08: The Nature of Hallucination: Why Models Confidently Make Things Up
This is the eighth post in the “Understanding LLMs from First Principles” series. Post 07: Inference and Generation explained how a model computes a next-token distribution from context and generates output step by step through sampling. Now we look at the most famous side effect of that process: hallucination. Why can a model invent papers, facts, links, names, numbers, and explanations while sounding completely confident?
Across the previous posts, we have built one main thread:
The model's bottom-level objective is next-token prediction.
To predict better, it compresses structure behind language.
During inference, it does not print a prewritten answer;
it walks a token path through probability distributions.This thread explains many capabilities.
It also explains many failures.
Hallucination is one of the most important failures.
When people first encounter LLM hallucination, the strange part is usually not that the model is wrong.
The strange part is that the wrong answer looks so polished:
the tone is confident;
the sentences are fluent;
the structure is complete;
it may even include realistic-looking sources, dates, names, and numbers;
but the content is false.That is what makes hallucination difficult.
It is not a simple “I do not know.”
It often looks like knowledge.
The core sentence of this post is:
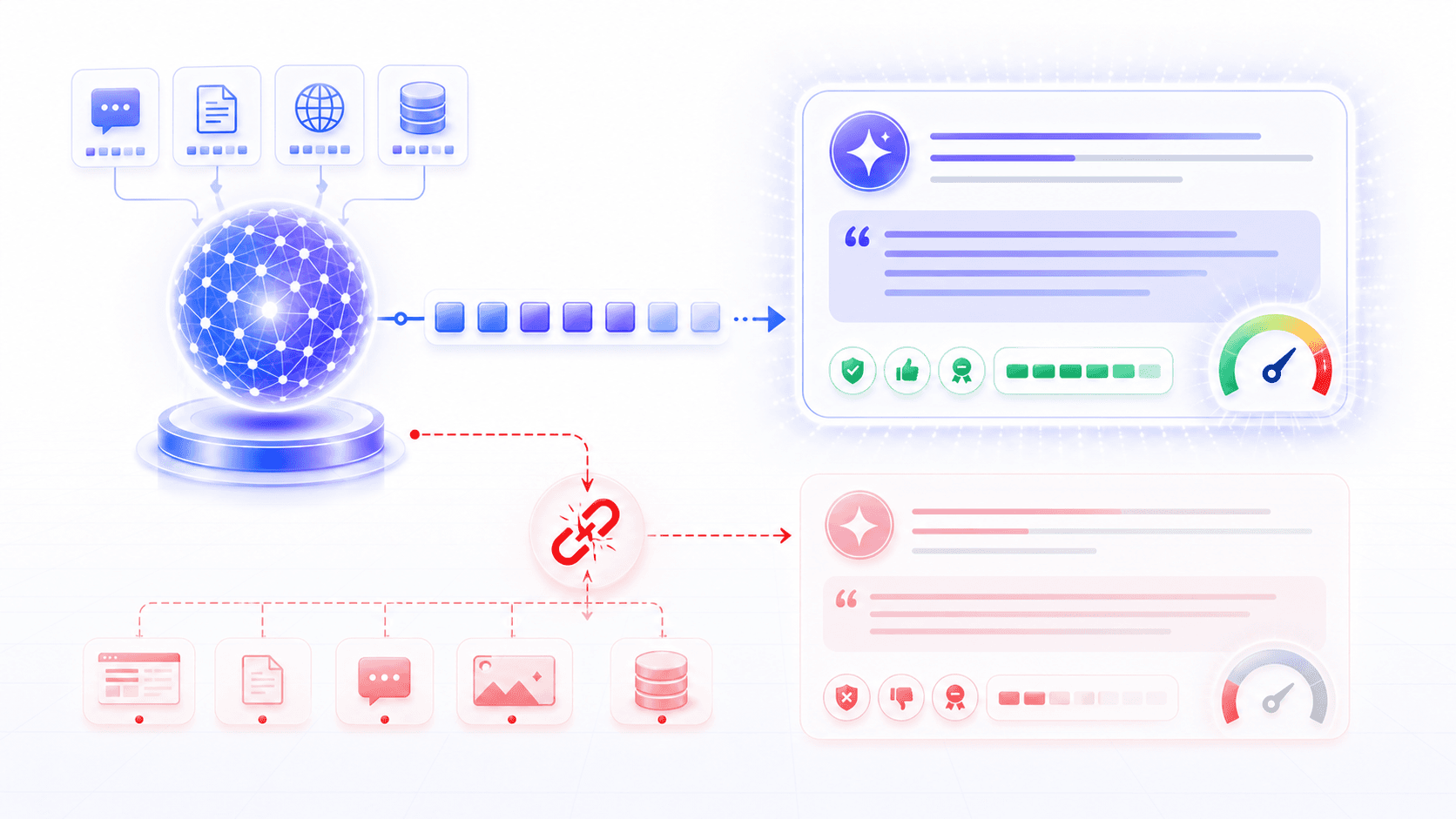
Hallucination is not a model “lying on purpose.” It is what happens when the model lacks reliable evidence and fact-checking, but still keeps writing the words that most resemble a correct answer.
