12: LLM Engineering: KV Cache, Inference Cost, and Deployment Systems
This is the twelfth post in the “Understanding LLMs from First Principles” series. Post 11: Agents explained how models move from chatbots to task-execution systems. Now we bring in an engineering lens: if every answer is generated one token at a time, how do cost, latency, KV cache, concurrency, and deployment architecture shape AI products? Why do they become decisive for whether a product can scale?
In the previous posts, we moved from “saying” toward “doing”:
RAG lets models answer from external evidence.
Tool Use turns language intent into external action.
Agents move tasks forward around goals.But the closer we get to product systems, the more obvious one fact becomes:
Model capability is not the same as product capability.A model that answers well in a demo is not automatically ready to serve one hundred thousand users.
An agent that succeeds on one task is not automatically ready for concurrency, long context, tool latency, failed retries, and cost constraints.
From first principles, LLM engineering is not mainly about whether the model is intelligent.
It is about this:
How do we turn a probabilistic model that generates token by token
into a low-latency, concurrent, observable, cost-controlled online service?This post follows that thread.
1. The Engineering Problem Is Not “Can the Model Answer?” but “Can It Answer Reliably?”

When we test a model locally or in a web UI, we usually focus on:
Is the answer correct?
Is the model smart?
Can it reason?
Can it call tools?Once the model enters a product system, the questions change:
How long until the first token appears?
How many tokens can it generate per second?
How many users can it serve at peak?
How much context can one conversation carry?
How should failed tool calls be retried?
How much does one task cost on average?
When should the system downgrade to a cheaper model?
Which requests should be queued, rejected, or split?
When users see a failure, can the system explain why?These sound like engineering details.
They are not peripheral details.
The reason is simple: the core experience of an LLM product is directly shaped by its inference system.
Users do not only feel model capability.
They also feel:
Waiting time
Output speed
Answer stability
Whether long conversations lose context
Whether tool results arrive in time
Whether failures can recover
Whether the cost is acceptableSo LLM engineering is not just “deploying the model.”
It is the runtime system between model capability and product experience.
2. The Starting Point: Autoregressive Generation

When we discussed inference and generation, we saw the basic loop:
Existing context
↓
Compute a probability distribution for the next token
↓
Choose one token
↓
Append that token to the context
↓
Predict the next token againThis is where all the engineering problems begin.
An LLM does not emit a whole answer all at once.
For every output token, it runs another forward pass under the current context.
So the latency of one answer can be roughly split into two parts:
Total latency ≈ time to read and process the input context
+ time to generate output one token at a timeThe common engineering terms are:
Prefill: processing the existing prompt / context.
Decode: generating new tokens sequentially.These two phases behave very differently.
Prefill is like:
Read the user question, system prompt, chat history, RAG evidence, and tool results.Decode is like:
After reading all that, write the answer step by step.This explains two common product metrics:
TTFT (Time To First Token): how long until the first token appears.
Tokens per second: how fast the answer streams after that.They map neatly to user perception:
How long do I wait first?
How fast does it flow once it starts?If the prompt is long, TTFT often grows.
If the answer is long, decode time grows.
If many users request at once, scheduling, queuing, and GPU memory pressure appear.
So from first principles:
LLM inference is not a single function call.
It is context processing plus a strongly sequential token-generation loop.Once this is clear, KV cache, cost, and deployment architecture become much easier to understand.
This section builds the engineering intuition first. If you want to turn “moving parameters” and “doing compute” into equations, and understand why output tokens are often more expensive than input tokens and why the batch-size sweet spot falls out of hardware constants, continue with The Math Behind LLM Pricing 01: How Inference Actually Works and 02: Writing Inference as Equations.
3. Prefill and Decode: Long Input and Long Output Are Expensive in Different Ways

Think of one request like a restaurant order.
Prefill is the kitchen reading the full ticket:
Who is the customer?
What did they order?
Any dietary constraints?
What does the order history say?
Is there a coupon?
Is inventory available?Decode is the kitchen sending dishes out one by one.
Reading the ticket can process many details at once.
Serving dishes has an order: if the first dish is not done, later steps are affected.
LLM generation is similar.
1. Prefill Is Mostly Driven by Input Context
The longer the input context, the more tokens the model must process.
Those tokens may come from:
System prompts
User questions
Chat history
RAG snippets
Tool results
Formatting instructions
Implicit safety policiesThis is why many AI products slow down after long conversations.
The user feels they only asked a short question.
But the system may be sending:
Short question + long chat history + retrieved passages + tool results + system constraintsThe model sees tokens, not the user’s subjective feeling of “just one sentence.”
2. Decode Is Mostly Driven by Output Length
The longer the answer, the more tokens must be generated.
Each output token depends on the tokens already generated before it.
That makes decode inherently difficult to fully parallelize.
This is why:
Writing a long essay is much more expensive than answering in one sentence.
Running a multi-step agent is much more expensive than a single response.
Generating a long structured JSON object can be slower than a short summary.The model is not being lazy.
The generation path itself advances token by token.
3. Input Tokens and Output Tokens Mean Different Things for Product Design
Input tokens determine how much the model must read.
Output tokens determine how long the model must write.
In product design, this becomes a set of concrete questions:
How much chat history should remain?
How many RAG passages should be inserted?
Should tool results be trimmed?
Does the model need to output the full long-form answer?
Can it produce a summary first and expand on demand?
Can the task be split into shorter steps?So “more context is always better” and “more complete output is always better” are both false.
Context and output are capabilities, but they are also costs.
