05: Pretraining, Fine-tuning, and Alignment: From Continuation Machine to Assistant

This is the fifth post in the “Understanding LLMs from First Principles” series. Post 04: Language as Compression of the World explained why predicting text forces a model to learn structures behind language. Now we ask the next question: if a pretrained model is fundamentally a next-token continuation system, how does it become something that answers questions, follows formats, refuses unsafe requests, and cooperates like an assistant? This post answers that question through pretraining, fine-tuning, and alignment.
Across the previous posts, we kept returning to one basic mechanism:
Given context, predict the next token.That mechanism is simple enough to state and powerful enough to explain a lot.
It explains how text becomes tokens, how embeddings represent language, how Transformer layers build contextual relationships, and why predicting language can compress world structure.
But now a new question appears:
If the model only learns to continue text,
why does it not wander around the opening text and keep writing like a novel or a forum thread?
Why does it stop and answer my question?For example, you type:
Explain gradient descent to me.A pure continuation model could plausibly continue in many ways:
Explain gradient descent to me. This is a common question for beginners...
Explain gradient descent to me. In this article, we begin with the mathematical definition...
Explain gradient descent to me. User A: I also want to know...
Explain gradient descent to me. Sorry, I am not sure...All of these look like possible text continuations.
But what we expect from an assistant is:
Gradient descent is an optimization method that gradually adjusts model parameters...In other words, a modern assistant does not only predict the next token. It has learned a more specific behavior pattern:
When the context looks like a user instruction, produce a helpful, understandable, bounded response.
That behavior does not appear from nowhere.
It comes from three layers:
Pretraining: learn language, knowledge, and world structure
Supervised fine-tuning: learn to connect user instructions with ideal responses
Preference alignment: learn which responses are more helpful, honest, and safeUnderstanding these three layers explains why large language models are not born as ChatGPT-style assistants.
1. Pretraining: First Build a Powerful Continuation Machine
Pretraining is the foundation of model capability.
The basic operation looks plain:
Take massive text corpora.
Split text into tokens.
Make sure the model can only see previous tokens at each position.
Use the current position's output to predict the next token.
Compare the predicted distribution with the real next token.
Adjust parameters when the prediction is wrong.
Repeat many, many times.The text may include web pages, books, code, papers, Q&A, tutorials, news, forums, conversations, documentation, and structured content.
At this stage, the model does not know that it will later become an “assistant.” It is learning:
What kind of text tends to follow what context?
Which words are related to which other words?
Which facts, formats, reasoning steps, and code structures often appear together?
How do humans describe problems, explain concepts, write programs, and debate ideas?This is why pretrained models have strong base capabilities.
They have seen many mathematical derivations, so they can compress mathematical structures. They have seen many codebases, so they can compress program patterns. They have seen many question-answer pairs, so they know many associations between questions and answers. They have seen many articles, so they can imitate many styles.
But pretraining only tells the model what text is statistically likely to come next. It does not explicitly tell the model:
When a user asks a question, answer it carefully.
Do not invent facts when you do not know.
Refuse dangerous requests.
Keep the response structured.
Do not suddenly switch into a forum comment section.
Do not treat the user's question as an article title and continue the article.So a pretrained model is more like a general language engine than a reliable assistant.
It contains many latent capabilities, but those capabilities have not yet been organized into stable product behavior.
You can imagine someone who has read many books, code files, and chat logs, but has not been trained in how to be an assistant.
They may know a lot, but they may not know when to be brief, when to ask a follow-up question, when to refuse, or when to give steps.
2. Supervised Fine-tuning: Turning Continuation Into Instruction Response
The next stage is supervised fine-tuning, often shortened to SFT.
The core idea is direct:
Show the model many examples of "user instruction -> ideal assistant response."For example:
User: Explain embedding in three sentences.
Assistant: An embedding is a way to turn discrete symbols into vectors...
User: Make the following paragraph more concise.
Assistant: ...
User: Write a Python function that checks whether a string is a palindrome.
Assistant: ...These examples are not ordinary web continuations. They are deliberately shaped as conversational tasks.
They teach the model:
When you see a request, treat it as a task.
When the user asks for a format, try to follow it.
When the question is broad, organize the answer.
When information is missing, state assumptions or ask a clarifying question.
When the user asks for code, provide code and explanation.
When the request is inappropriate, refuse or redirect to a safe alternative.From first principles, SFT does not change the next-token prediction objective.
It changes the training data distribution.
