06: Scaling Laws and Emergence: Why Scale Changes Capability Boundaries
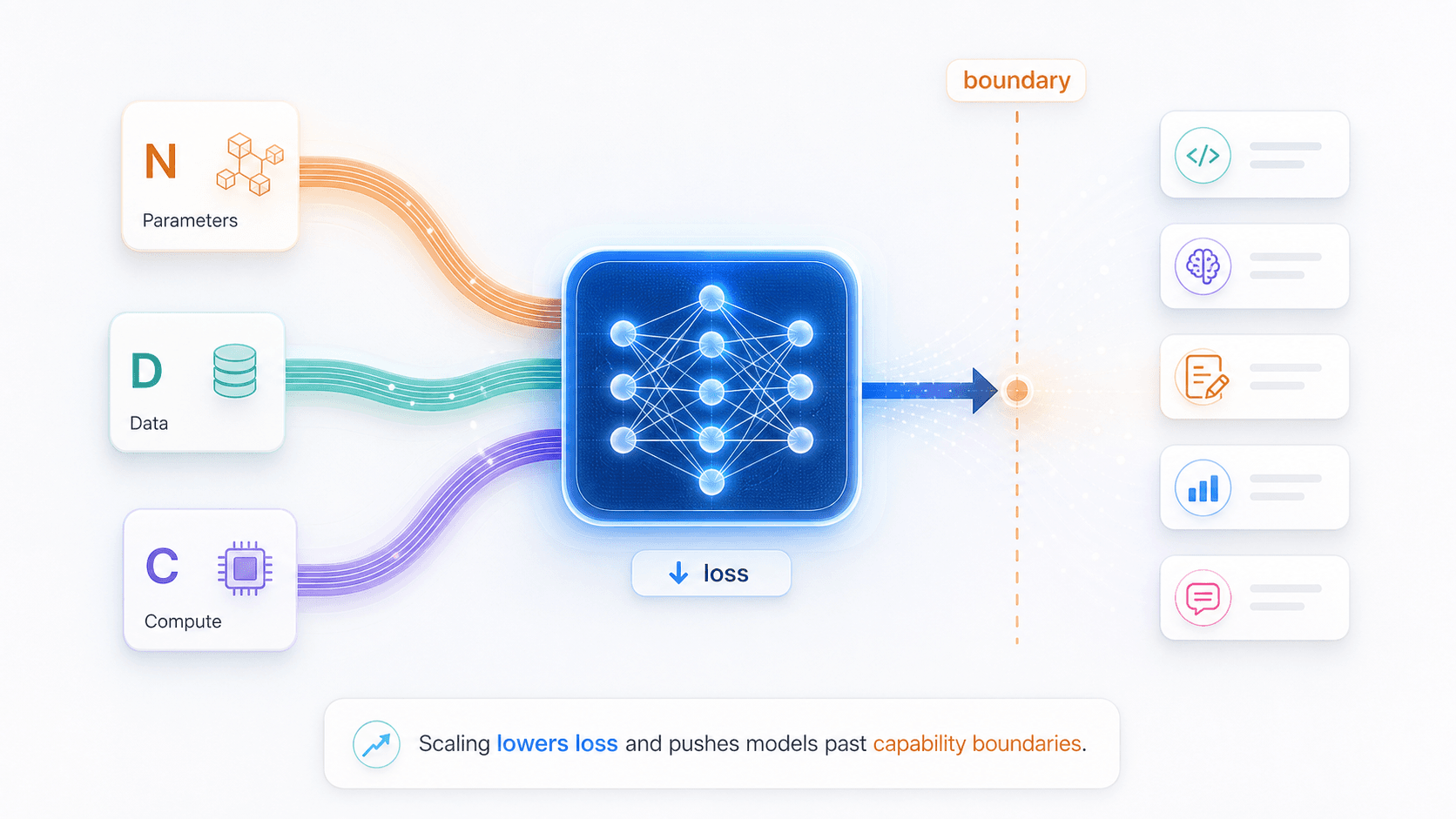
This is the sixth post in the “Understanding LLMs from First Principles” series. Post 05: Pretraining, Fine-tuning, and Alignment explained how a continuation system is shaped into an assistant. Now we ask the next question: if the underlying objective is still next-token prediction, why do larger models, more data, and more compute shift capability boundaries so dramatically? This post is about scaling laws and emergence.
Across the previous posts, we built one main thread:
Predicting the next token
is not merely memorizing answers.
It is compressing structures behind language.Post 05 added another layer:
Pretraining gives the model base capability.
Supervised fine-tuning teaches it to handle user instructions.
Preference alignment makes it behave more like a reliable assistant.
System engineering connects it to context, tools, and product experience.But one important question remains:
Why does scale matter so much?If a model is smaller, does it simply know fewer facts?
If a model is larger, does it simply memorize more?
If that were the whole story, the difference created by scale would look like a larger bookshelf: a few more books, a few more facts, a few more supported topics.
