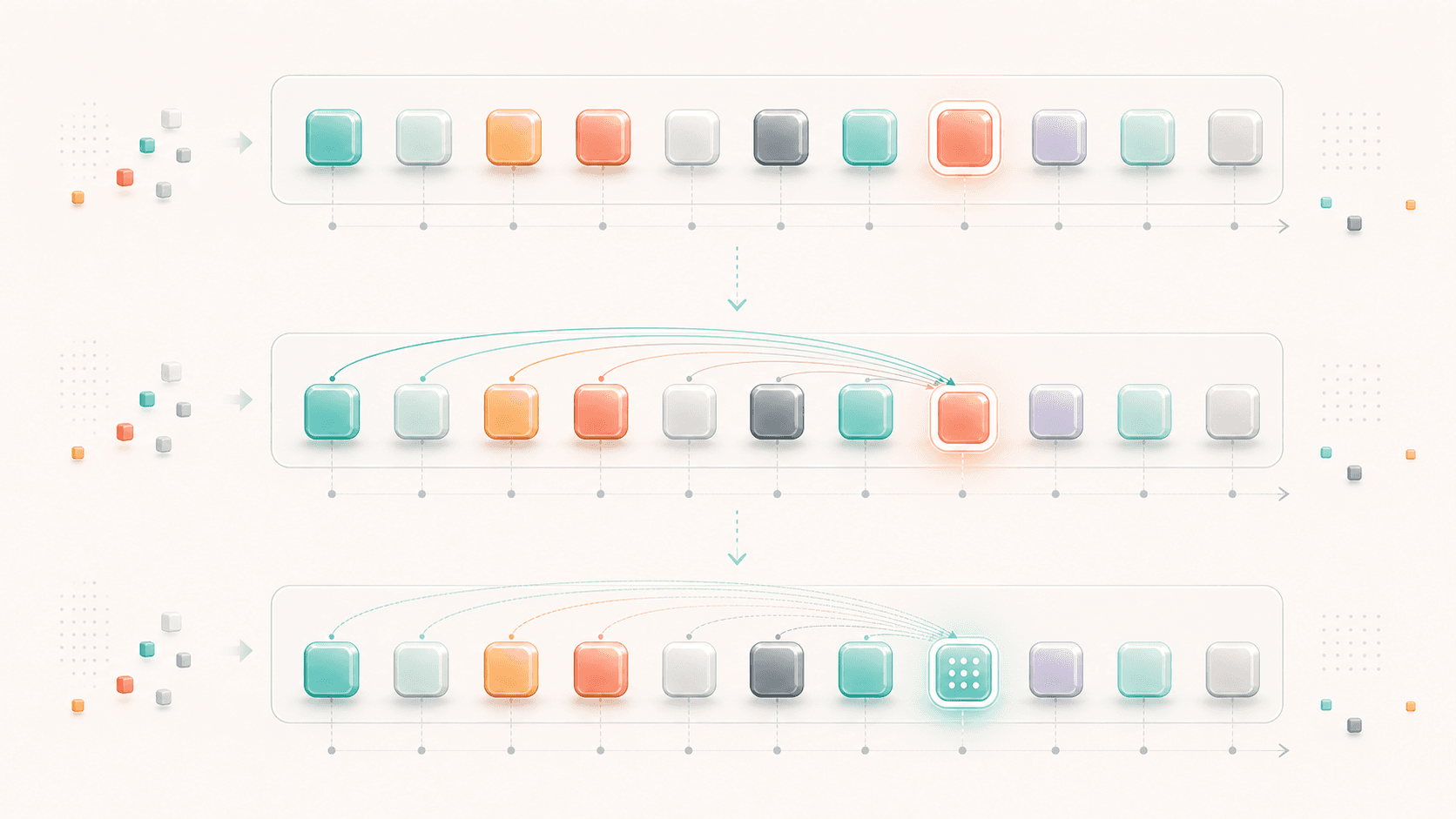
2. The Core Question of Attention: Where Should This Token Look?
The most famous mechanism inside Transformer is Attention.
The name can be misleading, as if the model were consciously focusing like a person. More precisely, Attention is a computation method that answers one question:
When updating the representation of the current token,
which tokens in the context should it pull information from?
And how much information should it take from each one?You can think of it as a dynamic reference system.
When the model processes the token “it,” it may find something like:
backpack: highly relevant
chair: somewhat relevant
too heavy: highly relevant
Ming: weakly relevantSo the new representation of “it” absorbs more information from “backpack” and “too heavy.”