During pretraining, the model sees a broad internet-like mixture of text. During SFT, it sees high-quality instruction-response distributions.
So the model learns a new conditional pattern:
If the context looks like a user instruction,
the next text should look like an assistant response.This step is crucial.
Without SFT, the model may know many things but not know that it should organize them for you in the role of an assistant.
With SFT, the model begins to move from “can continue anything” toward “tries to complete the user’s task.”
But SFT has limits.
Many questions do not have one standard answer.
For example, the user asks:
Help me improve this product copy.Many responses could be valid:
a more concise version;
a more sales-oriented version;
a more restrained and professional version;
first explaining the problem, then rewriting;
giving three alternatives directly;
asking about target users and distribution channel first.All of these may be acceptable, but they are not equally good.
SFT can teach the model “answer like this,” but it is less precise at teaching “among many possible answers, prefer this kind of answer.”
That requires the next layer: preference alignment.
3. Preference Alignment: Teaching the Model Which Answer to Prefer
Preference alignment solves a different problem. Not “can the model answer?” but “which kind of answer should it lean toward?”
For the same prompt, the model can generate many candidate responses:
a long but rambling answer;
a short answer that misses key conditions;
a friendly answer with incorrect facts;
a structured answer that acknowledges uncertainty and solves the problem;
a warm answer that crosses a boundary.Users usually do not only want “an answer.” They want the answer to be:
helpful;
honest;
not fabricated;
appropriate to context;
respectful of constraints;
careful about risk when needed;
clear about uncertainty when uncertain.That is what alignment tries to shape.
Common methods include RLHF, RLAIF, and DPO. Their algorithms differ, but the first-principles structure is similar:
Ask the model to generate multiple candidate responses.
Use humans, AI judges, or preference data to decide which is better.
Turn that preference signal into a training signal.
Make the model more likely to generate preferred responses in the future.You can think of it this way: the model already knows many ways to speak. Alignment does not teach language from scratch. It adjusts the output distribution.
Increase the probability of helpful, clear, reliable, bounded responses.
Decrease the probability of fabricated, sycophantic, unsafe, verbose, or off-topic responses.This is similar to human role training.
Knowing how to talk does not mean knowing how to act as customer support, teacher, medical assistant, or product advisor. Different roles require knowing which things are appropriate to say and which things are possible to say but should not be said.
Preference alignment trains that tendency of “how to answer.”
Of course, alignment is not magic.
It can introduce new problems:
over-refusal: refusing questions that could be answered;
sycophancy: agreeing too readily with the user;
flattened style: safe but dull answers;
reward gaming: looking aligned without actually solving the task;
capability loss: some subtle abilities becoming weaker after alignment.So alignment is not simply “more is better.” It is an ongoing tradeoff.
Good alignment should make the model more reliable, not merely more polite.
4. An Assistant Is Not a Piece of Knowledge. It Is a Behavior Distribution
Once we understand pretraining, SFT, and alignment, we can define “assistant” more precisely.
An assistant is not a small inner module called “assistant personality.”
It is better understood as a behavior distribution shaped by training and system constraints:
When it sees a question, it is more likely to answer.
When it sees a task, it is more likely to decompose it.
When information is missing, it is more likely to state assumptions or ask.
When a request is unsafe, it is more likely to refuse and offer a safe alternative.
When a format is requested, it is more likely to follow it.
When tool results appear, it is more likely to synthesize them into readable output.The underlying mechanism is still next-token prediction. So why does the result differ?
Because context, training data, and preference signals have changed what the next token should look like.
This is also why the same base model can become different products after different post-training:
one feels like a search assistant;
one feels like a coding partner;
one feels like a writing editor;
one feels like a customer support bot;
one feels like a reasoning-oriented research assistant.The bottom mechanism is still token prediction, but the prediction distribution has been shaped into different task behaviors.

So we should not treat “assistant-like behavior” as a mysterious ability.
It comes from many concrete engineering choices:
what corpus to train on;
which capabilities to preserve;
what instruction examples to write;
which answers to prefer;
which requests to refuse;
how the system prompt is written;
how tool results are returned to context;
how the product interface guides user tasks.All of these change model behavior in real use.
5. A Modern AI Assistant Is a System, Not a Bare Model
When people discuss LLMs, they often attribute every capability to “the model itself.”