But the real effect is subtler.
When model scale increases, what changes is often not one isolated fact, but the boundary of tasks the model can handle:
It used to almost answer; now it answers reliably.
It used to imitate format; now it understands constraints.
It used to write fragments of code; now it can finish small programs.
It used to repeat steps; now it can decompose problems.
It used to handle short context; now it can maintain goals across paragraphs.That is what this post tries to explain:
Scale does not install a list of new features into the model. It keeps lowering prediction error until more tasks cross the threshold of usability.
1. The Intuitive Question: Why Does “Bigger” Become More Than “A Bit More”?
Start with a common observation.
When a small model and a large model face the same task, the difference is sometimes not:
The small model answers less.
The large model answers more.It is more like:
The small model misses the task.
The large model suddenly seems to get it.For example, the user says:
Turn the complaint below into a customer-support ticket title.
Keep it under 20 words, preserve the core request, and avoid emotional wording.This is not an advanced research problem, but it contains several layers of constraint:
Understand the original text.
Identify the core request.
Rewrite it as a title.
Control the length.
Remove emotional wording.
Preserve information a support team can act on.A weaker model may drop some of those layers.
It may summarize too long, keep emotional words, produce an explanation instead of a title, or latch onto surface words only.
A stronger model does not necessarily know a new fact. It is simply more likely to hold all those constraints at once.
That is what a capability boundary means.
Many tasks are not one piece of knowledge. They require several structures to remain valid at the same time:
semantic understanding
+ constraint following
+ format transformation
+ goal preservation
+ common-sense judgment
+ long-range consistencyIf one link fails, the user experiences the whole thing as “the model cannot do it.”
As model scale, data, and training compute increase, the model does not only memorize more facts. It develops more stable internal representations in more places.
Tasks that were previously “almost there” can suddenly become “usable.”
This is the key connection between scaling laws and emergence.
2. What Scaling Laws Actually Say
In the context of large language models, scaling laws describe an empirical pattern:
When parameter count, training data, and compute increase in a reasonable balance,
prediction error on held-out data tends to decrease along relatively smooth and predictable curves.The key metric here is not how well the model memorizes the training set. It is prediction error on held-out data, often discussed as test loss.
Roughly speaking, loss measures:
How far the model's next-token prediction is from the actual next token.Lower test loss means the model assigns higher probability to the true next token even on samples it was not directly trained on. It also means the model is modeling the language distribution with better generalization.
Power-law improvement also implies diminishing returns. Scaling still helps, but each further unit of loss reduction usually requires more data, parameters, and compute than the previous one.
But loss is not the same thing as the user’s direct feeling of intelligence.
Users do not say:
This model's loss dropped by 0.05, so the experience is great.They feel things like:
Did it understand my intent?
Did it miss a constraint?
Did it invent a fact?
Can it write runnable code?
Can it keep context in a long conversation?
Can it stay stable in edge cases?So what connects loss with these abilities?
The first-principles answer is:
When next-token prediction error decreases,
the model has better representations of context, meaning, facts, formats, reasoning paths, and task patterns.To predict text more accurately, the model must compress more of the structure behind text.
It cannot only memorize word co-occurrence. It must gradually learn:
which word is reasonable in the current situation;
which variable affects the next step;
which format should continue;
which code fragment would create a syntax error;
which conclusion contradicts the premise;
which answer fits the user's role and task goal.So scaling laws do not mean “larger models memorize more books.”
A better way to say it is:
Scale keeps lowering prediction error, and lower prediction error forces the model to learn deeper, more reusable structure.