4. KV Cache: The Key Mechanism That Trades Memory for Speed
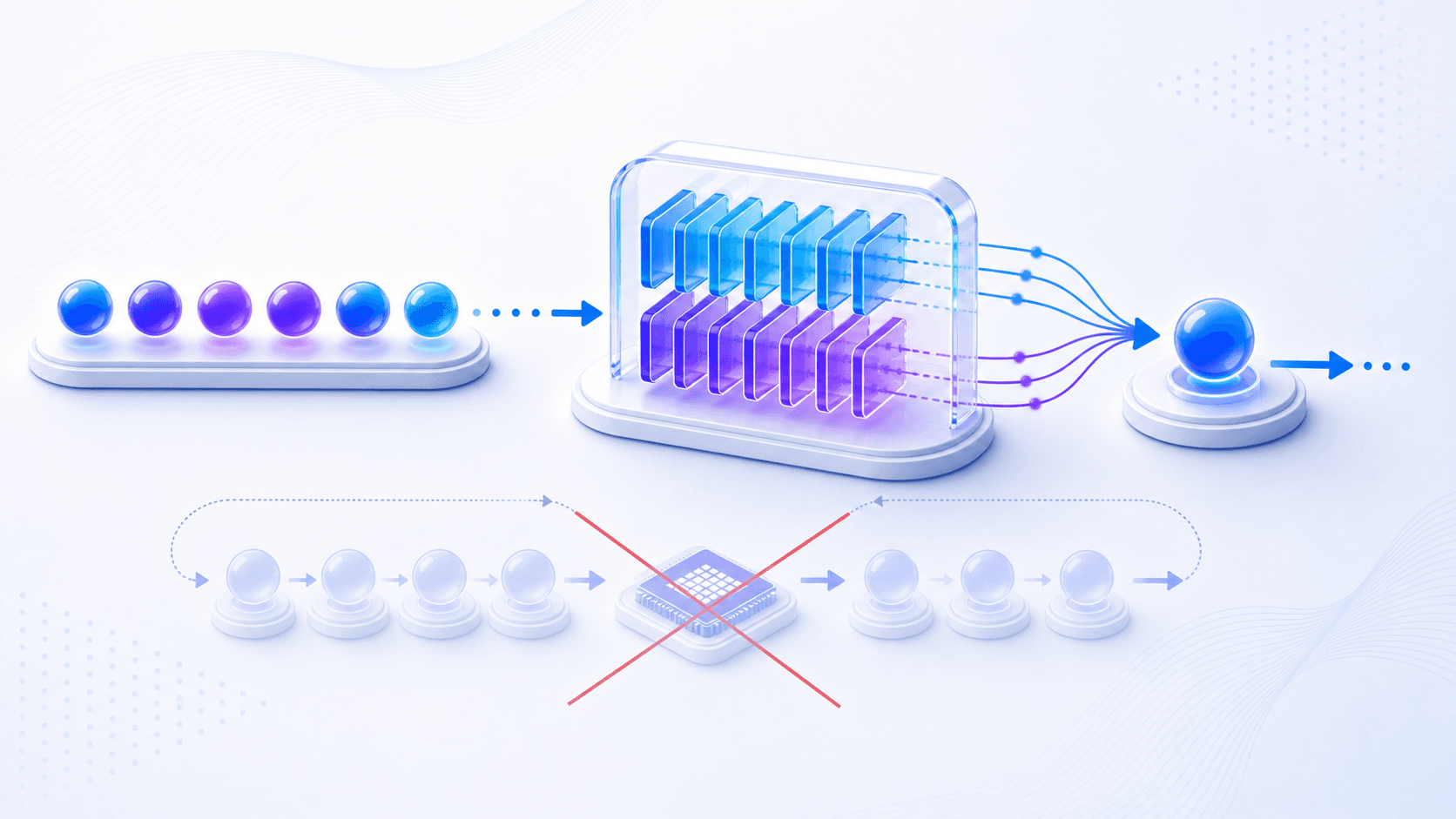
Now we reach the central concept of this post: KV cache.
In a Transformer, attention lets the current token refer to previous tokens.
Each layer projects token representations into several vectors. The most relevant ones for attention lookup are:
Query: what the current token is looking for.
Key: what each historical token offers as an index.
Value: what content each historical token carries.Without caching, every time the model generated a new token, it would recompute the keys and values for the entire previous context.
That would be wasteful.
The historical tokens did not change.
Only the newly generated token changed.
So inference systems do the natural engineering move:
Store the Key / Value tensors produced by past tokens in each layer.
When generating the next token, compute only the new token's part.
Let the new token attend to the cached historical Key / Value tensors.That is KV cache.
Its first principle is:
KV cache uses GPU memory to store attention intermediates for previous tokens,
so each new token does not require recomputing the whole context.Concretely, the prefill stage computes and caches the Key / Value for every layer of the prompt while it processes the input context; during decode, each new token only computes its own part and reuses the cached historical Key / Value.
This optimization is one reason modern LLM inference is practical.
Without KV cache, long conversations and long outputs would be far slower.
KV cache can go one step further.
When many requests share the same beginning — the same system prompt, the same few-shot examples, the same long document — the Key / Value for that prefix is identical every time.
If it is identical, there is no need to recompute it for every request.
The cache for that shared prefix can be kept and reused across requests. This is prefix caching, which many APIs package and bill as prompt caching.
The product implication is direct:
Put stable content (system prompts, rules, long documents) at the front of the prompt,
so repeated calls hit the cache and skip the repeated prefill;
put frequently changing content at the end, so it does not invalidate the cache.So the same long system prompt is paid for in full the first time, but later requests that hit the cache are faster and cheaper.
But KV cache is not free.
Its cost is GPU memory.