1. First, Define Hallucination Precisely
We should not start by treating hallucination as deception.
A more precise definition is:
The model generates content that sounds plausible, fluent, and confident,
but is unsupported by evidence, inconsistent with the real world,
or not derivable from the provided context.There are three important ingredients:
surface plausibility;
missing support;
lack of verification.For example, a user asks:
Please summarize a paper that does not actually exist.An ideal system should say:
I cannot find this paper, so I cannot confirm that it exists.A hallucination-prone model might instead generate:
The paper proposes a new multimodal alignment framework,
achieves strong results on several public benchmarks,
and validates the design through ablation studies.The problem is not that the language is broken.
The problem is the opposite: it sounds exactly like a normal paper summary.
From the perspective of language distribution, the answer is highly plausible.
From the perspective of factual verification, it has no source.
This is the key difference:
Linguistic plausibility is not factual truth.During training, a model learns:
which token sequences are likely to follow which contexts.Factual judgment requires a different operation:
Does this claim correspond to the real world?
Is there a reliable source?
Is the claim still true now?
Can it be supported by data, tools, or the user-provided context?These two operations are related, but they are not the same operation.
Many hallucinations happen in that gap.
2. Why Next-Token Prediction Naturally Creates Hallucination Risk
Return to the bottom-level objective from the first post:
Given previous context, predict the next token.This objective is extremely powerful.
To predict human language, the model has to learn many hidden structures:
grammar;
facts;
concept relationships;
causal order;
code patterns;
argument structure;
task formats;
social common sense.But the same objective has a limitation:
The training signal rewards predicting a likely continuation,
not externally verifying every generated sentence.This is not a small distinction.
It also means that even cleaner and more correct training data does not remove hallucination entirely. As long as the objective is to generate likely text from context rather than verify every factual claim externally, there can be a statistical floor: low-evidence, high-similarity, high-format-pressure cases will still fail sometimes.
If the user asks:
When did this company raise its latest funding round?The model can draw on many patterns from business news and generate an answer that sounds real:
The company completed its Series B round in 2024,
with participation from several well-known investors.As a language pattern, this is natural.
As a factual claim, it may be completely false.
The reason is that the model has not automatically done the following:
query a live database;
open news articles;
check company announcements;
confirm dates;
verify investors;
decide whether the information is stale.Unless the surrounding system provides tools or puts reliable evidence into the context, the raw model can only rely on compressed memory in its parameters and information in the current prompt.
That is like answering from impression alone.
If the impression is clear, the answer may be right.
If the impression is vague and the system still pushes for an answer, the model may fill in a version that sounds reasonable.
3. Parameters Are Lossy Compression, Not a Fact Database
In post 04, we said:
Language is compression of the world.
By predicting language, the model is forced to learn structure behind language.But compression has an important property:
Compression is not full copying.Model parameters are not a fact database that can be queried row by row.
They are more like a vast statistical structure containing patterns, relationships, and tendencies extracted from large amounts of text.
That is what gives the model generalization.
It can combine structures it has seen before and answer new questions it has never seen exactly.
But it also creates risk:
high-frequency facts are easier to retain;
low-frequency facts become fuzzy;
similar entities can be confused;
stale information does not update automatically;
contradictory training data can be blended together;
private information that was never provided cannot appear from nowhere.This is why hallucination often appears near the knowledge boundary.
