03:Transformer 与 Attention:模型如何「看见」上下文
这是「用第一性原理理解大模型」系列的第 3 篇。上一篇我们讲了 token、token id 和 embedding:语言先被切成 token,再被映射成模型能计算的向量。但这些向量一开始只是「孤立的初始表示」。真正让模型理解一句话里谁和谁有关、哪个词该参考哪个词、当前问题该看哪段上下文的,是 Transformer 和 Attention。本文就来拆这件事:模型到底如何「看见」上下文?
上一篇结束时,我们把文本的处理过程,压缩成了一条链路:
文本
→ token
→ token id
→ embedding 向量
→ Transformer
→ 下一个 token 的概率分布现在问题来了:
embedding 已经把每个 token 变成了向量,
为什么还需要 Transformer?因为一个 token 的意义,往往不在它自己身上,而在它和上下文的关系里。
看这三个句子:
我吃了一个苹果。
我买了一台苹果电脑。
苹果发布了新产品。「苹果」这两个字一样,但含义完全不同。单独看 token 的初始 embedding,它只能给出一个起点;真正的语义,需要根据周围内容不断被改写。
再看一个更典型的例子:
小明把书包放在椅子上,因为它太重了。这里的「它」大概率指「书包」,不是「椅子」。为什么?因为「太重」更像在描述书包。
人类读这句话时,会自然地把「它」「书包」「太重」连起来。模型也需要做类似的事:在一串 token 里,找出哪些 token 之间存在关系,并用这些关系更新每个 token 的表示。
这就是 Transformer 要解决的问题:
给定一串 token 向量,如何让它们根据上下文,把自身变成一个更契合上下文的新向量?
一、模型无法一眼读懂句子,它需要不断融合上下文来「理解」
先建立一个概念:句子进入模型后,模型并不能一下子就读懂句中要表达的「意思」。
起初它被拆成一个个 token,每个 token 带着一个初始向量。这个初始向量只代表它自己,还没有与前后文产生关联。
比如:
巴黎 / 是 / 法国 / 的 / 首都 / 。/ 它 / 以 / 埃菲尔铁塔 / 闻名刚开始,「它」这个 token 向量只知道自己是一个代词。它还不知道自己指的是谁。
Transformer 要解决的正是这个上下文关联问题,不是把整句话揉成一团,然后得到一个总意思;而是让每个位置反复问一个问题:
为了理解我这个位置,
我应该从前后哪些 token 那里补充信息?于是,「它」会从前面的「巴黎」「法国」「首都」这些位置吸收信息。经过多层 Transformer 处理后,「它」所在位置的向量,就不再只是一个孤立的代词向量,而是带上了「这里大概率指巴黎」的上下文信息。
所以,模型内部处理的不是一串固定的「词义」。更准确地说,它在处理每个 token 位置上的向量,而这些向量会一层层吸收上下文信息:
第一层:每个位置先看见一些局部关系;
第二层:位置之间交换更多信息;
更深层:每个位置逐渐带上更完整的上下文;
最后:模型用这些上下文状态去预测下一个 token。代码里也一样。比如:
function add(a, b) {
return a +模型要预测下一个 token 时,当前位置不能只看见前面有一个 return 和一个 a +。它还要知道函数参数里出现过 b,并把这个信息带到当前生成位置上。这里的关键关系,横跨了好几个 token。
如果没有这层上下文更新,模型看到的只是孤立符号;有了 Transformer,每个位置才会逐渐带上「我和上下文里其他位置有什么关系」的信息。
二、Attention 解决的核心问题:当前 token 应该看哪里
Transformer 里最出名的机制叫 Attention,通常翻译成「注意力机制」。
这个名字容易让人误会,好像模型真的在像人一样集中注意力。更准确地说,Attention 是一种计算方法,用来回答一个问题:
当我更新当前 token 的表示时,
应该从上下文里的哪些 token 那里拿信息?