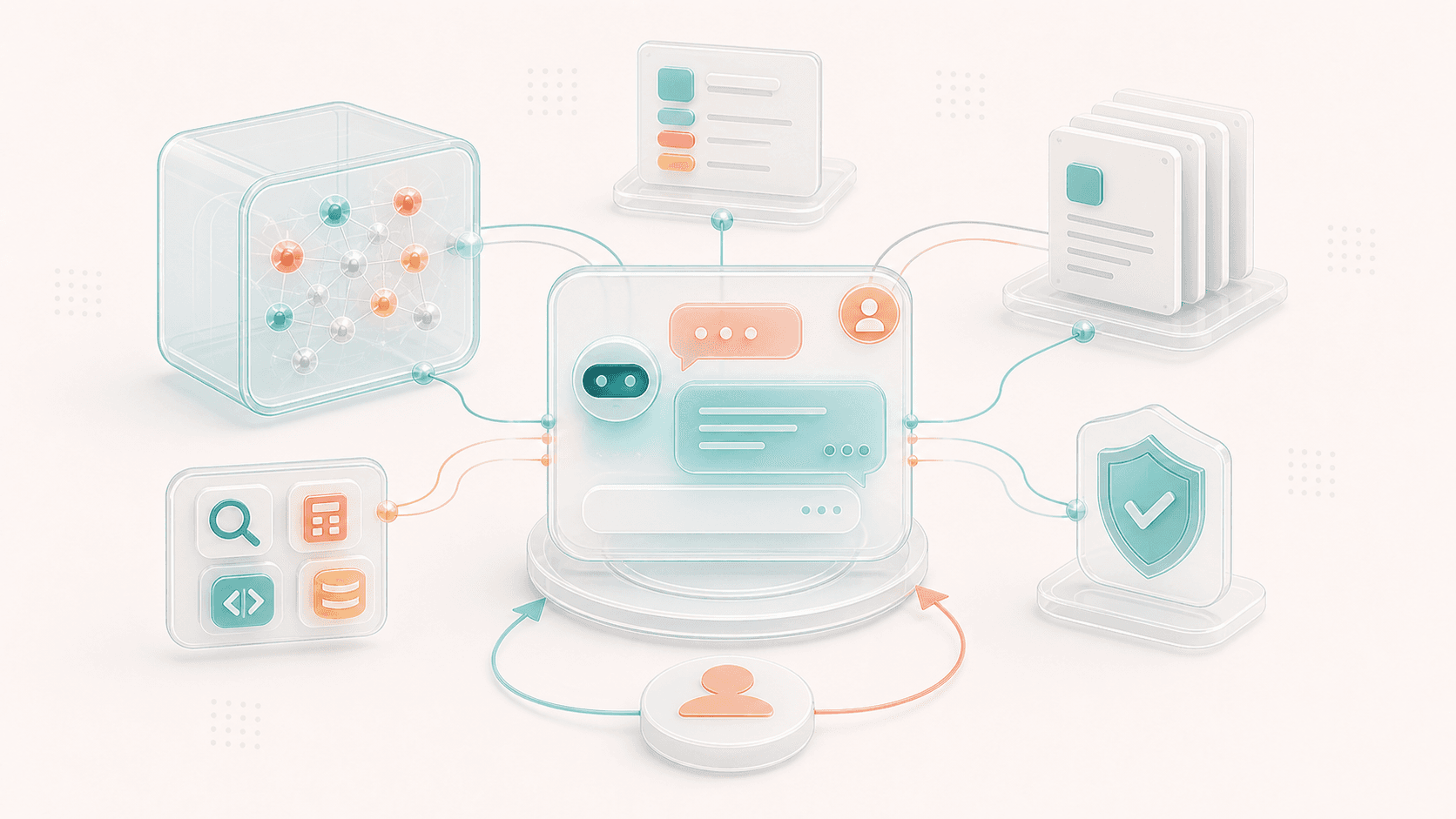
But an AI assistant in a real product is usually not a bare model.
It is a system:
base model
+ system prompt
+ developer instructions
+ user context
+ retrieval results
+ tool calls
+ safety policies
+ memory or preferences
+ evaluation and feedback
= assistant behavior in the productPretraining, fine-tuning, and alignment mostly shape the model itself. The system layer determines what information the model receives for each request, what boundaries it follows, which tools it can call, and how results return to the user.
For example, a customer support assistant should not rely only on the model having “memorized” support policies.
A better structure is:
The model understands the user's question.
RAG retrieves the latest policy and order information.
Tools query shipment or refund status.
Safety policies constrain privacy and permissions.
The model organizes the results into natural language.