This is not a hand-written rule. No engineer tells the model, “When you see ‘too heavy,’ point the pronoun to the movable object before it.” The model learns, through large-scale next-token prediction, which contextual relationships are useful for prediction.
That is the core value of Attention:
At every layer, each token can choose again which positions in the context it should reference.
This is one reason large language models can handle:
pronoun references in long sentences;
variable references in code;
constraints across a multi-turn conversation;
argument flow in an article;
the previous step in a mathematical derivation;
format requirements inside a user prompt.Underneath all of these abilities is the same need: the model has to build relationships inside context.
3. Self-Attention: Finding References Inside the Same Context
When people talk about Attention in large language models, they usually mean self-attention.
The “self” part is not mysterious. It means the information being referenced comes from the current token sequence itself, not from another text, an external database, or a separate memory area.
More technically, the Query, Key, and Value vectors are all computed from the same token sequence. That is why it is called self-attention.
Suppose the input is:
I / like / red / applesIn self-attention, when the model updates the vector at a position, it looks for useful reference points inside the same context.
For a generative language model, it usually cannot peek at future tokens. To predict the next token, the current position mainly references tokens that have already appeared.
So each position is closer to asking:
To update myself,
which already-seen positions in this context are most useful?For example:
the "apples" position may strongly reference "red" and "like";
the "red" position may reference "like" and "I";
the "like" position may reference "I";
when generating the next token, the model references the state built from the whole previous context.After this step, each token representation is no longer just its initial embedding. It now contains contextual information from related tokens.

This is why the same word can mean different things in different sentences. Transformer does not only look at the word itself. It recomputes the word inside context.
Put another way:
embedding gives a token an initial position;
self-attention relocates it according to context;
many Transformer layers update that position again and again.4. Q, K, and V: How Attention Is Computed
If we only say “the current token looks at the right places,” Attention can sound a little mystical. So let’s step one level closer to the mechanism.