每个 token 的信息应该拿多少?我们可以把它想象成一个动态参考系统。
当模型处理「它」这个 token 时,可能会发现:
书包:高度相关
椅子:有点相关
太重:高度相关
小明:低相关于是「它」的新表示,就会更多吸收「书包」和「太重」的信息。
注意,这不是人为写好的规则。没人告诉模型:「遇到『太重』时,把『它』指向前面的可搬动物体。」模型是在海量 next token prediction 训练中,自己学会了哪些上下文关系对预测有用。
这就是 Attention 的关键价值:
它让每个 token 在每一层计算里,都可以重新选择该参考上下文里的哪些位置。
也因此,大模型才能处理:
长句里的指代关系;
代码里的变量引用;
多轮对话里的前后约束;
文章里的论点承接;
数学推导里的前一步结果;
用户 prompt 里的格式要求。这些能力的底层都离不开一件事:模型要在上下文中建立关系。
三、Self-Attention:在同一段上下文里找参考对象
大模型里常说的 Attention,多数时候指的是 self-attention,也就是「自注意力」。
这里的 self 不神秘。它的意思是:模型要参考的信息,就来自当前这段 token 序列本身,而不是在外部数据库或单独的记忆区的另一段文本。
更技术一点说,Query、Key、Value 都是从同一段 token 序列里算出来的。所以它叫 self-attention。
假设输入是:
我 / 喜欢 / 红色 / 苹果在 self-attention 里,模型更新某个位置的向量时,会在上述四个向量上下文里找参考对象。
对于生成式大语言模型,当前位置通常不能偷看未来 token。训练和生成时会使用因果掩码(causal mask),让每个位置只能参考它自己以及它之前已经出现的位置。
所以,每个位置更像是在问:
为了更新我自己,
已经看到的上下文里哪些位置最有用?比如:
「苹果」这个位置可能重点参考「红色」和「喜欢」;
「红色」这个位置可能参考「喜欢」和「我」;
「喜欢」这个位置可能参考「我」;
生成下一个 token 时,模型会参考前面整段上下文形成的状态。这一步做完以后,每个 token 的表示都不再只是自己的初始 embedding,而是混入了和它相关的上下文信息。
这也是为什么同一个词在不同句子里会有不同含义。因为 Transformer 不是只看词本身,而是把词放进上下文里重新计算。
换句话说:
embedding 给 token 一个初始位置;
self-attention 根据上下文重新定位它;
多层 Transformer 反复更新这个位置。四、Q、K、V:Attention 是怎么算出来的
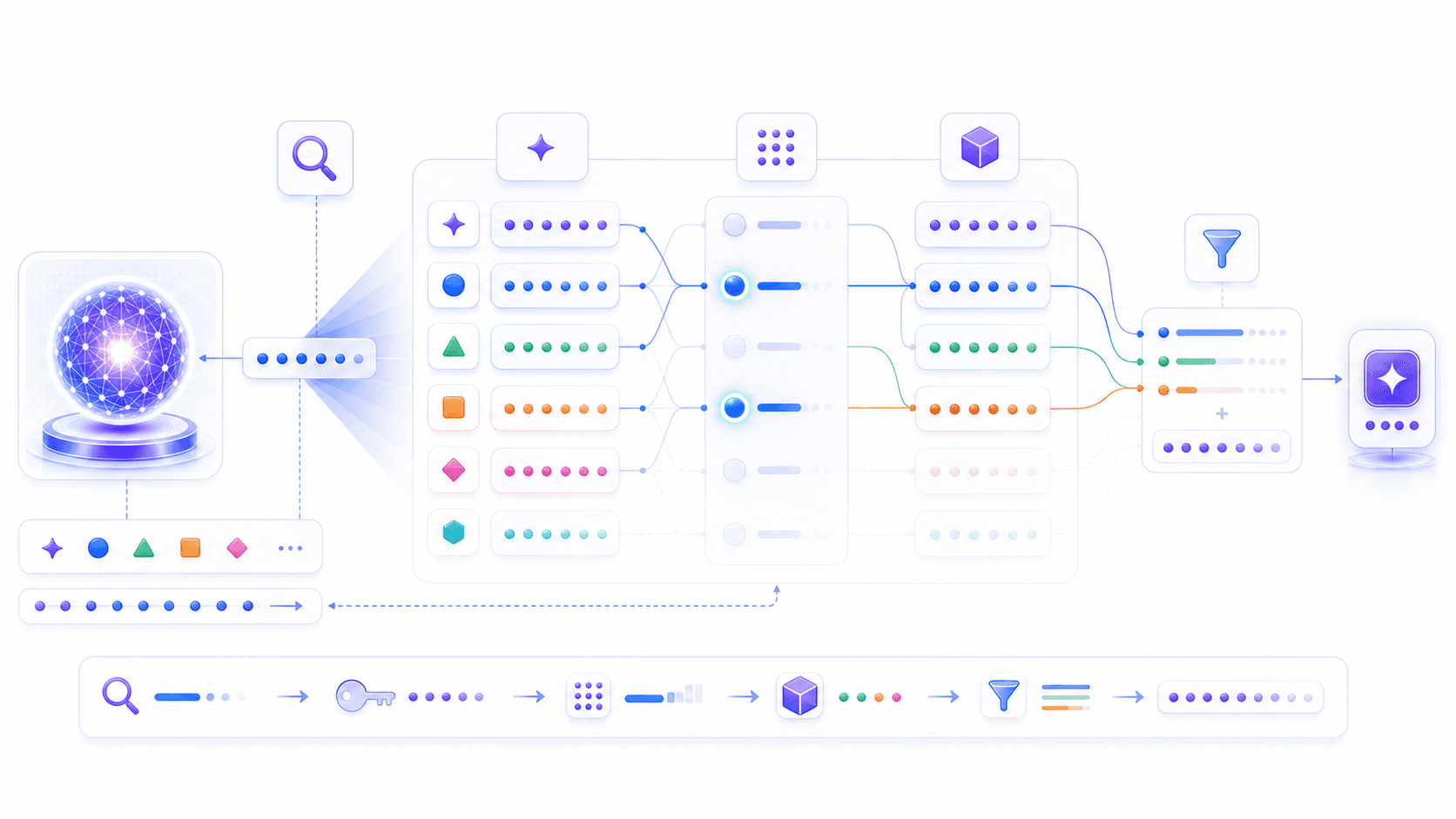
如果只停留在「当前 token 看哪里」这个比喻,容易觉得 Attention 有点玄学。我们稍微往技术机制里走一步。看看技术上,每个 token 是如何决定自己应该看哪里的。
Attention 的经典解释里,有三个词:
Query
Key
Value可以先把它们理解成三种角色:
Query:我现在想找什么信息?