5. Why KV Cache Becomes the Bottleneck for Long Context and Concurrency
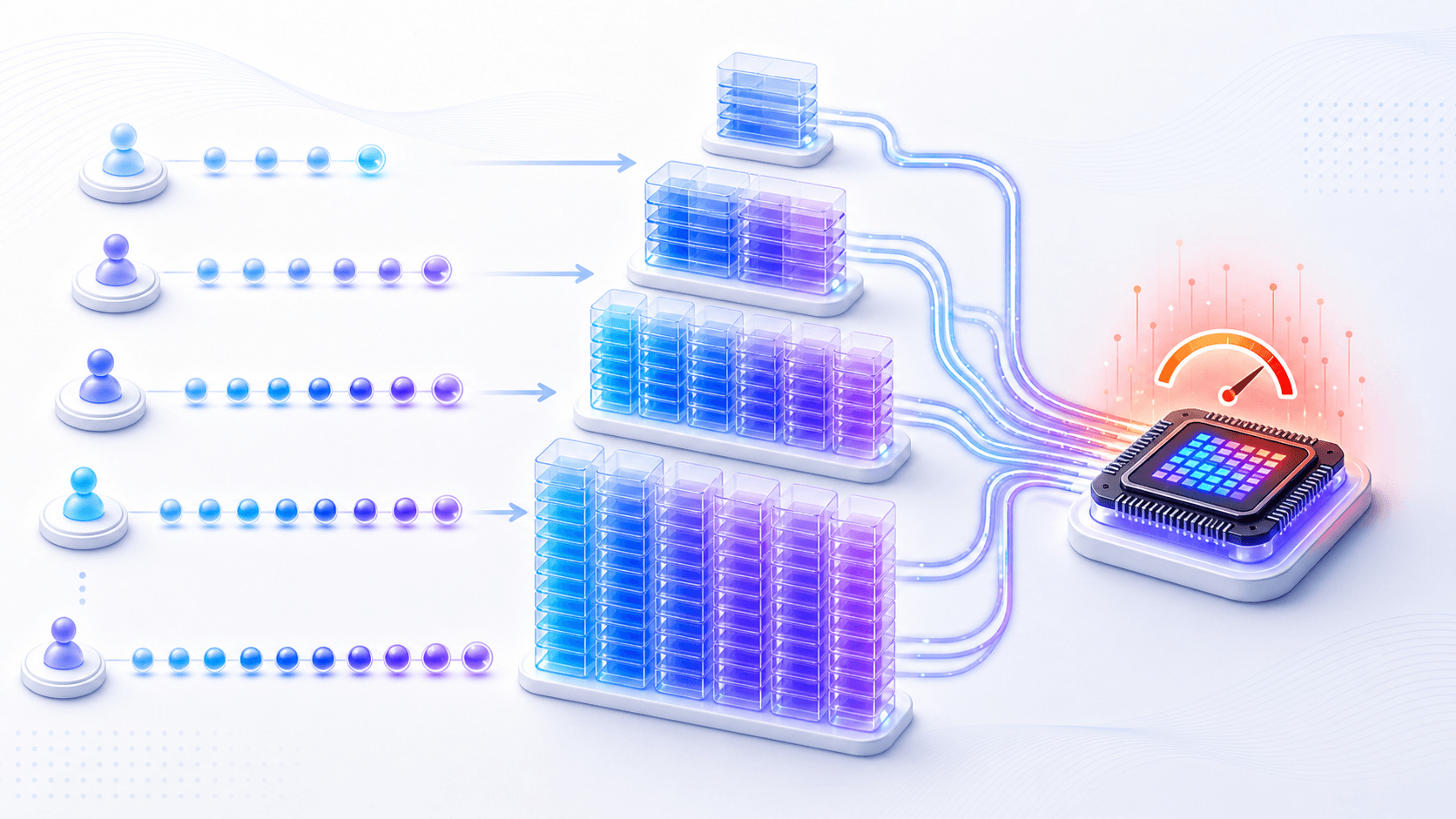
The size of KV cache is roughly related to:
KV cache size
≈ number of active requests
× context tokens
× number of model layers
× Key / Value dimensions saved per layer
× bytes per valueYou do not need to memorize the formula.
The important sentence is:
Longer context and higher concurrency consume more GPU memory through KV cache.This explains many product behaviors.
1. Long Context Is Not Just a Few More Input Tokens
Long context does increase prefill compute.
More importantly, it increases KV cache.
If one user starts generating with a long context, the system needs to keep a cache for that context.
If many users generate with long contexts at the same time, GPU memory pressure rises quickly.
So a long-context product cannot only ask:
What is the model's maximum context window?It also needs to ask:
How much concurrency can we support at this context length?
What is P95 latency?
What is the unit task cost?
Does the failure rate rise?2. Multi-Turn Conversation Accumulates Context Debt
Multi-turn chat feels natural.
For the inference system, each round may accumulate:
User history
Assistant history
RAG evidence
Tool results
Intermediate reasoning notes
System constraintsWithout context management, two problems appear:
It gets slower.
It gets more expensive.Longer context also does not guarantee that the model will attend to the right parts reliably.
So context management is not a prompt trick.
It is a shared control surface for cost, latency, and quality.
3. Agents Amplify the KV Cache Problem
An agent is not one question and one answer.
It may:
Plan
Call a tool
Read an observation
Update state
Call another tool
Generate an intermediate conclusion
Deliver the final resultIf every step sends the full history back to the model, cost can spiral quickly.
That is why mature agent systems separate conversation context from task state.
Not all history belongs in the prompt.
Some information should be summarized.
Some should be stored structurally.
Some should be retrieved on demand.
Some should be discarded.
That is the relationship between KV cache and context engineering.
For a deeper look at why KV cache becomes central to long-context pricing and architecture optimization, see The Math Behind LLM Pricing 04: Cracking Open the KV Cache. That post digs into KV bytes per token, GQA / MLA / cross-layer sharing, and how long-context tiered pricing can reveal clues about internal architecture.