The classic explanation of Attention uses three terms:
Query
Key
ValueA useful first intuition is:
Query: What information am I looking for?
Key: What information do I contain, and am I a good match?
Value: If someone references me, what content can I provide?When a token vector enters Attention, the model transforms it into three vectors: Q, K, and V.
Then the model compares the current token’s Query with the Keys of other tokens. A higher match means the current token should reference that position more strongly. After those weights are computed, the model uses them to take a weighted sum of the other tokens’ Values.
In a simplified flow:
current token's Query
→ compare it with every token's Key
→ get attention weights
→ use those weights to combine every token's Value
→ produce new information for the current tokenFor the sentence:
Ming put the backpack on the chair because it was too heavy.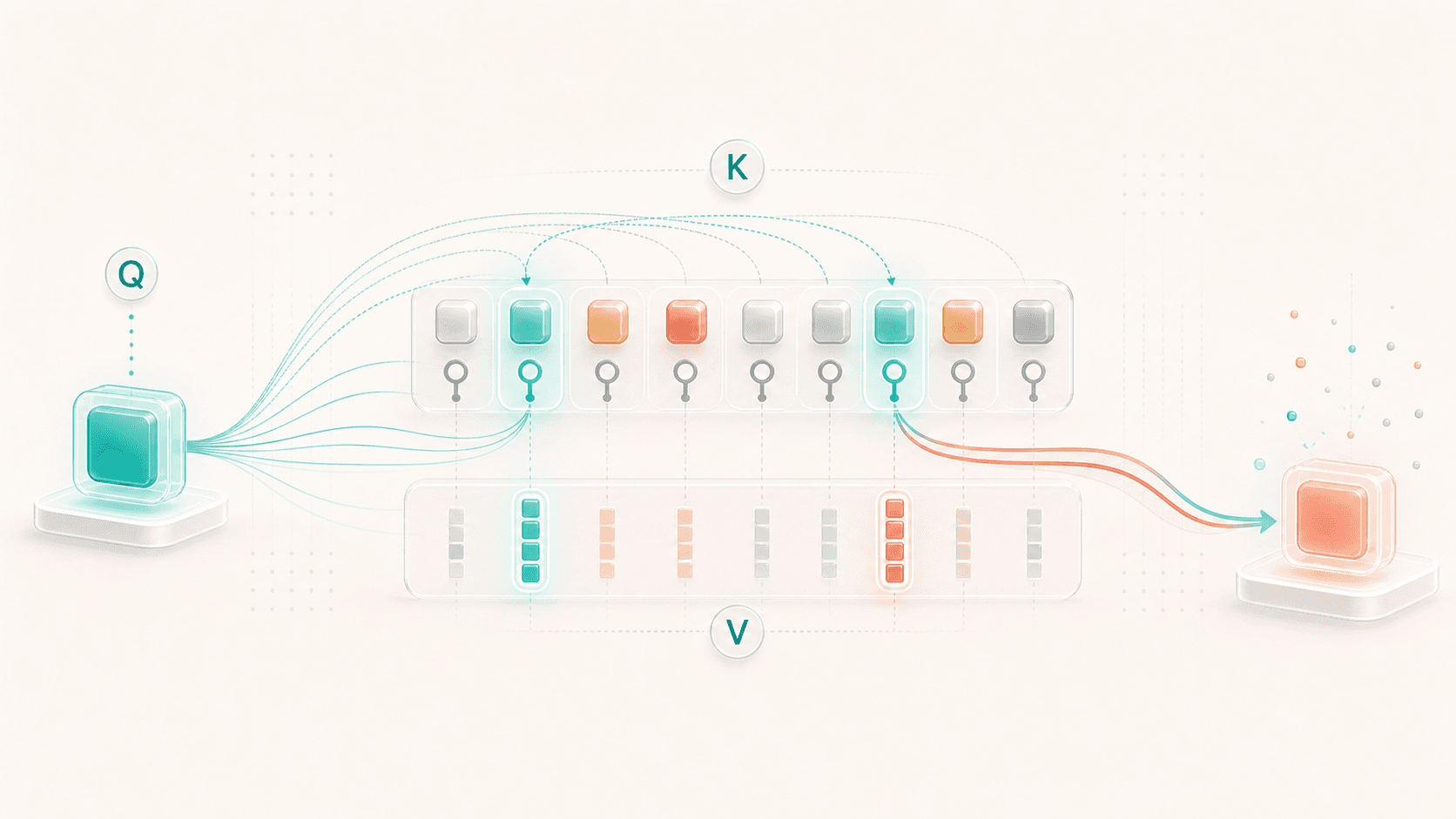
When updating “it,” the Query for “it” may match more strongly with the Keys around “backpack” and “too heavy,” so it pulls more Value information from those positions.
The real model uses much larger dimensions, matrices, and many layers. But the core intuition is this:
Attention uses Q and K to decide “who to look at,” then uses V to bring back the information it sees.
5. Multi-Head Attention: More Than One Relationship Happens at Once
Context usually contains more than one kind of relationship.
A sentence may simultaneously contain:
subject-verb relationships;
pronoun-reference relationships;
adjective-noun relationships;
question-answer relationships;
code variable and usage relationships;
format constraints and final-output relationships.If the model had only one Attention pattern at a time, it would struggle to capture all of these relationships together.
So Transformer uses Multi-Head Attention. The point is not to “look harder.” It is to run several attention calculations in parallel over the same context. Each calculation can learn a different way to connect tokens.
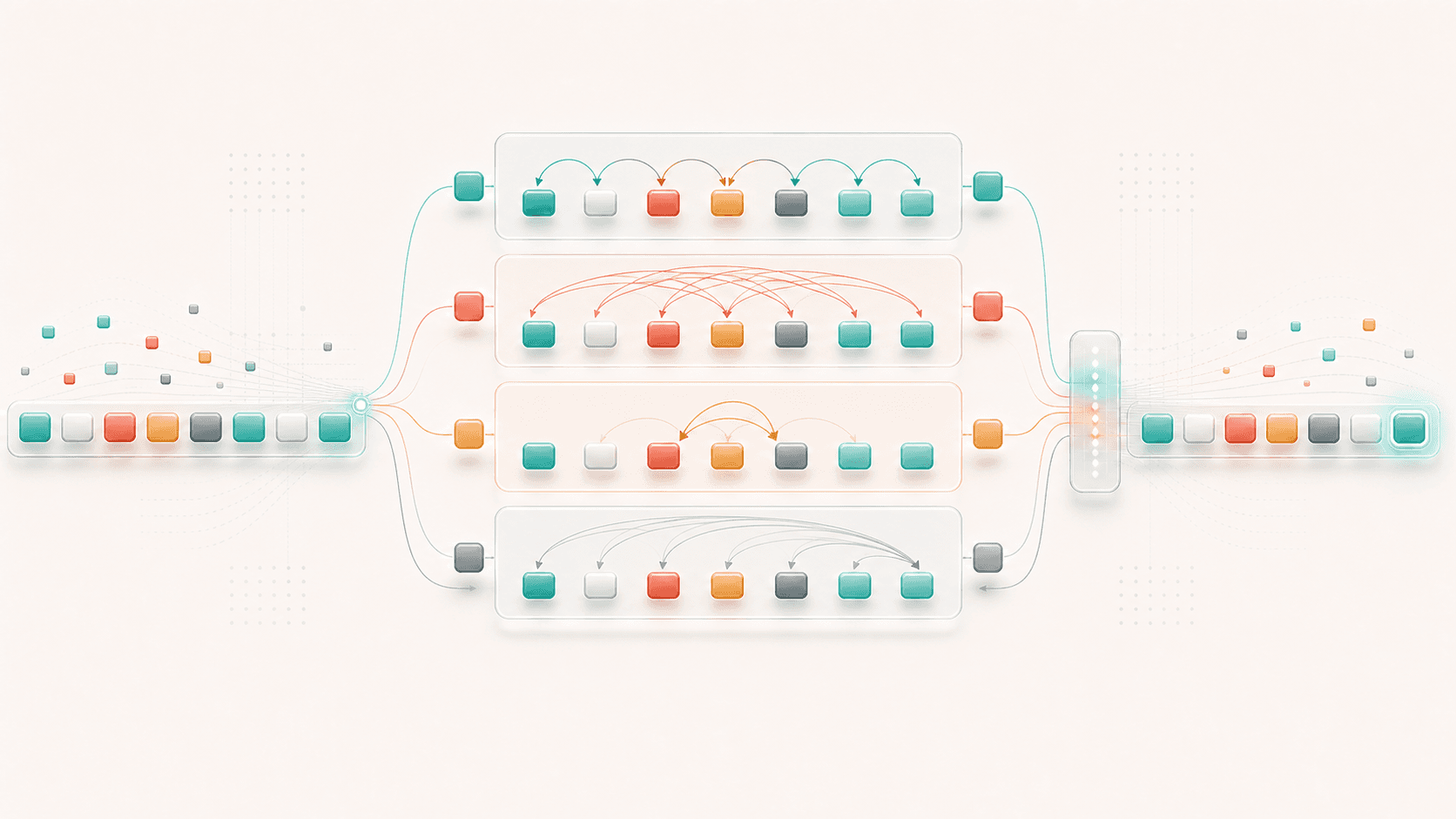
One head may be better at syntax. Another may be better at reference. Another may track brackets and variables in code. Another may pay attention to task instructions near the beginning of a prompt.
The word “may” matters. We should not treat every head as a neat human-readable module. These heads are learned high-dimensional computation structures, not hand-written components.
Still, the point of multi-head attention is clear:
Inside the same context, the model can compute multiple token relationships at the same time.This is one reason large models can handle complex prompts. A user instruction may include a role, task, constraints, examples, output format, and forbidden behavior all at once. The model needs to read many kinds of relationships from those tokens, not just grab one keyword.
6. Position: The Model Also Needs to Know Order
Attention has an interesting problem: it is very good at modeling relationships between tokens, but sequence order also matters.
These two sentences contain almost the same tokens, but mean different things:
Ming likes Hong.
Hong likes Ming.If the model only knew which tokens appeared, not their order, it could not distinguish the two sentences.
So Transformer needs some form of positional encoding or positional representation. This gives the model information about where each token appears in the sequence, how far apart tokens are, and which token came before another.
Different models use different positional methods. We do not need the formulas here. The intuition is enough:
Attention helps the model know what relationships to build between tokens.
Position helps the model know the order in which those relationships happen.This is one reason long-context models are difficult. As context gets longer, the model has to handle more tokens and maintain reliable position and relationship judgments across longer distances.
When critical information is far away from the current generation position, the model may become weaker. Not because it literally cannot see those words, but because deciding which long-distance information should be used becomes harder.
7. Transformer Layers: Attention Is Not the Whole Layer
Attention is important, but Transformer is not only Attention.
A typical Transformer layer also includes:
Attention: pulls relevant information from context;
feed-forward network: further processes information at each position;
residual connection: stabilizes the accumulation of old and new information;
layer normalization: stabilizes numerical distributions and makes training easier.Non-technical readers do not need to memorize these terms immediately. The more important point is the role of a Transformer layer:
Each layer turns “the current token representation” into “a representation that understands context better.”
Earlier layers may be closer to word shape, phrases, and local relationships. Deeper layers may form more abstract task structures, semantic relations, and reasoning states.
This is not a clean division of labor, and each layer does not come with a human-readable label. But overall, the model uses many layers of this computation to turn the raw token sequence into internal states that can predict the next token.