Key:我这里有什么信息,适不适合被别人找?
Value:如果别人要参考我,我能提供什么内容?每个 token 的向量进入 Attention 时,都会被变换成 Q、K、V 三个向量。
然后,模型会用当前 token 的 Query 去和其他 token 的 Key 做匹配。匹配度越高,说明当前 token 越应该参考那个位置。这些匹配分数会经过 softmax 归一化,变成一组加起来等于 1 的注意力权重。得到权重以后,再按这些权重把其他 token 的 Value 加权汇总回来。
可以写成一个非常简化的流程:
当前 token 的 Query
→ 和所有 token 的 Key 计算相关性
→ 经过 softmax 得到一组归一化注意力权重
→ 按权重汇总所有 token 的 Value
→ 得到当前 token 的新信息比如在句子:
小明把书包放在椅子上,因为它太重了。当更新「它」时,「它」的 Query 可能会和「书包」「太重」这些位置的 Key 有更高匹配度,于是它会从这些位置拿到更多 Value 信息。
当然,真实模型里的维度、矩阵和层数要复杂得多。但核心直觉就是这一句:
Attention 通过 Q 和 K 计算「该看谁」,再通过 V 把「看见的信息」带回来。
五、Multi-Head Attention:模型需要同时计算上下文中的多种关系
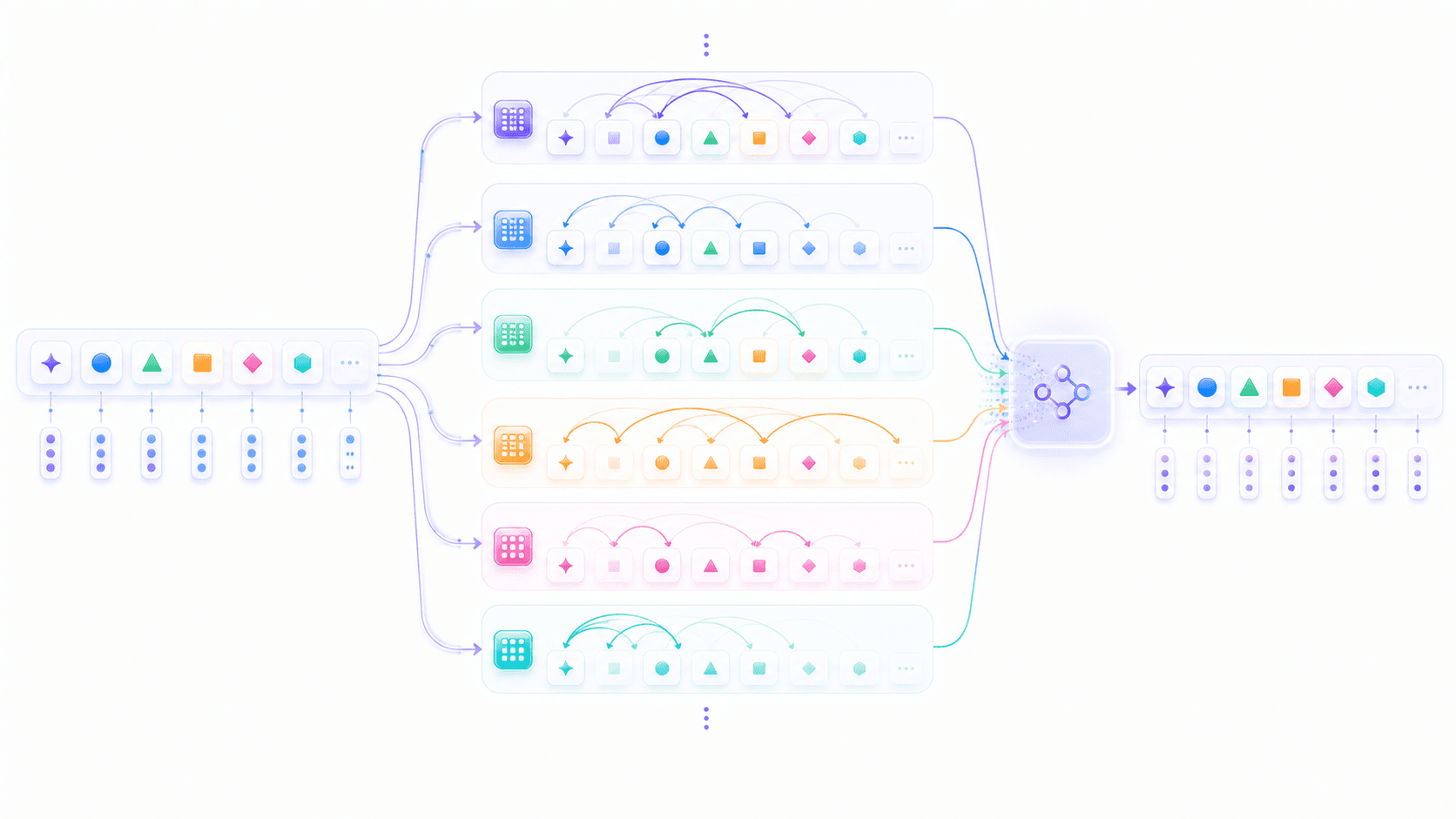
现实世界中,上下文里的关系通常不止一种。
一句话里可能同时有:
主语和谓语的关系;
代词和指代对象的关系;
形容词和名词的关系;
问题和答案的关系;
代码变量和使用位置的关系;
格式要求和最终输出的关系。如果模型每次只能用一个 Attention,它就很难同时捕捉这么多关系。
所以 Transformer 使用 Multi-Head Attention,也就是「多头注意力」。它的核心是在同一段上下文上,并行做多组 attention 计算。每一组计算,都可以学习一种不同的 token 关联方式。