6. Inference Cost: The Model Call Is Not the Only Thing That Costs Money
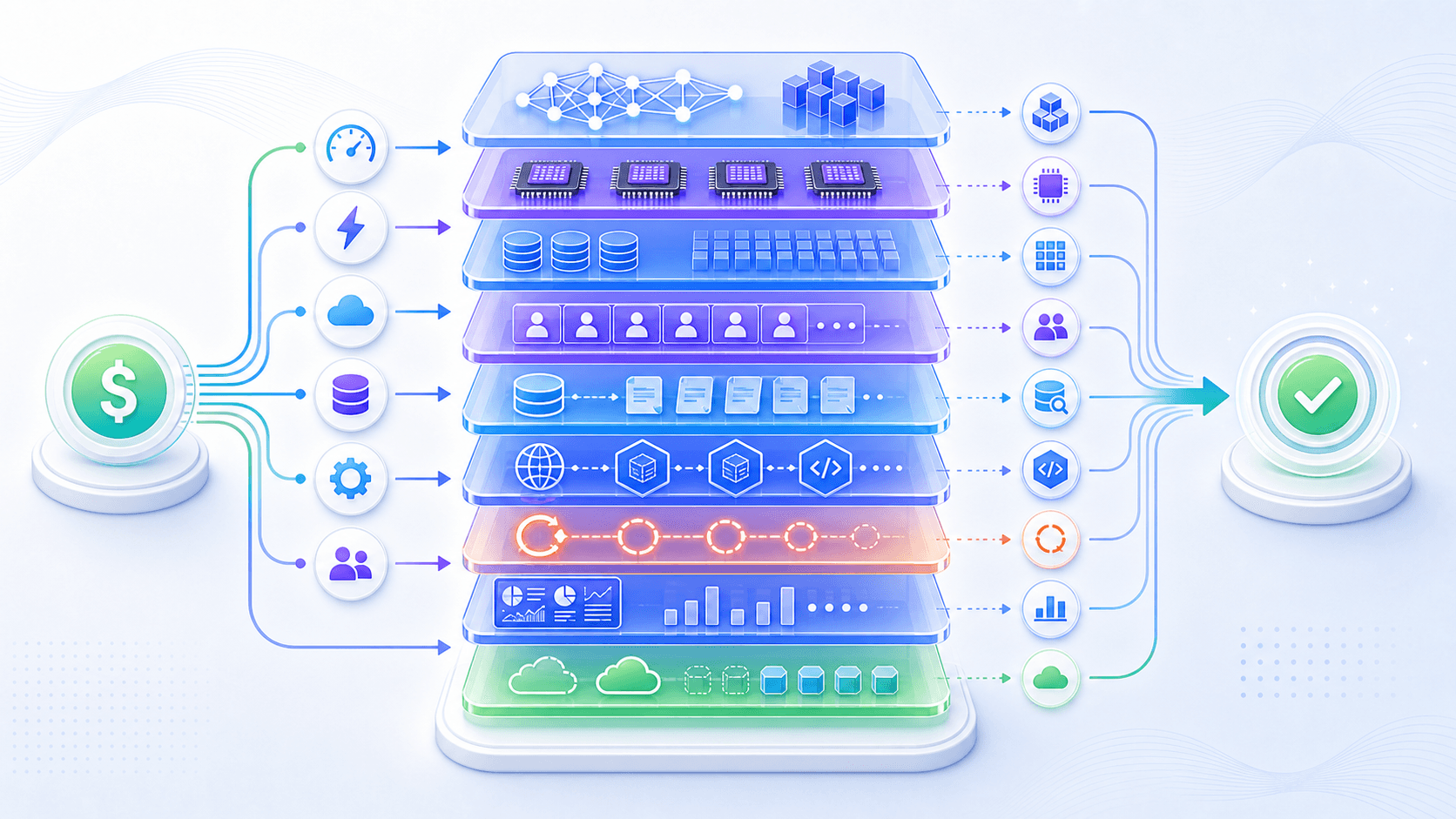
When people first think about LLM cost, they often think about API prices:
Price per input token
Price per output tokenThat is a useful entry point, but not the full picture.
At a system level, inference cost comes from several layers:
GPU memory occupied by model weights
Compute for prefill and decode
GPU memory and bandwidth occupied by KV cache
Waiting introduced by batching and scheduling
RAG retrieval, reranking, and database queries
Tool calls and external system latency
Failed retries and multi-model fallbacks
Logging, monitoring, evaluation, and safety checks
Reserved capacity for low-latency service levelsThis is why a cheaper model does not always reduce total task cost.
If the cheaper model often fails, needs three retries, or requires a much longer prompt to stay controlled, total cost can rise.
Likewise, a stronger model is not always more expensive in practice.
If it solves the task in one pass, uses fewer tools, needs fewer retries, and writes a shorter answer, it may be cheaper for some tasks.
The more accurate unit is:
Cost per successful task.Not:
Price per token.This matters especially for agent products.
One agent task may include:
Multiple model calls
Multiple retrievals
Multiple tool calls
Failure recovery
Human confirmation
Final validationIf you only look at the price of one model call, you will underestimate the real cost.
If you only look at token price, you will miss latency, failure rate, and user waiting.