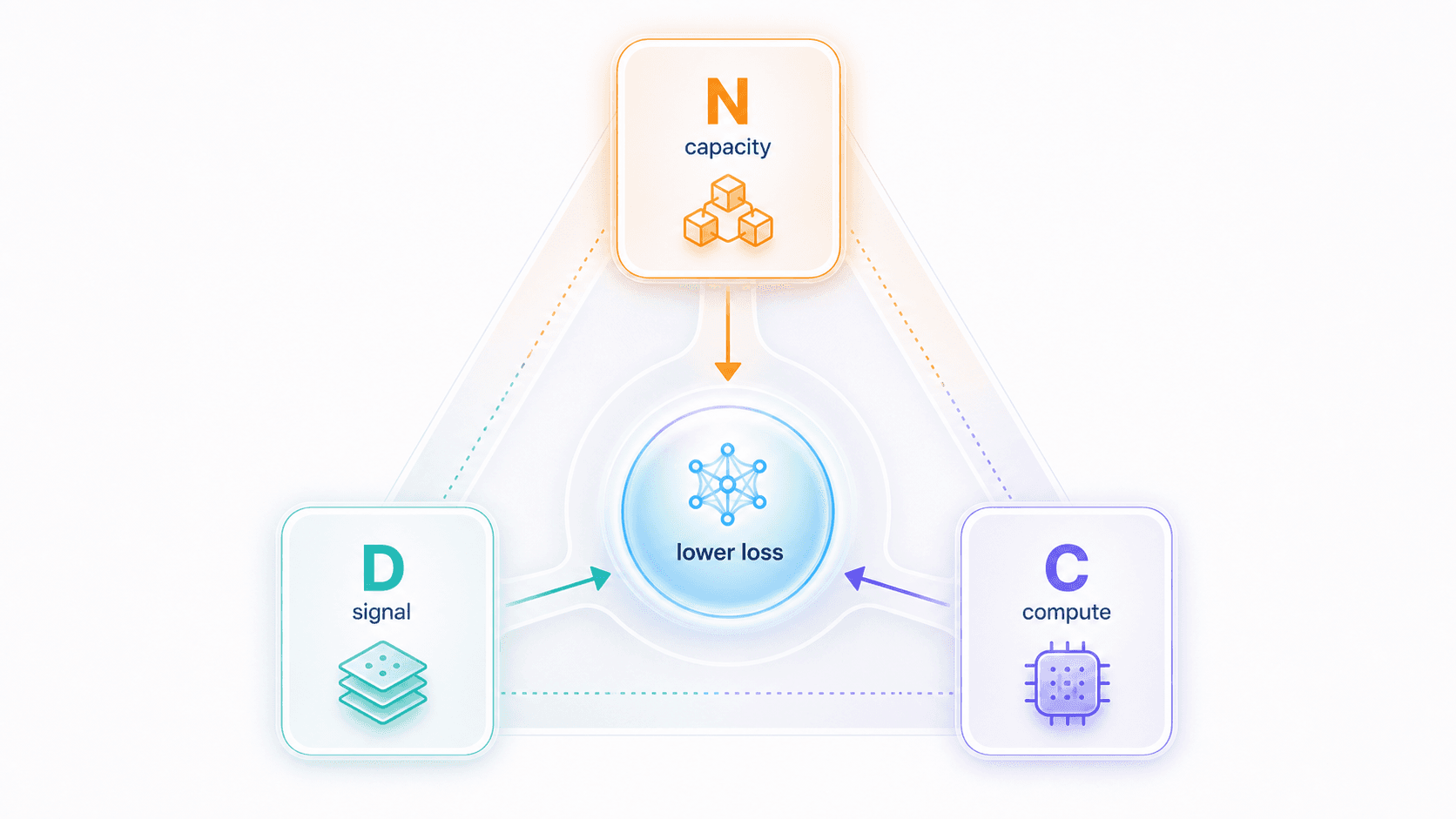
3. Scale Is Not Just More Parameters
When people talk about scale, the first thought is often:
More parameters make the model stronger.That is only partly true.
For large models, scale has at least three key dimensions:
Parameters: how much learnable structure the model can carry.
Data: how much signal training can provide.
Compute: how many opportunities the model has to learn those signals.These dimensions cannot be understood in isolation.
If there are too few parameters, a model may not have enough capacity to hold complex structure, even with plenty of data.
If there is too little data, a model with many parameters may memorize local patterns instead of generalizing.
If compute is too limited, the model may not have enough training time to compress those structures into parameters.
So the more useful view is:
Parameters provide capacity.
Data provides signal.
Compute pays the learning cost.All three have to grow together for a model to keep moving down the scaling curve.
This matters for first-principles reasoning.
Model capability is not determined by one variable.
It is more like a triangle:
The model needs enough capacity.
The training data needs enough coverage.
The training process needs enough compute.
Together, they push prediction error down.If one corner is badly missing, scale will not turn into capability.
That is also why two models can both be called “large models” while feeling very different in practice.
One may have many parameters, but weak data quality, training recipe, post-training, context handling, or tool integration. The user experience can still be unstable.
Another may not be the largest model, but with better data, training, alignment, and product systems, it can be more reliable for a specific task.
