07: Inference and Generation: Temperature, Context Window, and Token-by-Token Output
This is the seventh post in the “Understanding LLMs from First Principles” series. Post 06: Scaling Laws and Emergence explained why scale changes model capability boundaries. Now we look at what happens when a model actually answers: why can the same model be stable or exploratory? Why does temperature change style? Why does the context window limit memory? Why does the answer appear one token at a time?
Across the previous posts, we focused on how the model is trained:
Pretraining teaches language and world structure.
Fine-tuning teaches the model to respond to user instructions.
Alignment makes behavior more helpful, honest, and safe.
Scale pushes more tasks across the threshold of usability.But when you actually use a large language model, a different process happens:
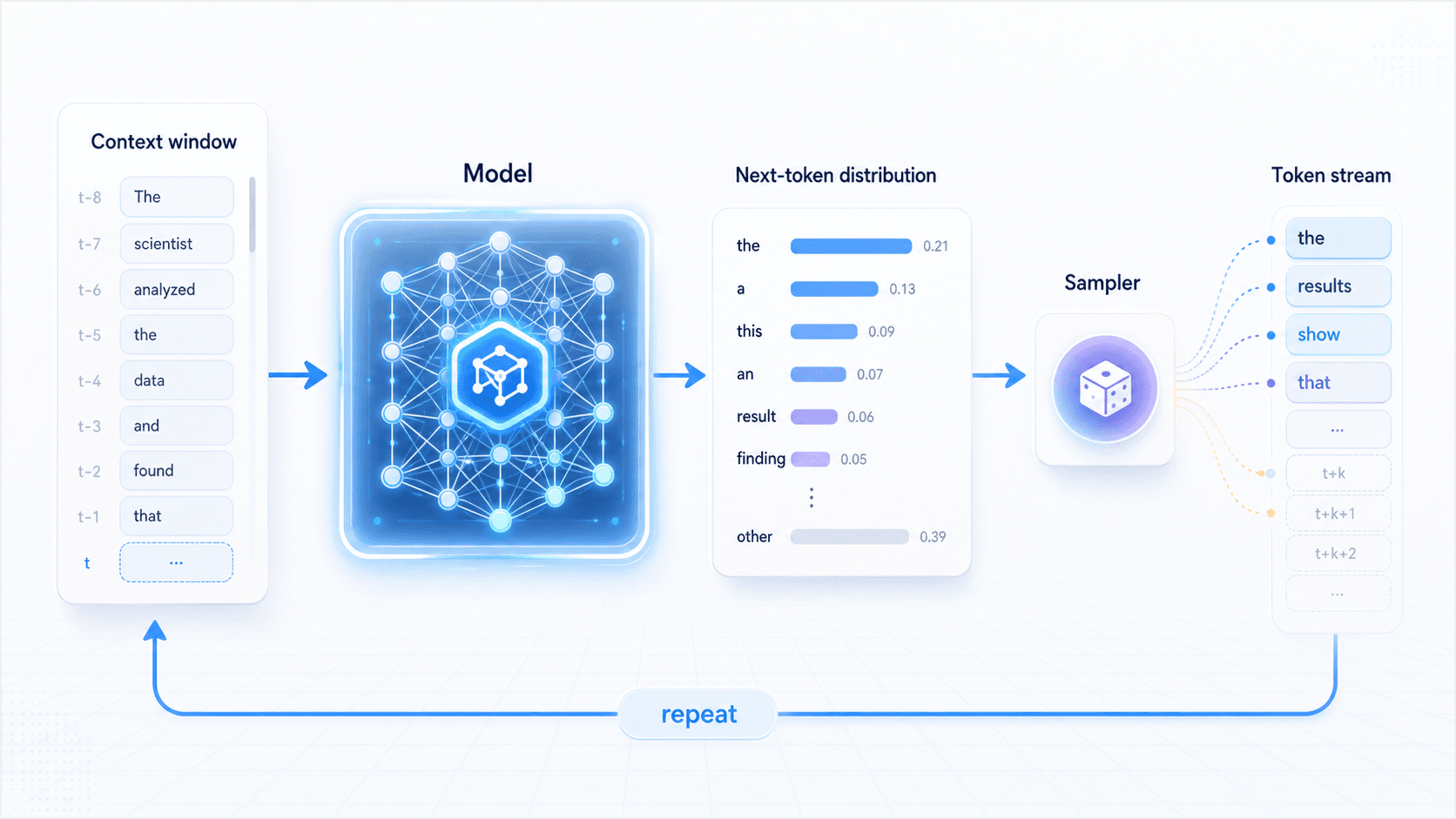
Give it a context.
The model computes a probability distribution over the next token.
The system selects one token from that distribution.
That token is appended back into the context.
Then the loop repeats.This process is inference, or generation.
Once you understand this layer, many product behaviors become less mysterious:
Why asking the same question twice can produce different answers.
Why low temperature is more stable and high temperature is more exploratory.
Why a model can miss earlier information when the context becomes long.
Why output streams gradually instead of appearing as a complete finished answer.
Why the model sometimes drifts, and sometimes stays tightly on target.The core sentence of this post is:
Inference is not the model thinking of a complete answer and then printing it. It repeatedly turns context into a next-token distribution, then samples tokens one by one.
1. Inference Is Not “Thinking of the Whole Answer First”
Start with an intuitive mistake.