7. Batching and Scheduling: Throughput and Latency Are Always Pulling Against Each Other
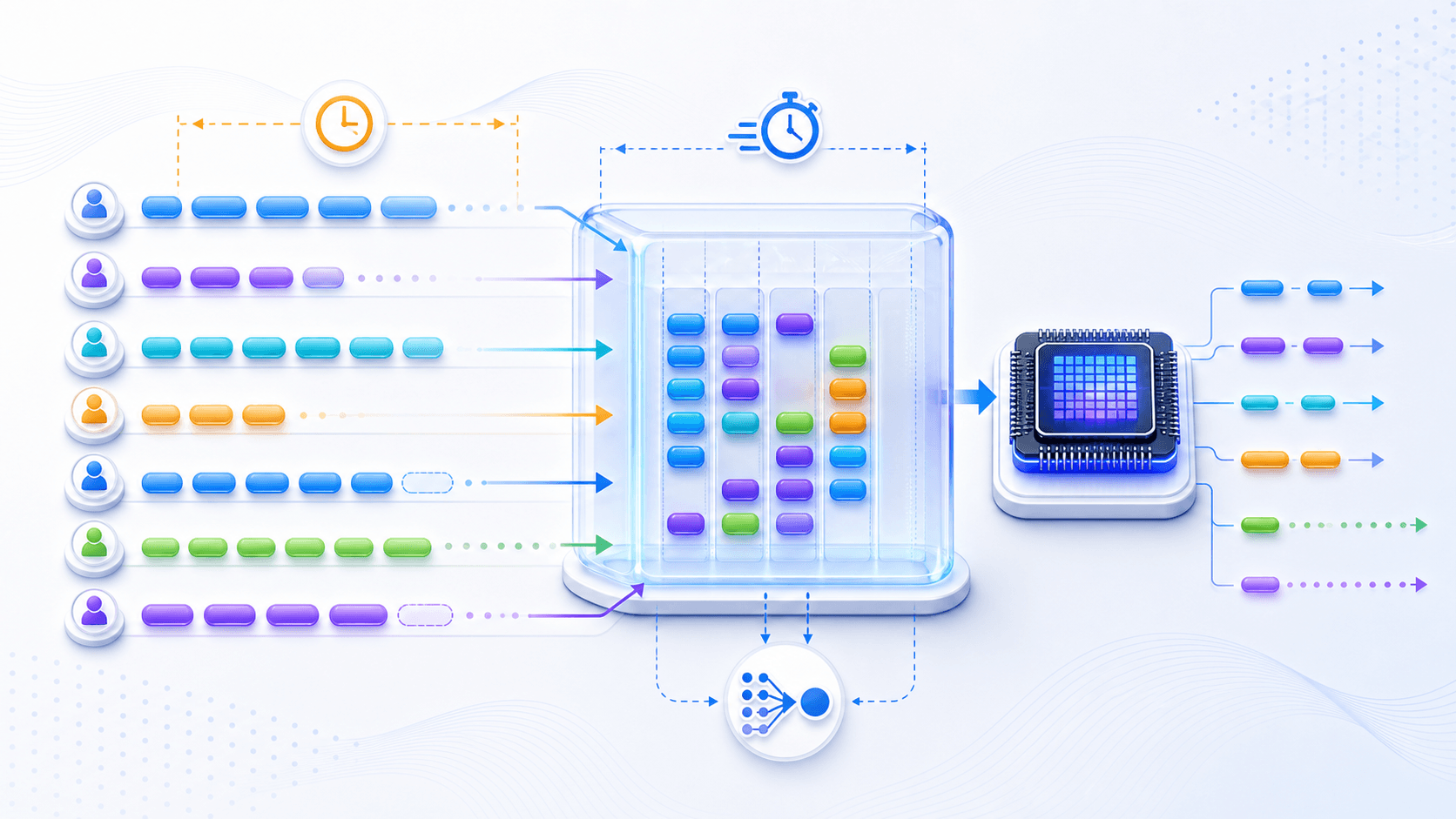
GPUs are good at parallel computation.
If an inference server handles only one request at a time, much of that compute is wasted.
So inference systems usually group requests together. This is batching.
The intuition is like ride sharing:
A private ride waits less but costs more.
Ride sharing improves utilization but may require waiting.
Overfilling the ride can hurt everyone's arrival time.LLM inference has the same shape.
Batching improves throughput and reduces unit token cost.
But batching also introduces queuing and scheduling problems.
Decode is especially tricky because different requests have different output lengths:
One user needs one sentence.
Another needs an essay.
One stops halfway.
Another adds tool results and continues.That is why modern inference systems usually need dynamic scheduling rather than only static batches.
New requests may be inserted while older requests continue generating — this is usually called continuous batching (also known as in-flight batching).
The important point is not one specific technique name, but the tradeoff:
Higher throughput improves unit cost.
Lower latency improves user experience.
Tighter GPU memory makes long context and concurrency harder.
More complex scheduling makes observability more important.Streaming also belongs here.
Streaming lets users see the first token earlier.
It improves perceived waiting.
But it does not let the model skip token-by-token generation.
So:
Streaming improves experience.
Batching improves throughput.
KV cache avoids repeated computation.
Scheduling balances all of them.This section keeps the product-engineering view. If you want the cost curve itself, read The Math Behind LLM Pricing 03: From Inference Latency to Inference Cost: it decomposes cost per token into amortizable parameter movement, non-amortizable KV, and the compute floor. If you want to go beyond one GPU into clusters, expert / pipeline parallelism, racks, scale-up, and interconnect, continue with 05: From One GPU to a Cluster.