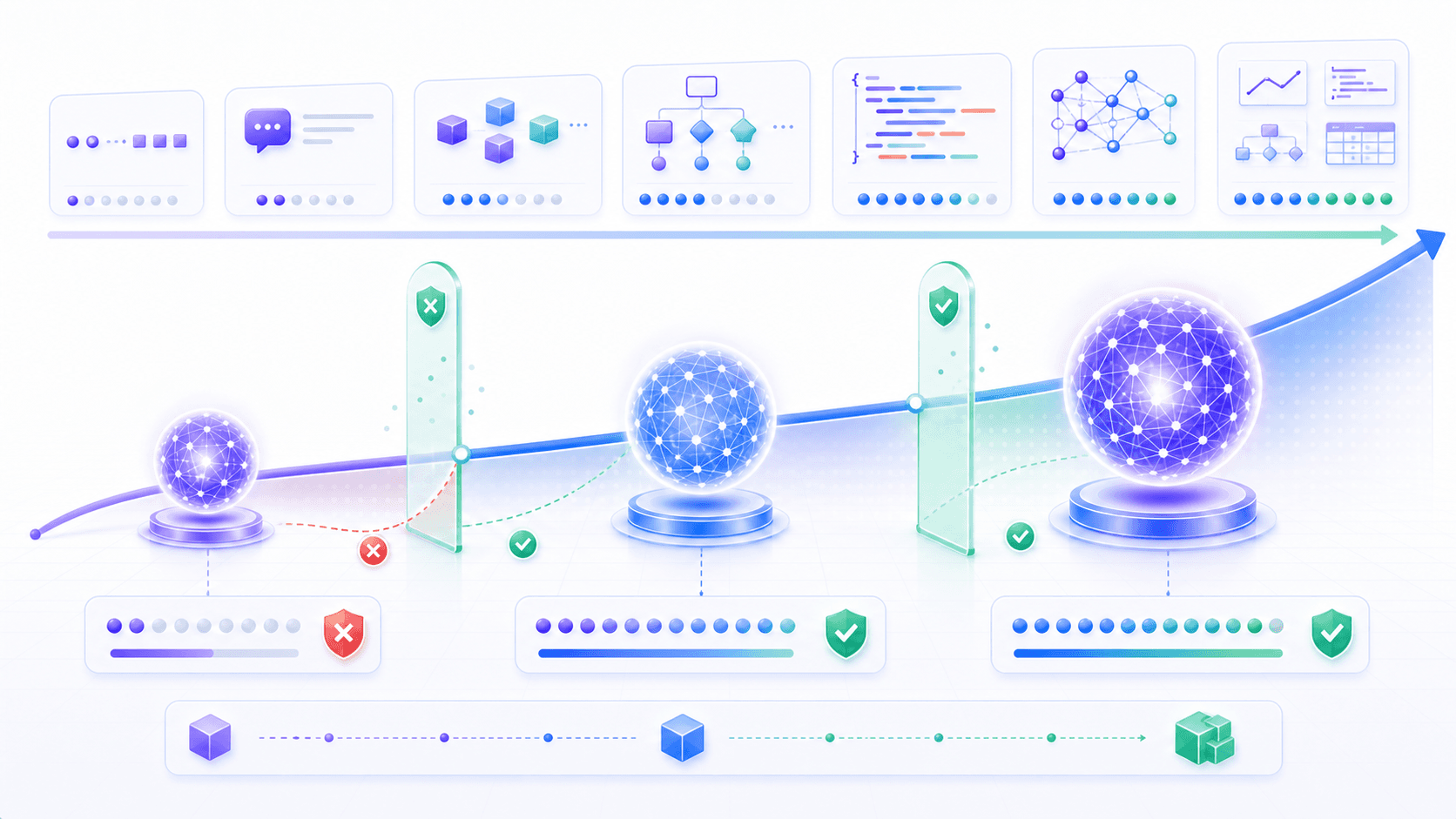
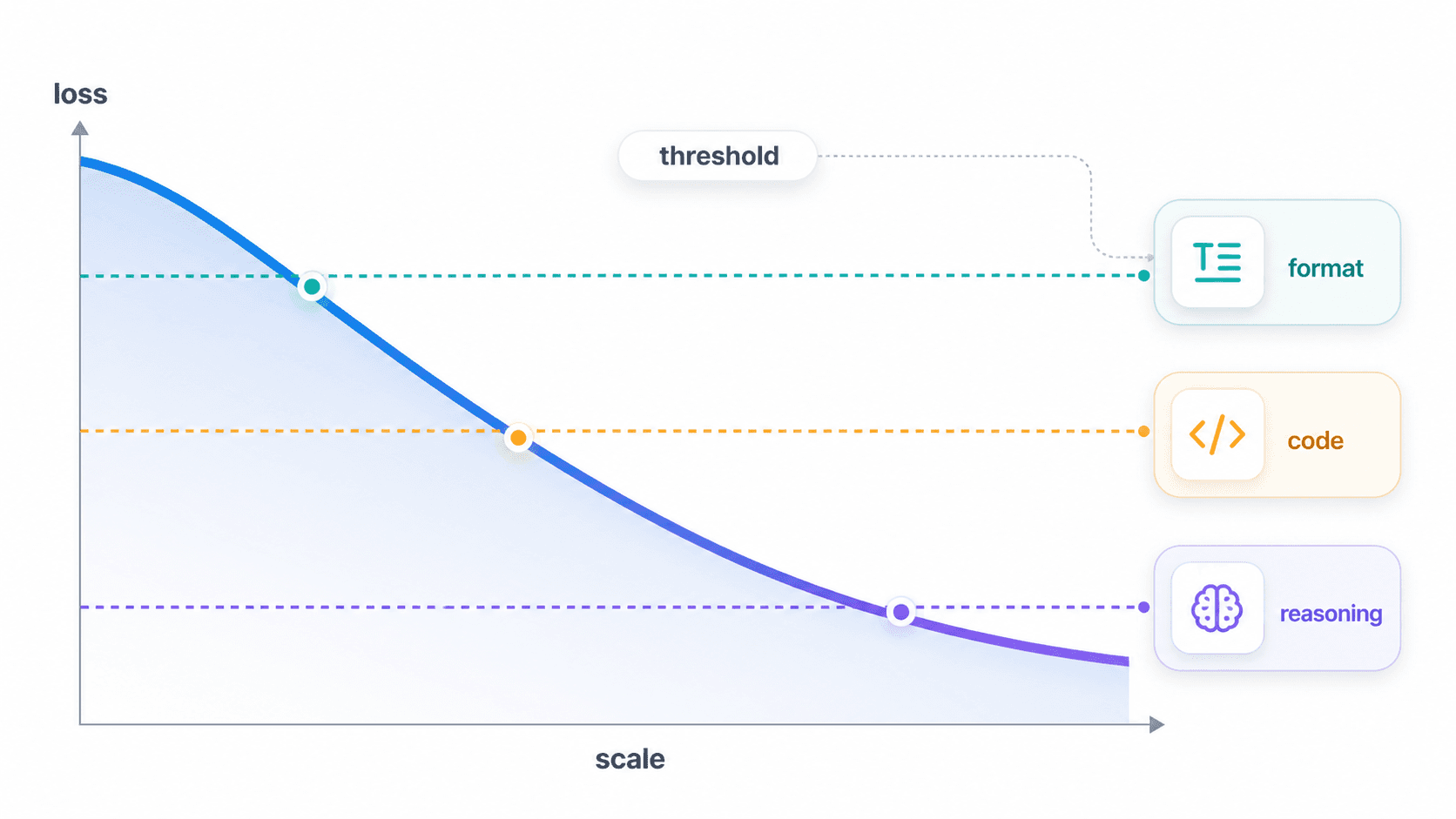
4. Emergence Is Not Magic. It