一组 attention 可能更擅长看语法结构,一组 attention 可能更擅长看指代关系,一组 attention 可能更关注代码里的括号和变量,一组 attention 可能更关注段落开头的任务指令。
这里的「可能」很重要。我们不能把每组 attention 简单命名成某种人类可读功能,因为它们是训练学出来的高维计算结构,不是工程师手写的模块。
因此多头注意力的意义很清楚:
在同一段上下文里,模型可以同时计算多种 token 关系。这也是大模型能够处理复杂 prompt 的原因之一。用户给的指令里,可能同时包含角色、任务、约束、示例、输出格式和禁区。模型需要从这些 token 中同时读出多种关系,而不是只抓一个关键词。
六、位置信息:模型还需要知道谁在前、谁在后
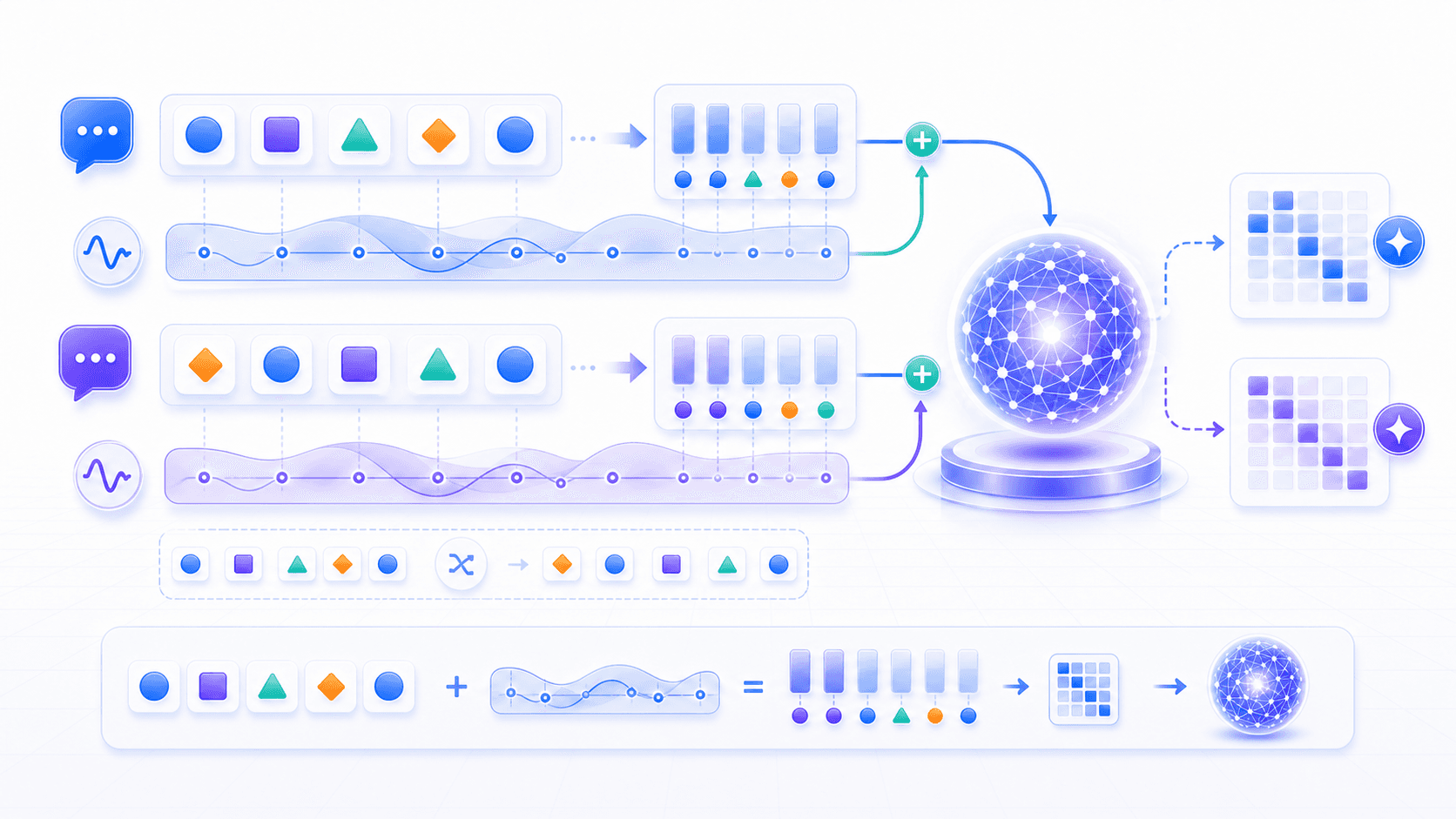
Attention 有一个很有意思的问题:它天然更关注 token 之间的相关性,但序列里的位置也很重要。
这两句话的 token 差不多,但意思不同:
小明喜欢小红。
小红喜欢小明。如果模型只知道有哪些 token,不知道它们的顺序,就无法区分这两句话。
因此 Transformer 需要某种位置编码或位置表示,让模型知道每个 token 出现在序列中的哪个位置、相对距离多远、谁在谁前面。
不同模型会使用不同的位置表示方式。这里不展开具体公式,只要抓住一个直觉:
Attention 让模型知道 token 之间该建立什么关系;
位置信息让模型知道这些关系发生在怎样的顺序里。这也是长上下文模型困难的原因之一。上下文越长,模型不仅要处理更多 token,还要在更长距离上维持可靠的位置和关系判断。
当关键信息离当前生成位置太远,模型就可能变弱:不是因为它「没看到」这些字,而是因为在长距离关系里,哪些信息最该被用上,会变得更难判断。