8. Deployment Systems: An LLM Product Is Not “One Model + One Endpoint”
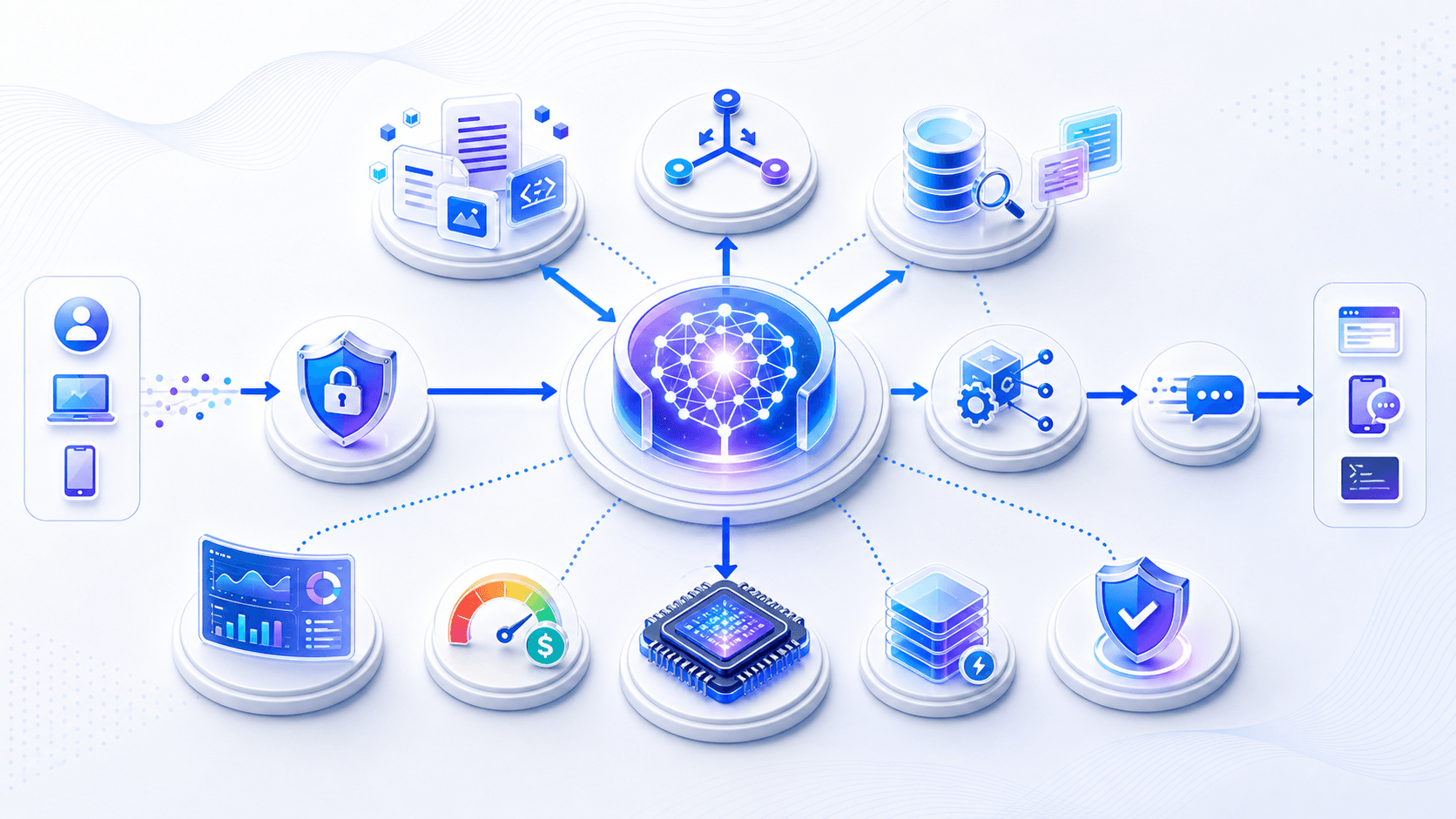
A real LLM product is usually not:
Frontend
↓
Model API
↓
AnswerIt is closer to:
User request
↓
Identity, permission, and quota checks
↓
Task classification and model routing
↓
Context assembly
↓
RAG / tools / business data reads
↓
Inference service
↓
Safety and format validation
↓
Streaming response
↓
Logs, evaluation, and cost attributionEach layer affects the final experience.
1. The Gateway Decides Who Can Use What, How Much, and Through Which Path
A gateway does more than forward requests.
It often handles:
Authentication
Rate limiting
Quota
Model selection
Gradual rollout
Fallback
Audit
Cost attributionThe same user request should not necessarily always go to the same model.
Simple questions can use a smaller model.
High-risk questions can use a stronger model.
Long-form writing can use a model that handles long output well.
Low-latency scenarios can use a faster model.
That is the product value of model routing.
2. Context Assembly Decides What the Model Actually Sees
The user thinks they sent one sentence to the model.
The system may add:
System prompts
Product rules
User profile
History summaries
Retrieved evidence
Tool state
Output format
Safety boundariesThis layer determines input quality and cost.
Poor context assembly can make a strong model answer poorly.
Good context assembly can make a smaller model good enough.
3. The Inference Layer Decides Speed, Concurrency, and Stability
The inference layer handles:
Prefill
Decode
KV cache
Batching
GPU memory management
Request cancellation
Timeouts
Failed retriesThis is the layer closest to GPUs and model runtimes.
It decides whether the system survives peak traffic.
4. The Business Layer Decides Whether the Model Creates Real Value
RAG, tool calls, databases, workflows, and approvals are not decorations around the model.
They decide whether model output can land in real tasks.
So the core of LLM deployment is not “putting the model on a server.”