Is a Threshold Being Crossed
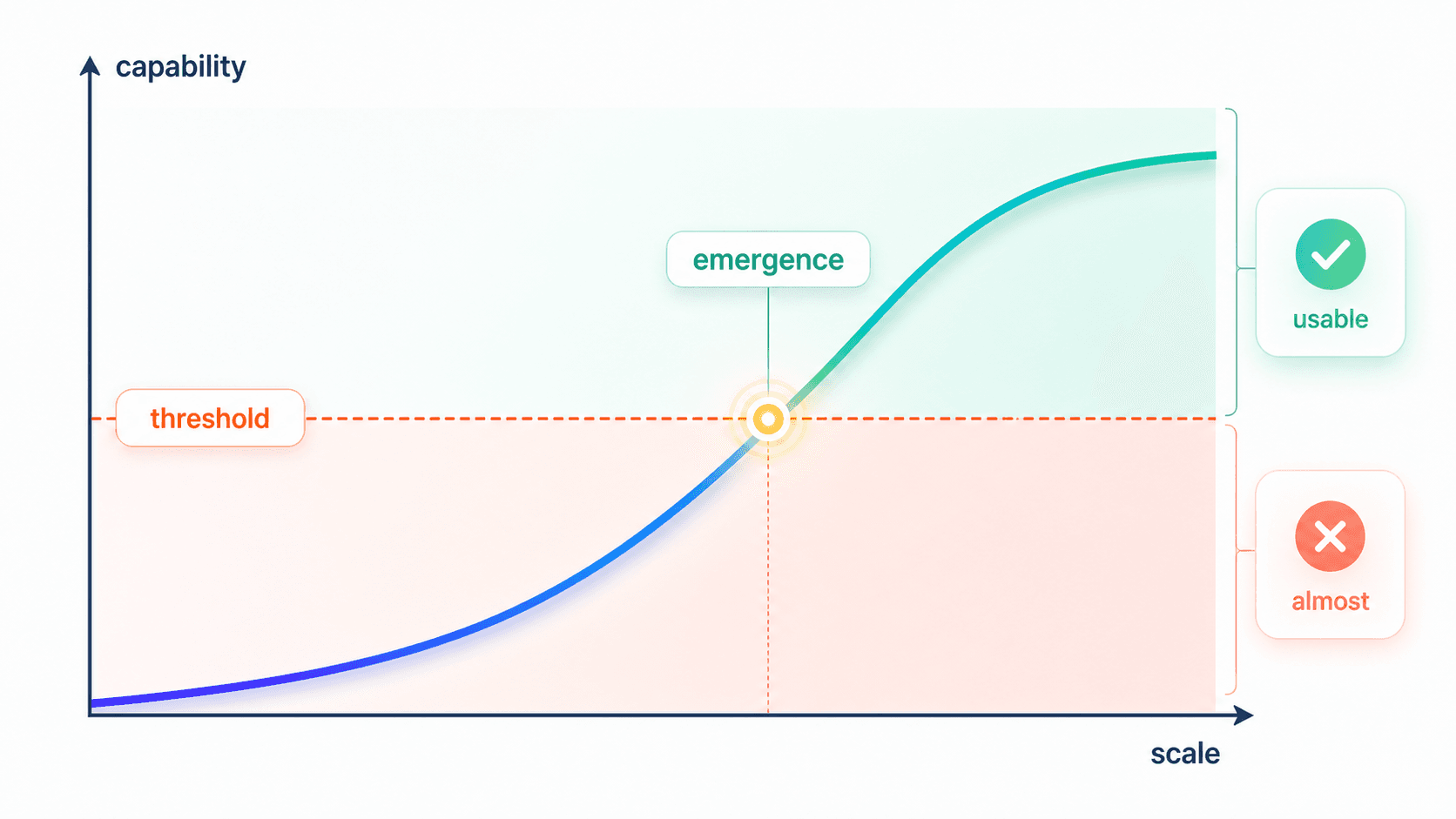
Now we can talk about emergence.