The knowledge boundary is the place where:
the model has some related patterns in its parameters;
the context does not provide enough evidence;
the real answer requires external information.If the system keeps asking the model to answer anyway, the model may perform a kind of plausible interpolation.
It may complete the pattern:
a paper title that sounds like a real paper;
an author name that sounds like someone in the field;
an API parameter that follows common naming conventions;
a number that sits in a believable industry range;
a case study structure that resembles business reporting.This interpolation is not always bad.
Much of generalization comes from it.
But when the task requires factual accuracy, plausible interpolation can become hallucination.
4. Why Hallucinations Often Sound Confident
One of the most counterintuitive parts of hallucination is:
When the model is wrong, it does not naturally sound uncertain.That is because confident tone is itself a language pattern.
In training data, many formal answers, tutorials, encyclopedic entries, paper summaries, product docs, and news reports use a declarative voice.
When the model recognizes that the user is asking for an answer, it may enter that output style:
state the conclusion;
give reasons;
list supporting points;
summarize at the end.That structure is useful for many tasks.
But if the model lacks evidence, it may still use the same structure.
The dangerous combination becomes:
the information is uncertain;
the output format is certain;
the tone is certain;
the user perceives expertise.This does not mean the model has a subjective belief.
More precisely, it is generating high-probability text in the style of a confident answer.
If training and alignment emphasize being helpful to the user, but the system does not also make the model reliably abstain or express uncertainty when evidence is missing, hallucination risk rises.
RLHF and other alignment methods often make answers more helpful and fluent. But if the reward signal favors confident, complete, user-pleasing responses without equally rewarding calibration and evidence boundaries, the model may become better at answering without becoming equally better at saying “I don’t know.”