You can think of Transformer as a context-processing factory:
Input: a sequence of initial token vectors
Process: many layers of Attention and nonlinear transformations
Output: a sequence of new vectors containing contextual information
Use: predict the next token from the final position8. To Generate the Next Token, the Model Reads the Whole Context State
Now we can connect this post back to the first one.
The first post said that the first principle of large language models is:
Given the existing context, predict the next token.Now we can unpack “given the existing context” more precisely:
split the context into tokens;
turn tokens into embeddings;
use Transformer to update each token's contextual representation;
use the representation at the final position to compute the probability distribution over the next token.Suppose you ask:
Summarize the article above in three bullet points.When the model generates the answer, it is not just looking at the word “summarize.” It needs to handle:
the content of the article above;
the quantity constraint "three";
the task type "summarize";
your current language and tone;
safety and style requirements in the system prompt;
the answer it has already generated so far.All of this enters the context as tokens, then affects the next-token probability through Attention and Transformer layers.
That is why prompt structure matters. You are not handing the model an abstract wish. You are giving it a context that will be processed layer by layer.
Clear context makes correct relationships easier to build. Messy context, vague references, and conflicting constraints make it easier for the model to focus on the wrong thing.
9. What This Means for Products and Engineering
Once you understand Transformer and Attention, many practical tips stop feeling like superstition.
1. Put Important Information Where the Model Can Relate to It
If you want the model to follow a constraint, do not bury it in the middle of a very long text with vague wording.
Better practices:
separate goals, constraints, input material, and output format;
place the most important requirements close to the task;
use clear headings and lists to reduce relationship ambiguity;
avoid vague references like "it," "this," and "the above thing" when precision matters.In essence, you are making it easier for Attention to find the right relationships.
2. Examples Work Because They Provide a Context Pattern
Few-shot prompting works not only because you “tell” the model the answer. It works because examples show a mapping between input and output inside the context.
From examples, the model can infer:
what kind of input maps to what kind of output;
what the output format should look like;
how boundary cases should be handled;
what tone and level of detail are expected.This is why good examples can be more effective than long abstract rules.
3. Long Context Is Not Infinite Memory
A larger context window does not mean the model has perfect memory.
Long context only means the model can receive more tokens. Whether it can use the relationships among those tokens reliably still depends on information structure, position, task difficulty, and model capability.
So for long-document QA, contract analysis, or codebase understanding, we still need:
structured input;
section summaries;
retrieval ranking;
source citations;
critical evidence placed near the question.4. RAG and Tool Use Organize Context for the Model
RAG does not turn the model into a database. It is more like retrieving the most likely useful material before generation and placing it where the model can attend to it.
Tool use is similar. The model itself only generates tokens, but the system can write tool results, search results, or code execution results back into the context, so the model can reference that new information in the next step.
So the key to many AI products is not fancy prompt wording. It is:
how to put the right information,
at the right moment,
in the right structure,
inside the model's context.10. Common Misunderstandings
Misunderstanding 1: Attention is the same as human attention.
No. Attention is a trainable weighted information-aggregation mechanism. It is not consciousness, intention, or human subjective focus.
Misunderstanding 2: The model will use everything in the context.
No. Context is what the model can see, not what it will effectively use. Position, clarity, and task structure all affect whether the model finds the important information.
Misunderstanding 3: Transformer is just keyword matching.
No. Keywords matter, but Transformer learns high-dimensional relationships: reference, syntax, semantics, format, task patterns, and reasoning steps.
Misunderstanding 4: Longer context always gives better results.
Not necessarily. More tokens can also mean more distraction. An unstructured long context can make it harder for the model to decide what matters.
11. Summary: How Models See Context
We can compress this third post into one chain:
tokens give the model discrete symbols;
embeddings give tokens initial vectors;
Attention lets each token find the context positions it should reference;
Multi-Head Attention lets the model capture many relationships at once;
position representation tells the model order and distance;
many Transformer layers update initial representations into contextual representations;
finally, the model uses those contextual representations to predict the next token.In one sentence:
The core role of Transformer is to stop tokens from living in isolation and repeatedly rewrite them through contextual relationships.
Once you understand this, many LLM behaviors become easier to explain.
Why can a model understand pronouns? Because token representations can absorb information from related context.
Why does prompt structure change results? Because structure changes how hard it is for Attention to build the right relationships.
Why can long-context models still miss key points? Because visible does not mean usable.
Why does RAG help? Because it places useful information into relationships the model can compute over.
In the next post, we will go one layer deeper: if the model is only predicting text, why does text prediction grow into knowledge, reasoning, and intelligence? In other words, why can we say language is a compression of the world?