When people hear “emergent ability,” it is tempting to imagine that a model suddenly grows a new organ at a certain size.
For example:
Below this parameter count, it cannot reason.
Above this parameter count, it suddenly can.That sounds dramatic, but it can be misleading.
From first principles, much of emergence is better understood as:
The underlying capability improves continuously.
The external task is measured discretely.
When continuous capability crosses the task threshold,
we finally observe the model as "able to do it."Consider three-digit addition.
The model has to coordinate:
digit position;
carry rules;
step order;
output format;
intermediate errors not spreading.When the model is weak, it may answer correctly 40% of the time.
From the user’s perspective, that is still “cannot do it,” because it is unreliable.
As scale improves, it may move to 60%, 80%, and then 95%.
If a benchmark only records whether the task reaches a usable standard, the curve can look like a sudden jump.
But internally, the model may not have suddenly grown a new module.
More likely, a continuously improving representation finally crossed a visible task threshold.
Code generation works the same way.
A model that is almost good enough may write code that looks plausible but does not run.
After further reducing prediction error, it becomes more stable at satisfying syntax, APIs, variable names, edge cases, and the task goal.
The user does not see:
The loss moved down a bit.The user sees:
This code runs now.That is why emergence feels sudden.
Task outcomes are often discrete:
Does it run?
Is it correct?
Did it follow the format?
Did it complete the task?
Can the user use it directly?But the model quality behind those outcomes may have been changing relatively smoothly.
So we can summarize it this way:
Emergence is not magic. It is continuous model improvement crossing the usability threshold of a discrete task.
There is still an active debate about emergence. Some work treats certain capabilities as real phase-transition-like jumps. Other work argues that many apparent jumps come from discrete metrics and measurement choices. This post uses the more conservative frame: underlying capability often improves continuously, while discrete tasks, thresholds, and benchmarks create the feeling that the model “suddenly” learned something.
5. Why Scale Changes Capability Boundaries
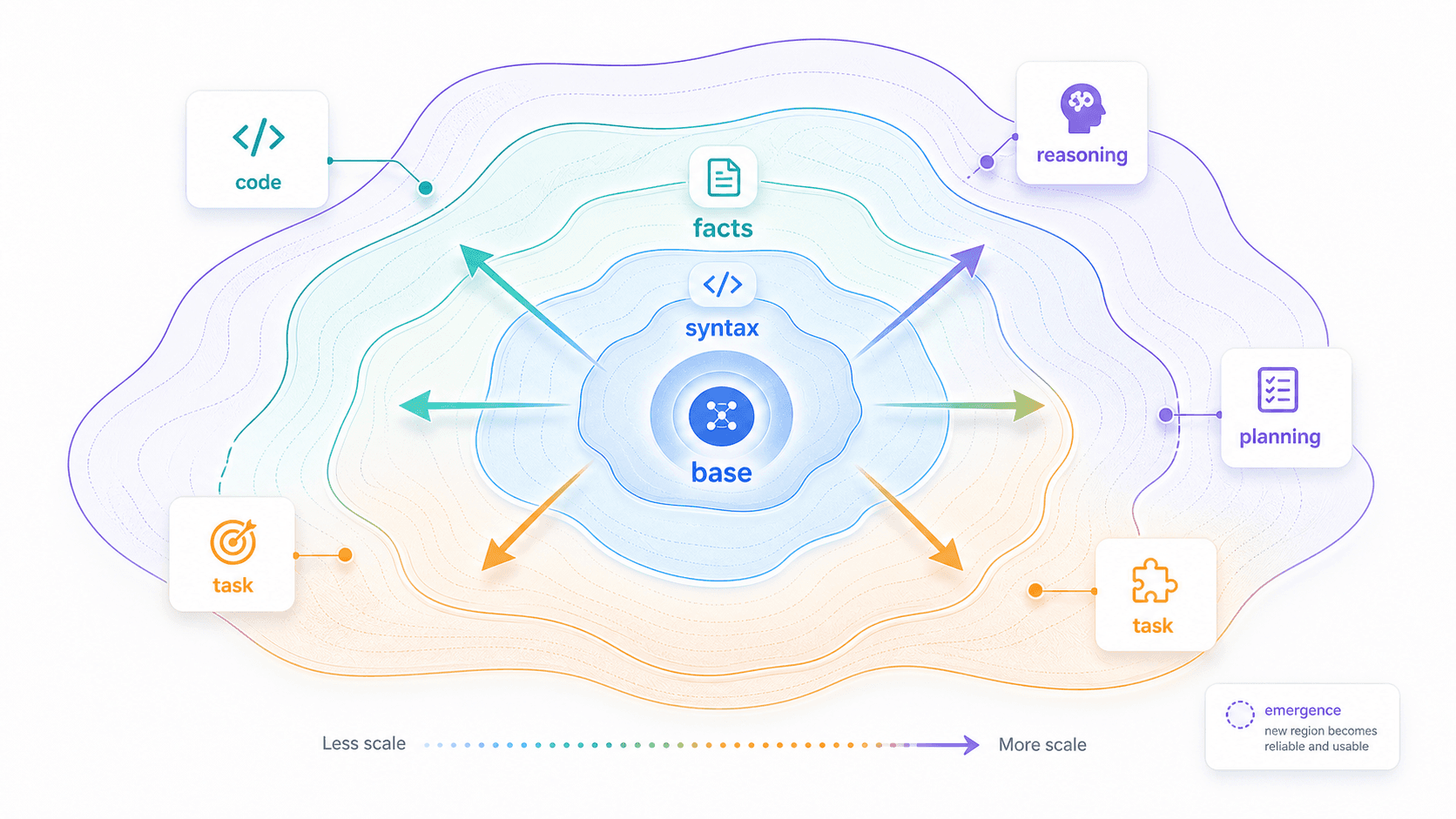
Now we can answer the central question:
Why does scale change capability boundaries?Because many advanced tasks require the model to compress and coordinate more structures at the same time.
Writing code, for example, is not only knowing a function name.
It requires the model to represent:
user intent;
program structure;
language syntax;
library usage;
relationships between variables;
edge cases;
error patterns;
output constraints.Multi-step reasoning is not only knowing one fact either.
It requires the model to represent:
the current goal;
known conditions;
intermediate state;
possible next paths;
which paths conflict with the premise;
how the final answer should be expressed.Small models may learn some local patterns.