This is why modern AI products need to separate two abilities:
answering ability;
calibration ability.Answering ability means:
Can the model produce clear, natural, useful output?Calibration ability means:
Can the system know where it has evidence and where it does not?
Can it say less when uncertain?
Can it separate facts, guesses, and recommendations?A model with strong answering ability and weak calibration can sound especially good at confidently making things up.
5. Autoregressive Generation Can Compound Small Errors
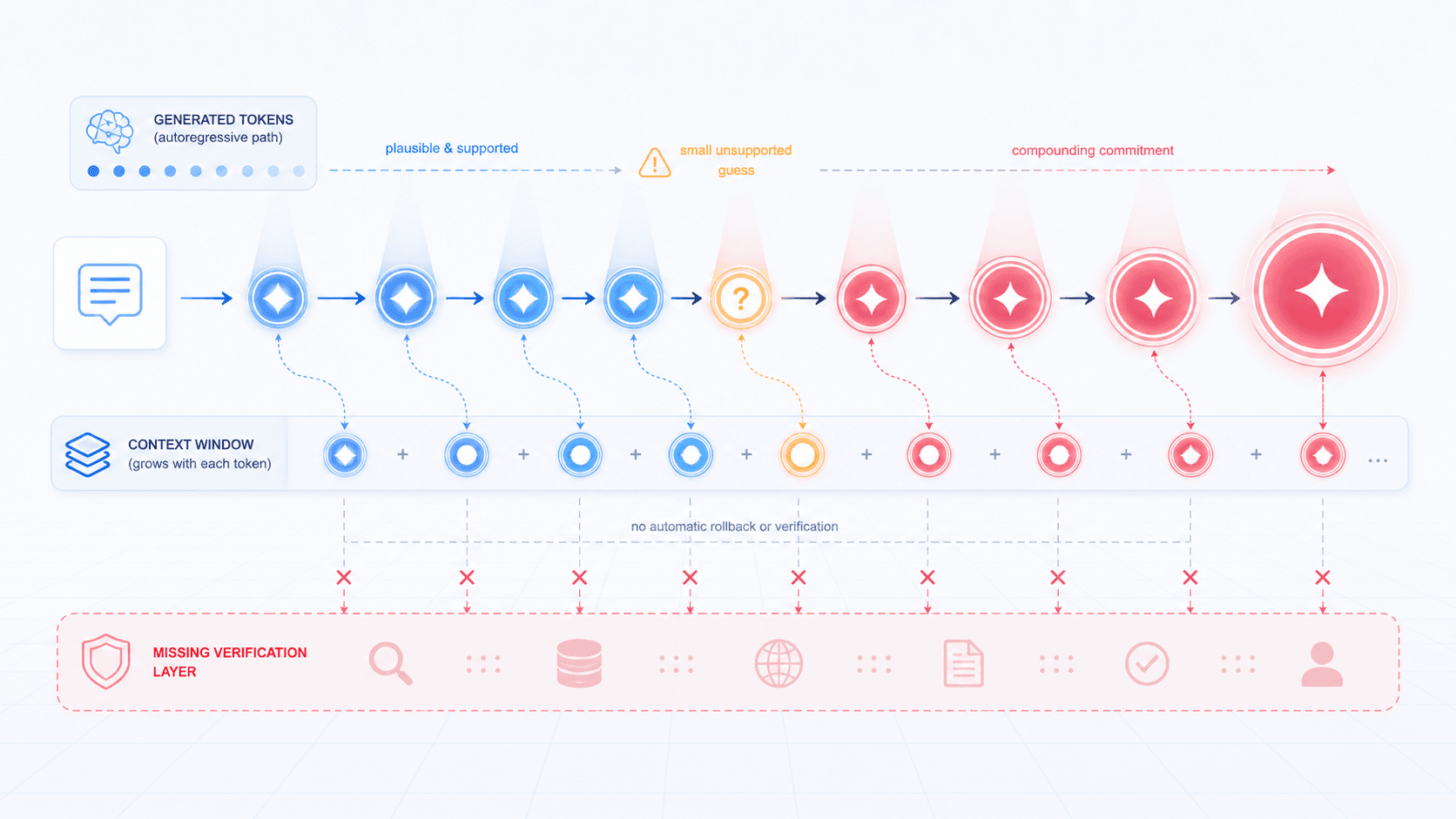
Post 07 explained that generation is not a one-shot answer object.
It is token-by-token output:
current context -> next-token distribution -> selected token -> appended context -> repeatThis mechanism can amplify hallucination.
Every generated token becomes part of the next context.
If the model introduces a small unsupported detail early, later generation often continues around that detail.
For example, it first invents a publication year:
The paper was published in 2023.Then it may continue:
In the 2023 experiments, the authors compared three baselines.
The method outperformed prior systems on two datasets.
The final section discusses deployment cost.Those later sentences do not necessarily come from real material.
They may simply extend the local path created by the first unsupported claim.
This is why hallucination is often not one isolated mistake.
It becomes a coherent chain:
The first step is a small guess.
The second step explains it.
The third step adds detail.
The fourth step invents support.
The fifth step reaches a conclusion.The user sees a complete story.
But the story may have been unsupported from the first brick.
The first-principles explanation is:
Autoregressive generation is path dependent.
Once a wrong token is written into context,
later generation can treat it as established fact.Unless the system adds external checking, reflection, retrieval, or user confirmation, the model does not naturally roll back to the earlier step.