It is:
Putting the model inside a product runtime with permissions, context, tools,
monitoring, and failure handling.9. Observability: You Cannot Optimize Tokens You Cannot See
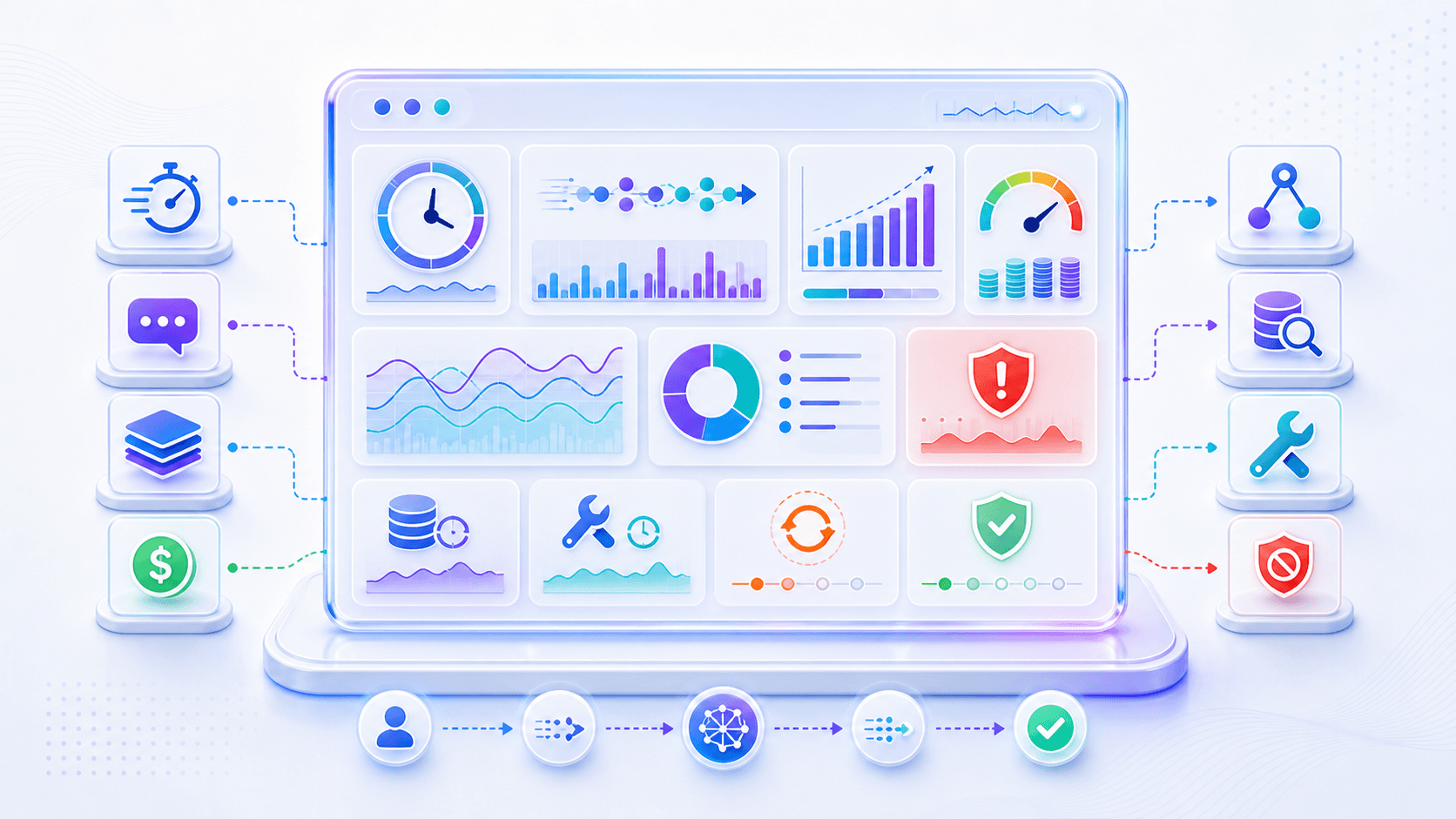
Traditional software systems also need monitoring.
LLM systems add new things to observe.
Beyond normal API latency, error rate, CPU, and memory, you need to look at:
Input tokens
Output tokens
Context length distribution
TTFT
Output tokens per second
P50 / P95 / P99 latency
Cost per request
Cost per successful task
Model selection distribution
RAG retrieval latency
Tool call latency
Retry count
Truncation count
User cancellation rate
Format validation failure rate
Safety block rateThese metrics are not decorative.
They answer product questions directly.
For example:
Why did answers get slower recently?
Did prompts get longer, or did outputs get longer?
Is RAG slow, or is model decode slow?
Did user requests become more complex, or is the scheduler queue congested?
Is the small model retrying too often, or is the strong model overused?
Did agent step count increase, or did tool failure rate rise?Without these metrics, teams can only tune prompts, swap models, and add machines by feel.
That can easily make the system more expensive while missing the real problem.
A basic rule of LLM engineering is:
First make tokens, latency, cost, quality, and failure paths visible.
Then optimize.10. Reliability: Failure Is Not Only the Model Being Wrong
In everyday language, model failure usually means:
The answer was wrong.
The model hallucinated.
It did not follow instructions.In an engineering system, failure has many more forms:
Context overflow
Request timeout
Out-of-memory errors
Queue overload
Truncated output
Tool call failure
RAG finds no evidence
Format validation failure
Retries inflate cost
User cancellation
External API rate limits
Model version changes cause behavior driftThis is why agent products need state management.
When a ten-step task fails at step seven, the system should not only say:
Something went wrong. Please try again.A better system should know:
Which steps already completed
Which tool failed
Whether retry is safe
Whether retry might duplicate a write
Whether human confirmation is needed
Whether it can resume from a checkpointSo reliability in LLM engineering is not only about making the model “less wrong.”
It is about letting the whole system move forward under control when models, tools, data, networks, and users can all fail.