But when a task requires many structures to compose at once, they are more likely to fall apart.
As scale increases, the model has more capacity to carry reusable structures and more training signal to calibrate the relationships between them.
The capability boundary moves outward:
from word association to syntax;
from common facts to abstract concepts;
from one-step imitation to multi-step transformation;
from short-context consistency to long-context goal preservation;
from local code snippets to runnable program structure;
from simple Q&A to complex task decomposition.This does not mean scale automatically solves every problem.
Larger models can still fail.
But scale raises the structural complexity that a system can handle reliably.
You can imagine a model’s capability boundary as a map.
Inside the map, tasks are relatively stable. Near the edge, the model may sometimes succeed and sometimes fail. Outside the map, it starts fabricating, missing constraints, looping, or being confidently wrong.
Scaling laws expand the map.
Emergence is when users first see a new region become usable.
6. The Boundary of Scale: Why Larger Still Does Not Mean Reliable

At this point, it is easy to fall into another misunderstanding:
If scale works, then a large enough model will make all problems disappear.No.
Scale expands capability boundaries, but it does not change the underlying objective:
Given context, predict the next token.Several boundaries remain.
1. Larger Does Not Mean Knowing the Latest State of the World
The model learns world structure from training data, but after training, it does not automatically know what happened today.
If a question depends on fresh information, private data, real-time state, or internal company processes, scale cannot replace retrieval, databases, or tools.
2. Larger Does Not Mean No Hallucination
Larger models are often better at organizing language and generating plausible explanations.
That is both a strength and a risk.
When evidence is missing, the model can still generate fluent but wrong content.
Because the writing is more natural, the error can be harder for users to notice.
3. Larger Does Not Mean Stable Business Constraints
Business systems often need determinism:
amounts must not be wrong;
permissions must not be crossed;
formats must be parseable;
compliance boundaries must not drift;
tool calls must be traceable.These cannot be guaranteed by scale alone.
They require system prompts, output constraints, retrieval, tools, validators, permission systems, and evaluation loops.
4. Larger Does Not Mean Better Product Experience
A larger model often also means:
higher cost;
higher latency;
more complex deployment;
harder debugging;
less predictable boundary behavior.Real products do not simply choose “the strongest model.” They choose the system combination that reliably crosses the target task threshold.
That is why small models, domain models, RAG, tool use, and workflows remain important.
Scale is the foundation of capability, but reliable experience comes from the system.
7. Common Misunderstandings
Misunderstanding 1: Emergence means the model suddenly became conscious.