七、Transformer 层:Attention 之后还要加工
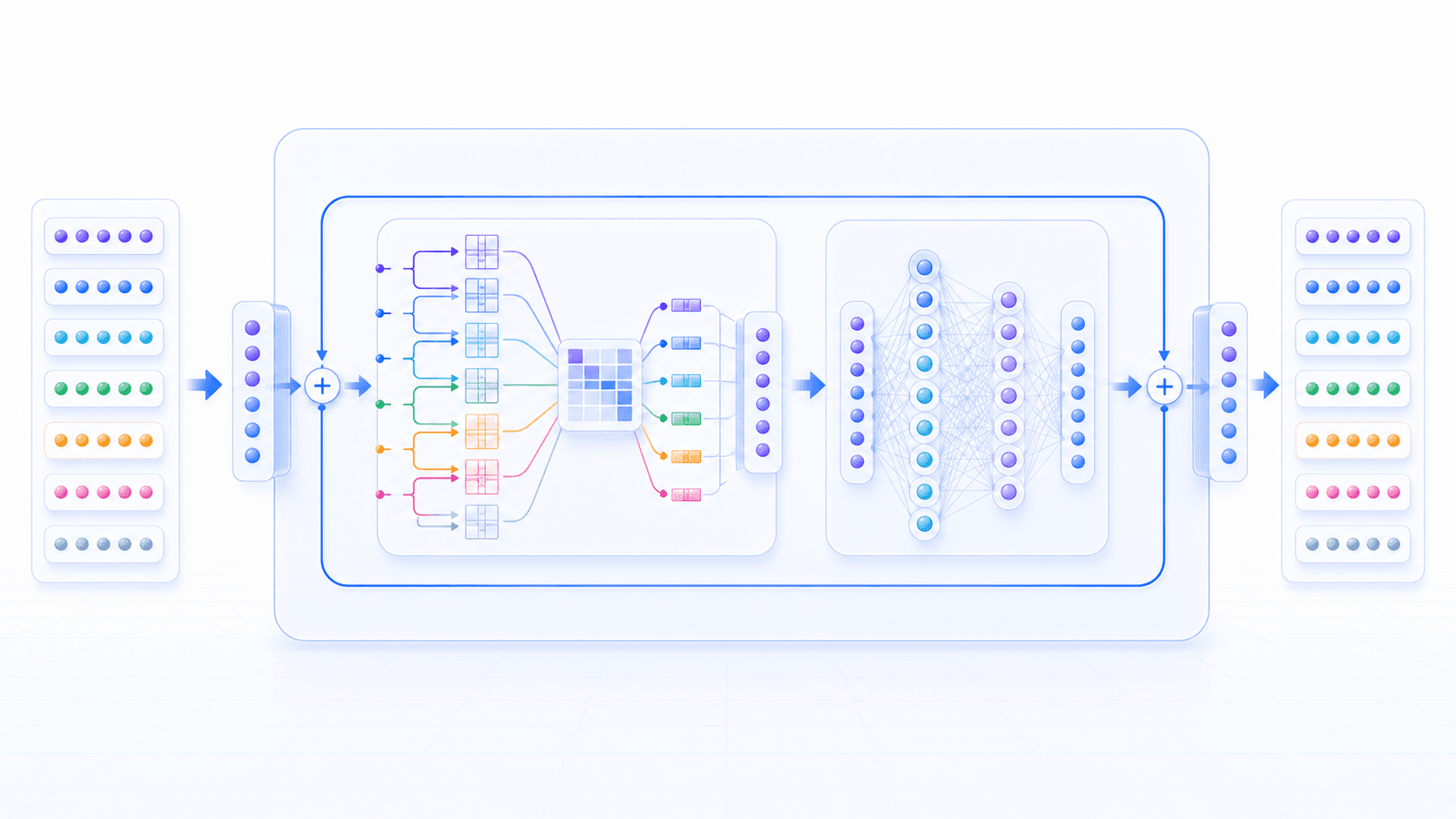
Attention 很重要,但 Transformer 不只有 Attention。
一个典型 Transformer 层里,通常还会有:
Attention:从上下文里拿相关信息;
Feed-forward network:对每个位置的信息做进一步加工;
Residual connection:让新旧信息更稳定地叠加;
Layer normalization:让数值分布更稳定,训练更容易。对非技术读者来说,不需要立刻记住这些名词。更重要的是理解 Transformer 层的整体作用:
每一层都在把「当前 token 的表示」变成「更懂上下文的表示」。
第一层可能更接近词形、短语和局部关系;更深的层可能逐渐形成更抽象的任务结构、语义关系和推理状态。
这不是严格分工,也不是每层都有明确的人类标签。但从整体上看,模型就是通过很多层这样的计算,把原始 token 序列逐步加工成可以用于预测下一个 token 的内部状态。
所以我们可以把 Transformer 看成一个上下文加工厂:
输入:一串初始 token 向量
过程:多层 Attention 和非线性变换
输出:一串包含上下文信息的新向量
用途:根据最后位置的向量,预测下一个 token八、生成下一个 token 时,模型看的是整个上下文状态
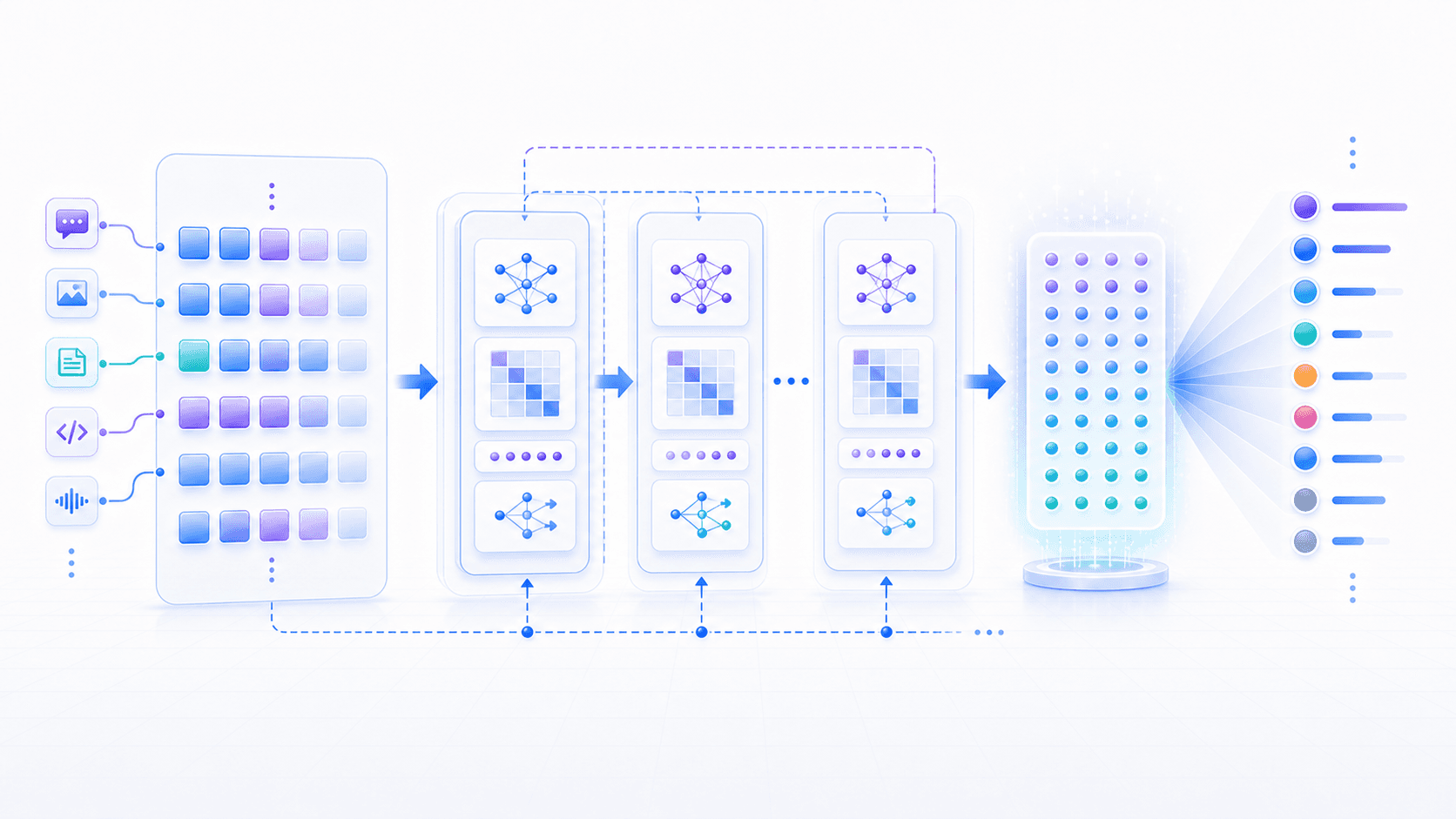
现在我们把这篇文章和第一篇连起来。
第一篇说,大模型的第一性原理是:
根据已有上下文,预测下一个 token。现在我们可以把「根据已有上下文」拆得更细:
把上下文切成 token;
把 token 变成 embedding;
用 Transformer 反复更新每个 token 的上下文表示;