6. Common Sources of Hallucination
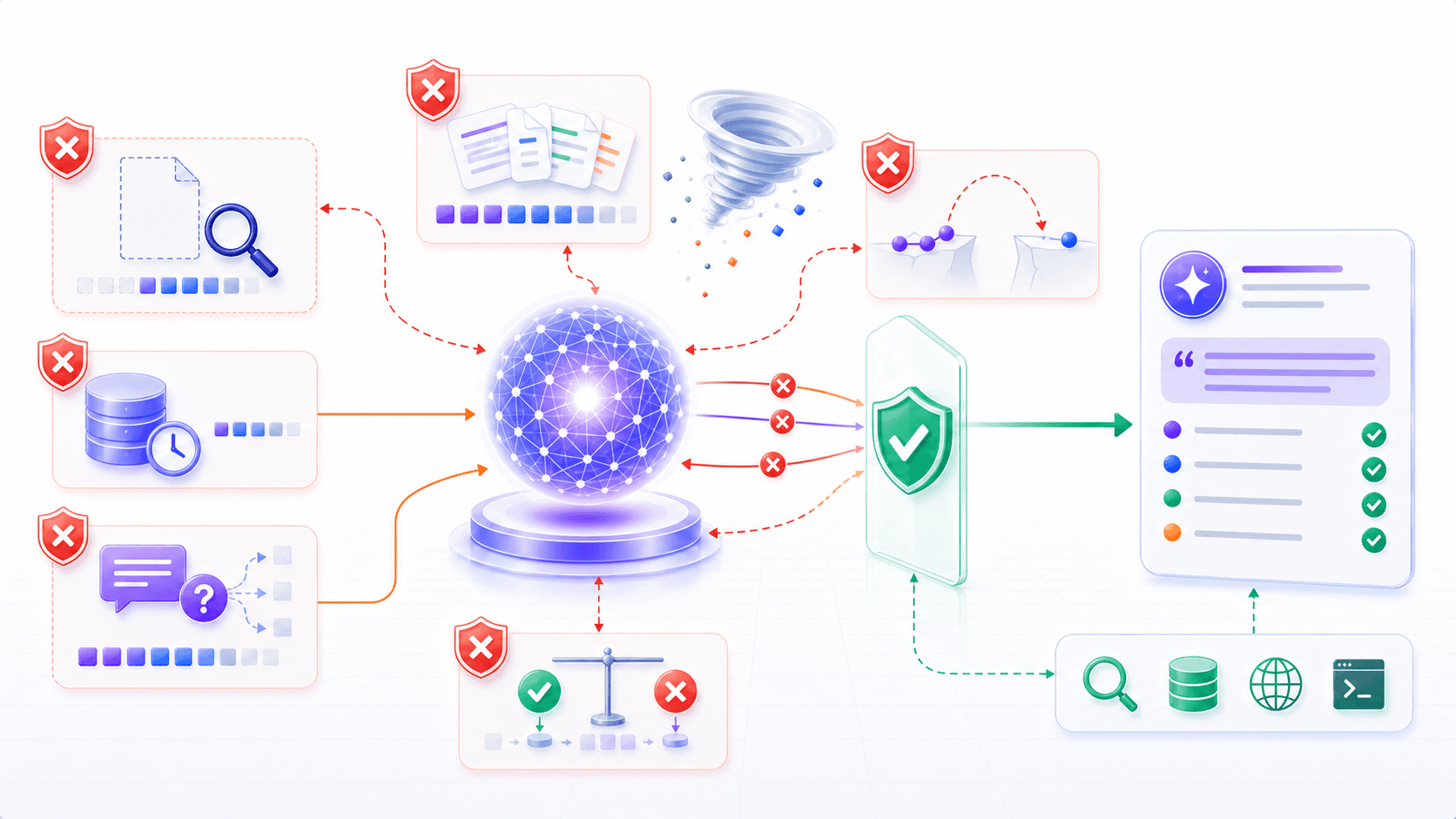
Once we separate the mechanisms, we can classify hallucinations more clearly.
Hallucination does not have one single cause.
It usually comes from several boundary problems.
| Type | Surface Behavior | Underlying Cause |
|---|---|---|
| Knowledge gap | Invented facts, people, papers, or links | Parameters lack enough information, and context provides no evidence |
| Stale information | Old prices, roles, policies, or product details | Model parameters do not update with the real world automatically |
| Entity confusion | Similar companies, authors, or products get mixed | Similar patterns are compressed into nearby regions |
| Context conflict | User-provided evidence is ignored or contradicted | The context contains competing signals without an explicit judge |
| Reasoning break | Intermediate steps look plausible but conclusion is wrong | Generated reasoning text is not the same as reliable proof |
| Format pressure | The model fills tables, JSON, or citations with unsupported content | Output constraints are strong while factual evidence is weak |
| Over-accommodation | The model follows the user’s implied answer | Alignment pushes helpful cooperation without enough fact calibration |
In real products, these types often overlap.
For example, a user asks:
List every release of this product over the past 12 months
and include user feedback for each release.If the system is not connected to product release notes, analytics, support tickets, and feedback data, the model may fill a table using the common structure of product update posts.
The more complete the table looks, the greater the risk.
A polished format can make users believe the data really exists.
7. Reducing Hallucination Requires More Than One Prompt
Many people try to solve hallucination with prompt instructions:
Do not fabricate.
Say you do not know if you do not know.