User feedback flows back into evaluation.That is the real shape of a modern assistant.
The model is central, but it is not the whole system.
From this view, many product problems become easier to diagnose.
If the model gives wrong facts, fine-tuning may not be the answer. Retrieval or tools may be needed.
If the output format is unstable, replacing the model may not be necessary. Clearer instruction examples or output constraints may be enough.
If the model does not know an internal company process, the problem may be missing context, not stupidity.
If the model over-refuses, the issue may sit in safety policy, preference data, or system prompts.
6. Common Misunderstandings
Misunderstanding 1: Fine-tuning simply makes the model smarter.
Not exactly. Most fine-tuning changes the model’s behavior distribution so it fits a task or output format better. It can improve specific task performance, but it usually cannot create a foundational capability that pretraining never gave the model.
Misunderstanding 2: The pretrained model already knows everything, and alignment only restricts it.
No. Alignment is not only restriction. It organizes capabilities into usable behavior. Without alignment, the model may be more unstable, more arbitrary, and more likely to agree with false premises.
Misunderstanding 3: If the prompt is good enough, fine-tuning is unnecessary.
A prompt is temporary steering at runtime. Fine-tuning is a persistent shift after training. Small, changing, personalized tasks often fit prompts; frequent, stable tasks with strict format requirements may fit fine-tuning or workflow design better.
Misunderstanding 4: An assistant response fully represents the model’s true inner thought.
No. The response is a token sequence generated under the combined influence of current context, system instructions, alignment policy, and sampling settings. It is system behavior, not the private monologue of an independent subject.
Misunderstanding 5: Alignment always makes the model weaker.
Not necessarily. Poor alignment can reduce capability, but good alignment can make the model more reliable, controllable, and suitable for real products. The key is the quality of preference data, evaluation, and training method.
7. What This Means for Products and Engineering
If we see an LLM as a system shaped layer by layer from pretraining to alignment, engineering decisions become clearer.
1. Diagnose Which Layer the Problem Belongs To
Different problems call for different fixes:
Missing general capability: maybe use a stronger base model.
Missing domain knowledge: consider RAG, tools, or domain data first.
Ignoring format: improve instructions, examples, output constraints, or SFT.
Unstable style: use preference data and evaluation sets.
Unreliable facts: connect retrieval, databases, or verifiers.
Tasks too long: introduce workflows, tool calls, or agent frameworks.Do not solve every problem by changing models. Do not solve every problem by writing a longer prompt.
2. Data Quality Is Often Closer to the Bottleneck Than Data Quantity
Pretraining needs scale, but post-training depends heavily on quality.
A thousand high-quality instruction examples with clear boundaries and real task coverage may be more valuable than a hundred thousand noisy examples.
Preference data works the same way.
If the judging standard is confused, the model learns confused preferences. If the judge only rewards superficial politeness, the model may become smooth but unhelpful.
3. Evaluation Should Compare Candidate Answers, Not Only Single Outputs
Alignment is fundamentally preference selection, so evaluation should also compare.
Which of two answers is more helpful?
Which one contains fewer hallucinations?
Which one respects the user's constraints better?
Which one is more stable in boundary cases?
Which one knows when to call a tool?This is closer to product quality than asking whether a single output “looks right.”
4. Product Experience Comes From the Whole Chain, Not Only Parameters
Users experience the final assistant, not a training stage.
A good AI product often depends on:
a strong base model;
high-quality post-training;
clear system prompts;
reliable knowledge access;
verifiable tools;
reasonable interaction design;
continuous evaluation loops.That is why the same model can feel very different inside different products.
8. Summary: From Continuation Machine to Assistant
We can summarize this post in a few simple lines:
Pretraining teaches the model the structure of language and the world.
Supervised fine-tuning teaches the model to respond differently according to user requests.
Preference alignment makes the model prefer helpful, honest, and safe responses.
The system layer connects the model to context, tools, policies, and feedback.
A continuation system becomes an assistant.If we compress it into one sentence:
Pretraining gives the model capability, fine-tuning teaches it how to handle user requests, alignment teaches it what to say and what not to say, and system engineering turns those capabilities into a usable assistant experience.
This explains an important fact:
The capability of an LLM product does not only come from model size. It also comes from how the model is trained, how it is aligned, and how it is placed inside a system.
In the next post, we will look at what happens when model size, data, and compute continue to scale: why do capability boundaries sometimes shift suddenly? That is the question behind scaling laws and emergence.