11. Common Misunderstandings
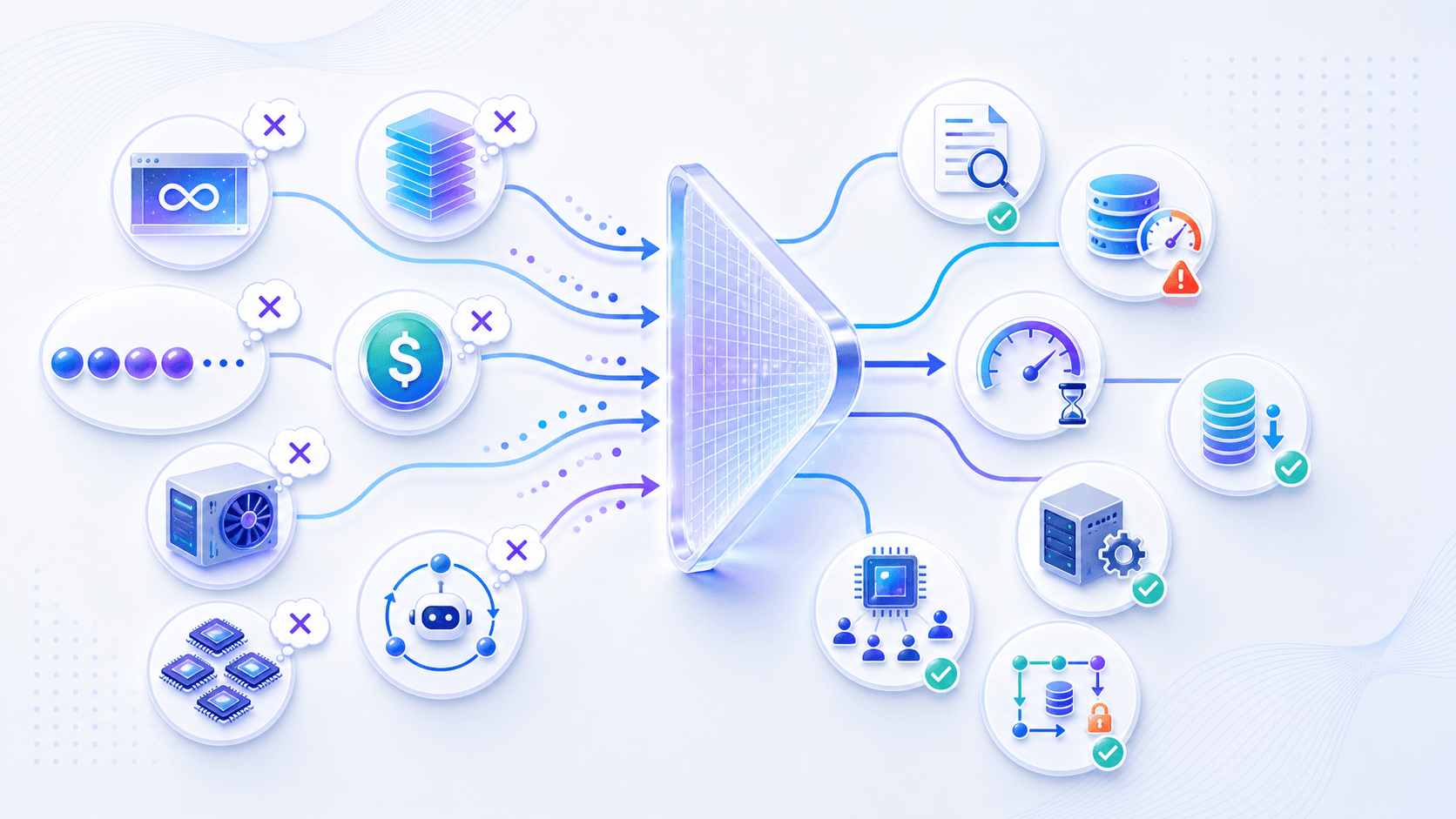
Misunderstanding 1: A larger context window automatically makes the product smarter.
Not necessarily. Large context expands what can be read, but it also increases prefill, KV cache, cost, and attention distraction. The important thing is putting the right information into context.
Misunderstanding 2: KV cache is just ordinary caching.
Not quite. KV cache stores Transformer attention intermediates. It is not a cache of final answers, and it is not the same as a RAG document cache.
Misunderstanding 3: Streaming makes the model compute faster.
Streaming mainly improves perceived waiting. Users see content earlier, but the model still generates token by token.
Misunderstanding 4: A cheaper model always lowers cost.
Not necessarily. The relevant number is total cost per successful task. If a cheaper model needs longer prompts, more retries, or more human fallback, it may cost more in the end.
Misunderstanding 5: Self-hosting is always cheaper than using an API.
Also not necessarily. Self-hosting includes GPU utilization, scheduling, memory management, operations, monitoring, peak capacity, and model upgrade cost. It only becomes attractive under the right scale, load stability, and team capability.
Misunderstanding 6: More GPUs automatically mean lower latency.
More GPUs add resources. They do not automatically solve scheduling, KV cache pressure, networking, batching, long-tail latency, or application-layer bottlenecks.
Misunderstanding 7: Agent cost is one model call.
No. Agent cost comes from multi-step inference, tool calls, RAG, state management, failure recovery, and final validation. The more autonomous the agent, the more you need task-level cost accounting.
12. Product and Engineering Implications

Once we understand LLM engineering, we look at AI product design differently.
A useful AI product is not just:
Choose a strong model.
Write a good prompt.
Attach a chat box.It also needs answers to:
Which requests need a strong model?
Which requests can use a smaller model?
When should retrieval happen?
When should tools be called?
How should context be trimmed and summarized?
How should long tasks persist state?
How should failures recover?
What should users see while waiting?
How should the system degrade when cost limits are reached?
Which metrics define product health?This is one reason AI-native products differ from traditional SaaS.
In traditional SaaS, a button usually maps to a deterministic code path.
In an AI product, the same button may hide a combination of probabilistic generation, context assembly, model routing, tool use, and state recovery.
Users need a reliable experience.
The system inside is probabilistic.
The bridge between them is LLM engineering.
13. Summary: Engineering Turns Model Capability into Product Capability
We can now compress this post into a few lines:
LLMs do not generate complete answers all at once; they predict token by token.
One request can be split into prefill and decode.
Long input mainly affects context processing and KV cache.
Long output mainly affects token-by-token generation time.
KV cache trades GPU memory for speed, but grows with long context and concurrency.
Cost should be counted per successful task, not only per token.
Batching, scheduling, and streaming shape throughput and perceived latency.
Deployment systems need gateways, context, model routing, tools, monitoring, and failure recovery.
Observability makes tokens, latency, quality, cost, and failure paths visible.
The goal of engineering is to turn a probabilistic model into a scalable product service.Compressed into one sentence:
LLM engineering is the discipline of managing context, memory, concurrency, cost, latency, and failure paths around token-by-token generation so model capability becomes stable product capability.
At this point, we have moved from low-level token prediction all the way to engineering systems.
But one important question remains:
If an AI system is probabilistic inside,
how should the product give users a reliable, trustworthy, controllable experience?14. Three Questions You Should Be Able to Answer
After reading this post, try answering these in your own words:
- Why do prefill and decode create different cost and latency bottlenecks?
- Why does KV cache turn long context and concurrency into engineering problems?
- Why should LLM cost be measured per successful task, not only by token price?
Next, we will move into AI-native product design: how probabilistic systems can provide reliable experiences.