No. Emergent abilities usually mean the model’s representation for a task crossed a visible threshold. That is not the same as subjective experience or consciousness.
Misunderstanding 2: Scaling laws mean you only need more parameters.
No. Parameters, data, and compute need to be balanced. Data quality, training recipe, post-training, and system engineering also strongly shape final capability.
Misunderstanding 3: Small models have no value.
No. Many tasks do not require a very high capability boundary. Classification, rewriting, extraction, routing, simple support, and structured output may be faster, cheaper, and more controllable with small models.
Misunderstanding 4: If a benchmark suddenly improves, the ability was born instantly.
Not necessarily. Many benchmarks use discrete scoring. The underlying capability may have improved continuously and only crossed a scoring threshold at that point.
Misunderstanding 5: A larger model always creates a better product.
Not necessarily. Product quality depends on the task, cost, latency, reliability, context, tools, evaluation, and interaction design. The model is one part of the system.
8. What This Means for Products and Engineering
Once we understand scaling laws and emergence, AI product decisions become less mystical and less dismissive of scale.
1. First Ask Whether the Task Is Inside the Model’s Capability Boundary
If the task is outside the model’s boundary, a longer prompt usually only makes the failure look more polished.
For example, if the model cannot reliably reason over complex tables, adding more tone instructions may still leave it missing rows, missing columns, or calculating incorrectly.
In that case, consider:
using a stronger base model;
breaking the task into smaller steps;
introducing tools for computation;
using retrieval to add context;
checking outputs with validators;
moving high-risk steps into deterministic programs.2. Choose Models by Whether They Reliably Cross the Threshold
Do not only look at average leaderboard scores.
Products care about:
whether the target task is stable;
whether edge cases are stable;
whether errors are detectable;
whether failures are recoverable;
whether cost and latency are acceptable.If a small model already crosses your business threshold reliably, it may be better than a larger general model.
If a large model has a higher average score but fails in critical edge cases, the product risk is still high.
3. Evaluate Margin, Not Only One-Time Success
There is a large gap between “sometimes works” and “reliably usable.”
So evaluation should not only ask:
Did it pass this time?It should also ask:
Does it pass when phrased differently?
Does it pass with noise?
Does it pass when context gets longer?
Does it stay stable when constraints conflict?
Is it consistent across ten repeated calls?That is the margin around the capability boundary.
4. Scale Solves Base Capability. Systems Solve Reliable Delivery.
Scale can push more tasks into the usable region, but a product that users can trust usually needs system engineering too.
RAG solves freshness and traceability.
Tool use solves calculation, lookup, and execution.
Workflows solve long-task stability.
Permission systems solve boundary risk.
Evaluation sets catch regressions.
Interaction design helps users express and confirm intent.Do not treat the model as the whole product. Do not ignore the model’s capability boundary either.
Good AI products often start with a model of the right scale, then add the right context, tools, constraints, and feedback.
9. Technical Appendix: MoE Changes the Relationship Between Total Scale and Activated Scale
When discussing scale, one important architecture appears often: MoE, or Mixture of Experts.
In a traditional dense model, most parameters are activated during each inference step. MoE has a different intuition: the model contains many expert networks, and each token is routed to only a subset of them.
This creates an important distinction:
total parameters: how much capacity and pattern storage the whole model has;
active parameters: how many parameters actually participate in one generation step.The value of MoE is that it can increase total parameter count, giving the model more capacity, while controlling the number of active parameters per token so inference cost does not grow linearly with total parameters.
But MoE is not free. It introduces routing, load balancing, expert utilization, training stability, and deployment complexity. The product takeaway is this: “scale” is not only about bigger parameter counts. It is also about which parameters activate when, and whether that activation pattern can serve real requests reliably and cheaply.
10. Summary: How Scale Changes Capability Boundaries
We can compress this post into a few lines:
Scaling laws show that when parameters, data, and compute grow in balance, prediction error tends to decrease smoothly.
Lower prediction error means better compression of language and world structure.
Many tasks have discrete usability thresholds.
When continuous improvement crosses those thresholds, users see abilities that look sudden.
That is the source of many emergent behaviors.If we compress it into one sentence:
Scale is not magic. It lowers prediction error through parameters, data, and compute; emergence is not something appearing from nowhere, but continuous capability crossing a task’s usability threshold.
Once we understand this, we do not need to mystify large language models, but we also should not reduce them to “fancy autocomplete.”
They are still predicting the next token.
But when that prediction system is pushed to new boundaries by enough scale, enough data, and enough compute, it starts to reliably complete tasks it could not handle before.
11. Three Questions You Should Be Able to Answer
After reading this post, try answering these in your own words:
- Why can capability improvement be continuous while the user experience feels sudden?
- Why does a larger model not automatically mean a more reliable product?
- Why does MoE make us distinguish total parameters from active parameters?
In the next post, we will look at what actually happens during generation: temperature, context windows, sampling, and why large language models always output one token at a time.