用最后一个位置的表示,计算下一个 token 的概率分布。比如你问:
请用三点总结上面这段文章。模型在生成答案时,不只是看「总结」这两个字。它需要同时处理:
上面那段文章的内容;
「三点」这个数量约束;
「总结」这个任务类型;
你当前语言和语气;
系统提示词里的安全和风格要求;
已经生成出来的前半段回答。这些信息都会以 token 的形式进入上下文,再通过 Attention 和 Transformer 层影响下一个 token 的概率。
这就是为什么 prompt 结构很重要。你给模型的不是一个抽象愿望,而是一段会被模型逐层处理的上下文。
如果上下文清晰,模型更容易建立正确关系。如果上下文混乱、指代模糊、约束互相冲突,模型就更容易抓错重点。
九、这对产品和工程意味着什么
理解 Transformer 和 Attention 以后,很多实践经验会变得没那么玄学。
1. 关键信息要放在模型容易关联的位置
如果你希望模型遵守某条约束,就不要把它埋在很长文本中间,还用含糊表达一笔带过。
更好的做法是:
把目标、约束、输入材料、输出格式分区;
把最重要的要求放在靠近任务的位置;
用明确标题和列表降低关系判断难度;
减少「它」「这个」「上面那个」这类模糊指代。本质上,你是在帮 Attention 更容易找到正确关系。
2. 示例有效,是因为它提供了可模仿的上下文结构
Few-shot prompt 之所以有效,不只是因为你「告诉」了模型答案,而是因为示例在上下文里展示了输入和输出之间的对应关系。
模型可以从示例中读出:
什么样的输入对应什么样的输出;
输出格式应该长什么样;
边界情况如何处理;
语气和颗粒度应该如何控制。这也是为什么好示例比长篇抽象规则更有效。
3. 长上下文不是无限记忆
上下文窗口变长,不等于模型拥有了完美记忆。
长上下文只是意味着模型可以接收更多 token。至于这些 token 之间的关系能否被稳定利用,还取决于信息组织、位置、任务难度和模型能力。