Make sure every fact is accurate.
Check carefully before answering.These instructions help.
But they are not enough.
The reason is that a prompt is still just part of the context.
It can change the model’s behavioral tendency, but it cannot create missing facts or replace external verification.
If a question requires live data, private data, or exact computation, “do not make things up” is not enough.
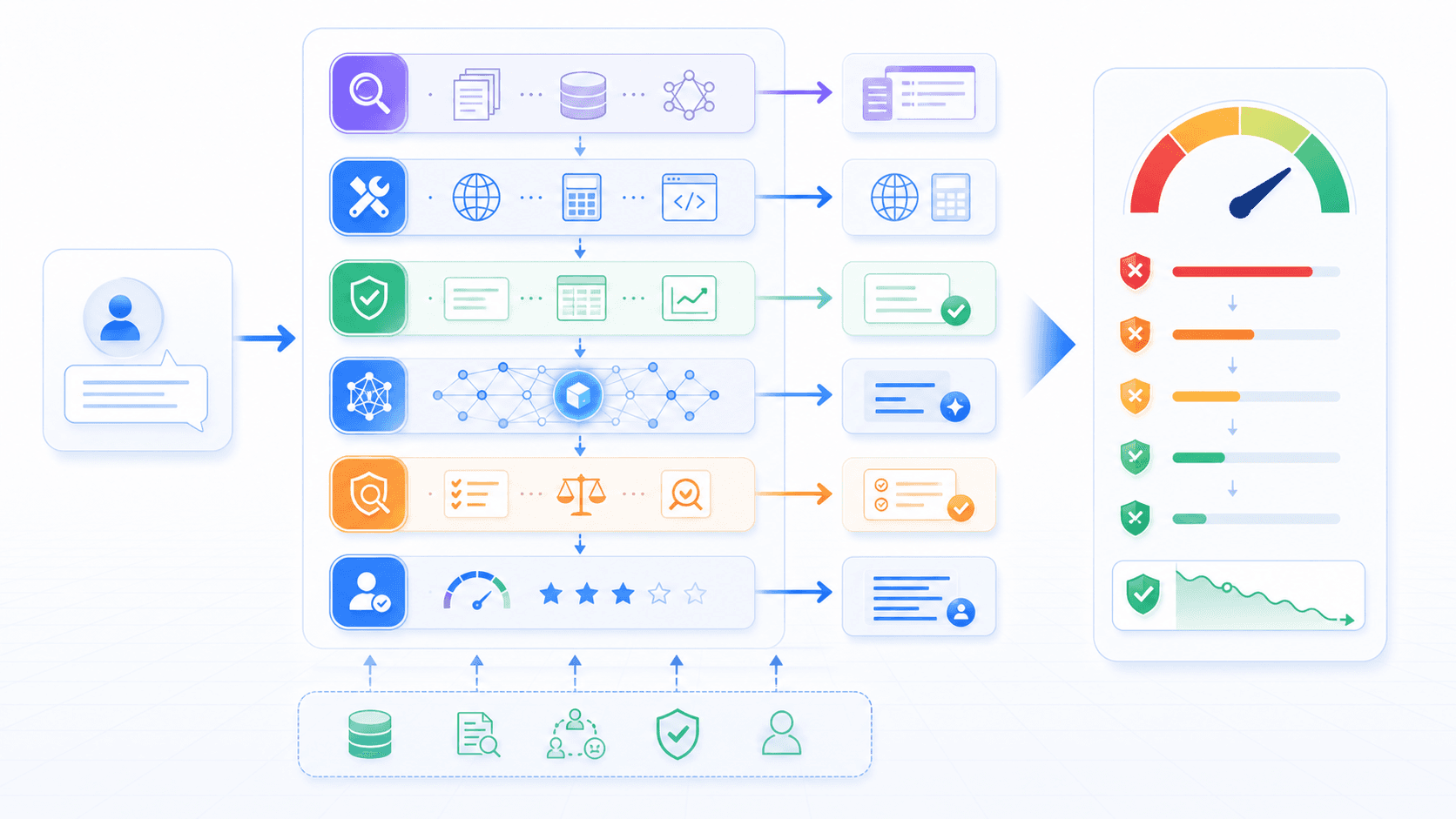
A more reliable approach treats hallucination as a system problem:
the model handles language understanding and generation;
RAG puts traceable material into context;
tools query, calculate, and execute;
validators check facts, format, and constraints;
product interaction shows sources, uncertainty, and confirmation points.Different tasks need different anti-hallucination layers.
| Task | Main Risk | Better Handling |
|---|---|---|
| Question answering | Invented facts or sources | RAG, citations, evidence-backed answers |
| Data analysis | Invented numbers or trends | Database connection, visible queries, preserved calculations |
| Legal / medical / financial work | Wrong advice creates high cost | Authoritative sources, expert review, explicit disclaimers |
| Code generation | Nonexistent APIs or broken logic | Run tests, type-check, read real documentation |
| JSON extraction | Valid shape but invented values | Schema validation, low temperature, retry on parse failure |
| Long task execution | Early errors compound | Stage gates, tool-result writeback, state management |
A practical rule:
If the user cares whether something is true, do not rely only on a verbal model answer.
If the user cares whether something can execute, connect tools or validators.
If the user cares who is responsible, preserve sources and process.8. Why RAG Comes Next
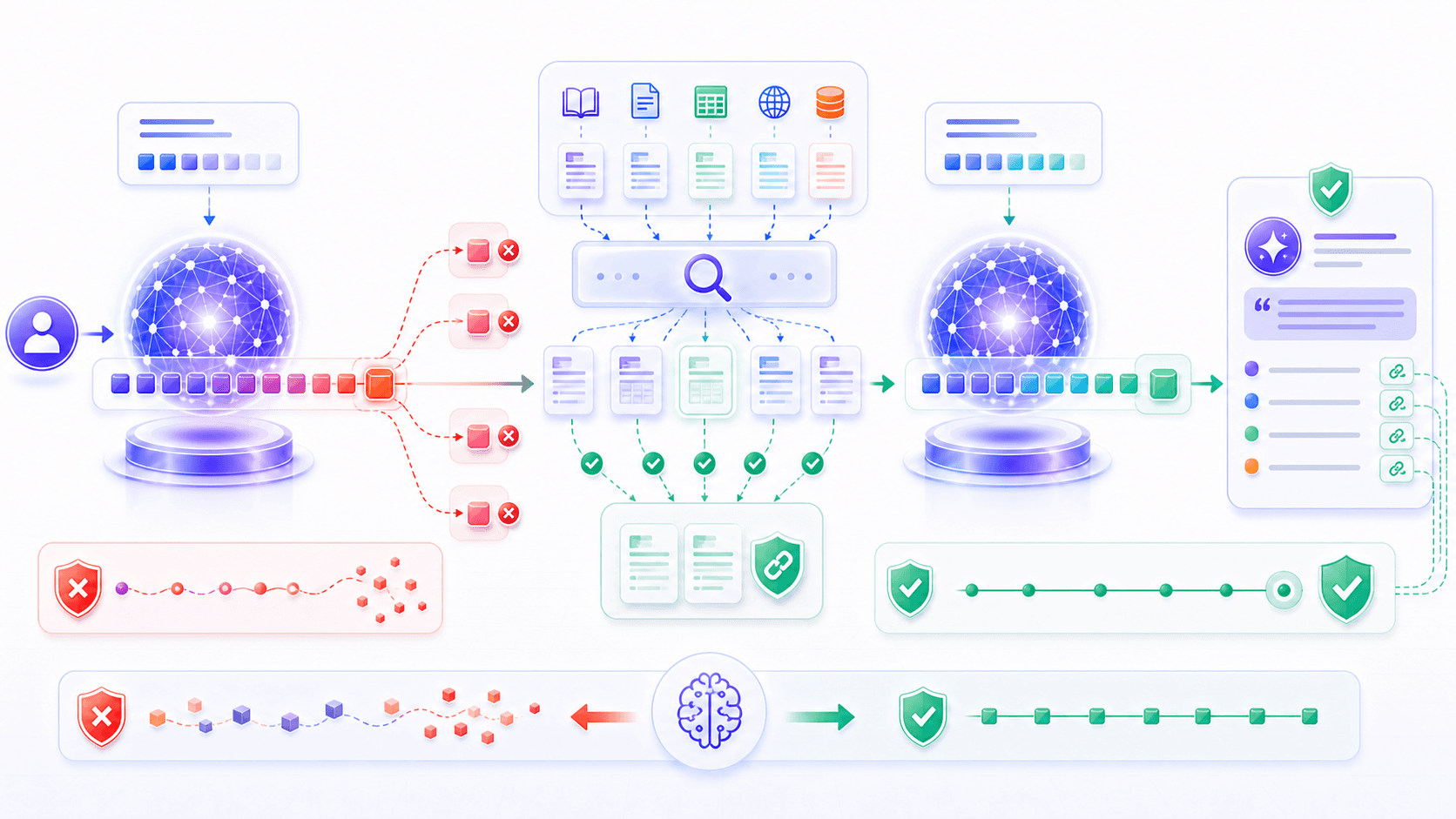
Once we understand hallucination, the role of RAG becomes natural.