所以在长文问答、合同分析、代码仓库理解里,仍然需要:
结构化输入;
分段摘要;
检索排序;
引用来源;
把关键证据放到靠近问题的位置。4. RAG 和工具调用,本质上是在帮模型组织上下文
RAG 不是把模型变成数据库。它更像是在生成前,把最可能有用的资料取出来,放进模型可以 attention 到的位置。
工具调用也是类似。模型本身只生成 token,但系统可以把工具结果、搜索结果、代码执行结果重新写回上下文,让模型在下一步生成时参考这些新信息。
所以,很多 AI 产品的关键不是「prompt 写得花哨」,而是:
如何把正确的信息,在正确的时刻,用正确的结构,放到模型上下文里。十、常见误解
误解一:Attention 就等于人类注意力。
不是。Attention 是一种可训练的加权信息汇总机制,不等于人类的意识、意图或注意体验。
误解二:模型一定会用上上下文里的所有信息。
不会。上下文只是可见范围,不代表所有信息都会被有效利用。信息位置、表达清晰度和任务结构都会影响模型是否抓到重点。
误解三:Transformer 只是在做关键词匹配。
不只是。关键词会产生影响,但 Transformer 学到的是高维关系,包括指代、语法、语义、格式、任务模式和推理步骤。
误解四:长上下文越长,效果一定越好。
不一定。更多 token 也意味着更多干扰。没有结构的长上下文,可能让模型更难判断什么重要。
十一、总结:模型如何看见上下文
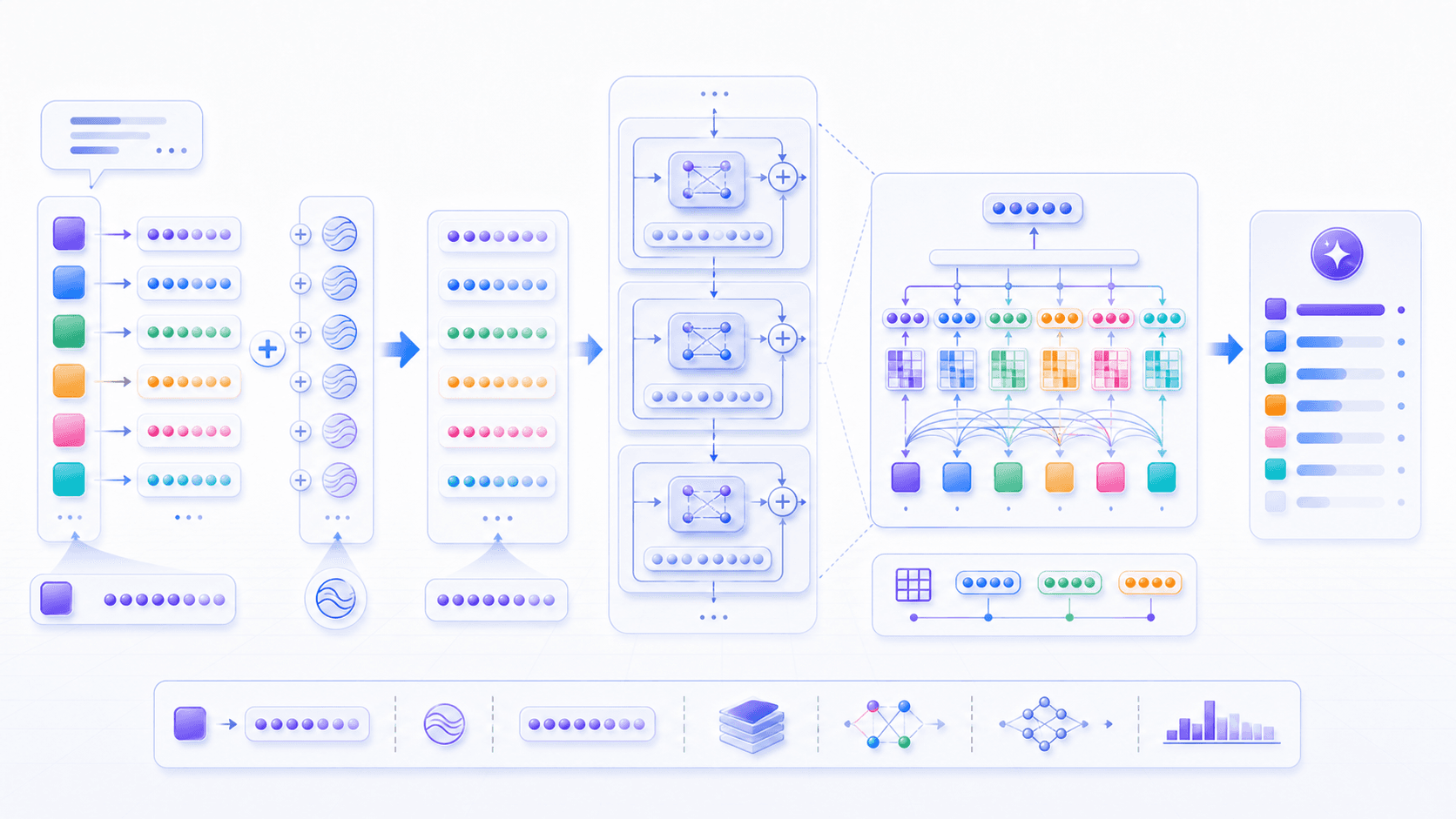
现在我们可以把第 3 篇压缩成一条链:
token 给模型离散符号;
embedding 给 token 初始向量;
Attention 让每个 token 找到该参考的上下文位置;
Multi-Head Attention 让模型同时捕捉多种关系;
位置表示让模型知道顺序和距离;
多层 Transformer 把初始表示更新成上下文表示;
最后,模型根据这些上下文表示预测下一个 token。如果再压缩成一句话:
Transformer 的核心作用,是让 token 不再孤立存在,而是在上下文关系中被反复改写。
理解了这一点,很多 LLM 现象都会更容易解释。
为什么模型能理解代词?因为 token 表示会从相关上下文里吸收信息。
为什么 prompt 的结构会影响效果?因为结构会影响 Attention 建立关系的难度。
为什么长上下文仍然会丢重点?因为可见不等于可用。
为什么 RAG 有用?因为它把可用信息放进模型能处理的上下文关系里。
十二、技术附录:Attention 公式的直觉
如果把 Self-Attention 写成最常见的公式,大概是:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V这行公式可以拆成四步理解:
Q:当前 token 带着一个问题,它想知道自己该参考谁;
K:上下文里的每个 token 提供一个可被匹配的标签;
QK^T:当前问题和所有标签做相似度计算;
softmax(...)V:把相似度变成权重,再按权重汇总对应的信息。除以 sqrt(d_k) 是为了让相似度分数别因为向量维度变大而过度膨胀;softmax 则把这些分数变成一组可以加权平均的注意力权重。
所以,公式背后的直觉仍然是本文一直在讲的那句话:
当前 token 应该从上下文里的哪些位置拿信息,以及各拿多少。
十三、你应该能回答的三个问题
读完这一篇,可以试着用自己的话回答:
- Attention 解决的核心问题是什么?
- 为什么上下文窗口里的信息「可见」不等于「一定会被用上」?
- 为什么 RAG、工具调用和 prompt 结构,本质上都在帮助模型组织上下文?
下一篇,我们继续往更深一层走:既然模型只是预测文字,为什么预测文字会长出知识、推理和智能?换句话说,为什么说语言是世界的压缩?