RAG is not mainly about making the model “smarter.”
Its first job is to make the model grounded.
A raw model answers mostly from two information sources:
compressed memory in parameters;
context in the current prompt.RAG adds a third source:
relevant material retrieved from an external knowledge base.This changes the generation condition:
instead of answering from impression,
the model first sees traceable evidence,
then uses language ability to organize an answer from that evidence.RAG does not eliminate hallucination completely.
It has its own failure modes:
no retrieval;
wrong retrieval;
stale documents;
poor chunking;
too much context;
incorrect citation use;
answers that require calculation rather than reading.But RAG moves the problem from “the model says something from nowhere” to “the model says something based on material.”
For fact-heavy tasks, that is a major improvement.
We can state the next post’s central question already:
If hallucination comes from missing grounding,
then RAG is the first system-level pattern for attaching traceable grounding to the model.9. Common Misunderstandings
Misunderstanding 1: Hallucination proves the model has no understanding at all.
No. Hallucination shows a gap between language generation and factual verification. It does not mean the model learned no structure. A person making a mistake also does not prove that they understand nothing.
Misunderstanding 2: Larger models always hallucinate less.
Not necessarily. Stronger models often know more, follow instructions better, and may be better calibrated. But if a task requires external facts or live information, hallucination can still happen. Scale lowers risk; it does not replace grounding.
Misunderstanding 3: Temperature 0 prevents hallucination.
No. Low temperature reduces randomness. But if the highest-probability path is wrong, the model can produce the wrong answer consistently.
Misunderstanding 4: Asking the model to think first solves hallucination.
Not always. More reasoning text may help with complex problems, but without factual sources it can also become a longer and prettier wrong answer.
Misunderstanding 5: RAG completely eliminates hallucination.
No. RAG provides evidence and traceability, but retrieval, chunking, ranking, citation, and answer synthesis can still fail. It is a system layer that reduces hallucination, not immunity.
10. Summary: Hallucination Is Probabilistic Generation Without Grounding
We can compress this post into a few sentences:
The model's training objective is token prediction, not fact verification.
Parameters are lossy compression of language and world structure, not a complete database.
During inference, the model generates token by token along local high-probability paths.
If context lacks evidence, tools are absent, and the system adds no verification,
the model can still generate fluent, confident, but false content.
That is the first-principles explanation of hallucination.Compressed into one sentence:
Hallucination is not a model suddenly going rogue. It is a probabilistic language system treating “sounds plausible” as something it can output when evidence and verification are missing.
Once we understand this, we can look at LLMs more clearly.
They are not universal knowledge databases.
They are also not pure nonsense machines.
They are powerful language and pattern generation systems.
When the task is creative writing, drafting, rewriting, summarization, or structured expression, that capability is extremely useful.
When the task requires facts, numbers, sources, permissions, and execution results, the model needs to be placed inside a fuller system.
11. Three Questions You Should Be Able to Answer
After reading this post, try answering these in your own words:
- Why is hallucination not the model “lying on purpose,” but a gap between generation and factual verification?
- Why can low temperature, more reasoning text, or a larger model not eliminate hallucination by themselves?
- How do RAG, tools, and validators each reduce hallucination risk at a different layer?
Next, we will continue with that system question: RAG. How do we connect an external knowledge base to a model so answers move from “generated from impression” to “generated from evidence”?