When you ask:
Explain gradient descent in one sentence.It is easy to imagine the model first forming a complete sentence:
Gradient descent is an optimization method that gradually adjusts parameters in the direction that reduces loss.Then it simply prints that sentence from beginning to end.
That is not how large language models generate.
More precisely, at the first step the model does not receive a complete “answer object.”
It receives the current context and computes:
Given the tokens visible so far,
what should the probability distribution over the next token look like?In other words, the full answer is not fixed at the first step.
It is more like walking a path that has not fully been determined yet.
The first step may go toward:
Gradient...
It...
This is a...Each opening changes what continuation becomes more natural.
If it first selects “Gradient”, the answer is likely to move into a definition.
If it first selects “It”, the answer will probably sound more conversational.
If it first selects “This is a”, the answer may move into analogy or functional explanation.
So a large language model is not retrieving a paragraph that was already written. It is gradually committing to an expression path through probability space.
Once that path begins, it starts to create momentum.
Earlier word choices influence which words become easier later.
Earlier structure influences which structure the model keeps following.
Earlier factual assumptions influence the direction of later explanation.
This is why a small early deviation can grow into drifting, verbosity, or hallucination.
This is why prompts, context management, and output constraints matter.
They are not commands injected into a human-like mind. They shape the context visible at every generation step, making the next-token distribution more likely to move in the direction we want.
2. The Next-Token Distribution: A Ranked Table of Possibilities
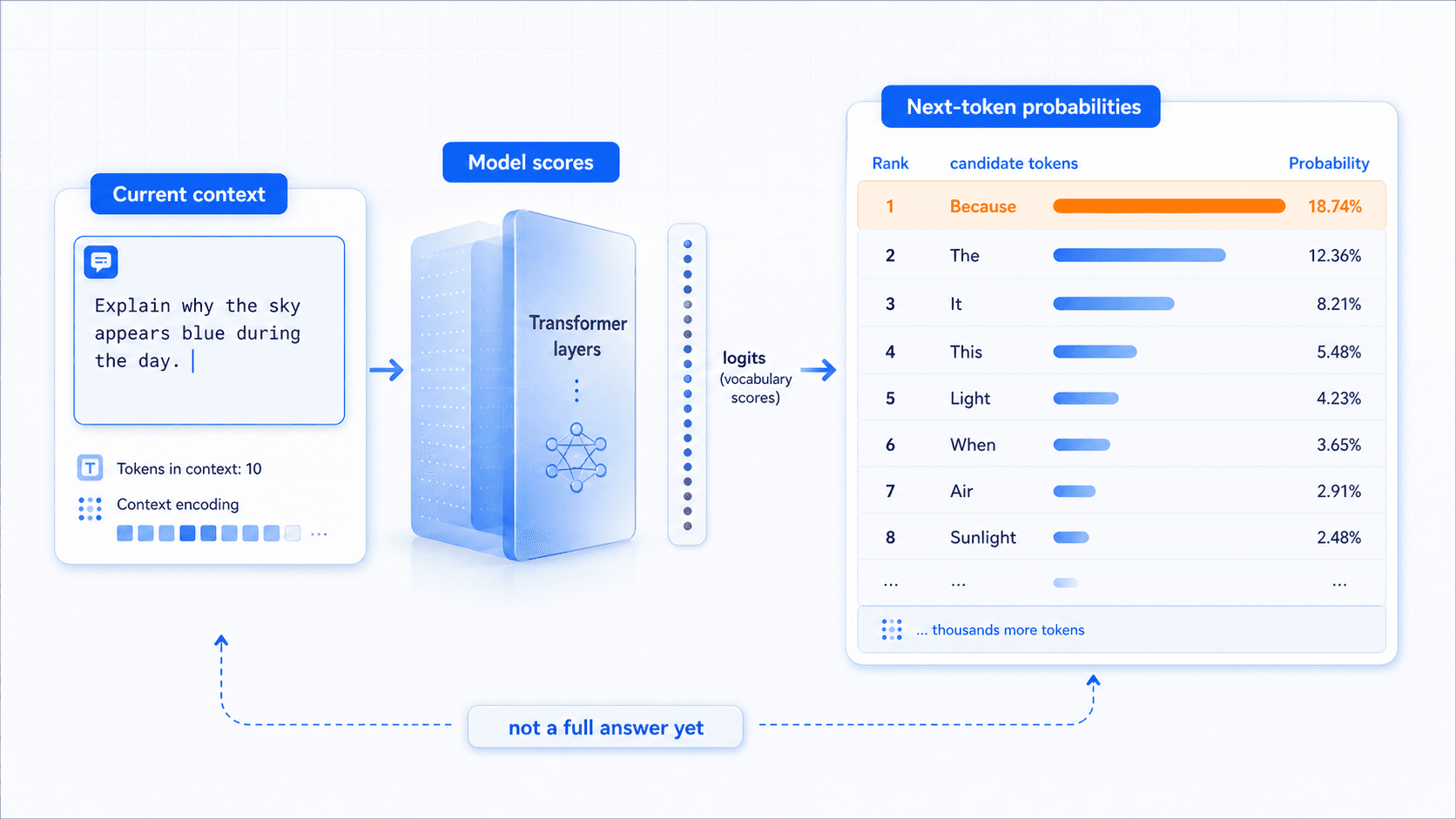
During inference, the first thing the model produces is not a sentence. It produces a set of scores.
More precisely, it gives a raw score to every possible token in the vocabulary. In engineering terms, these raw scores are often called logits.
After transformation, those scores become a probability distribution:
token A: 42%
token B: 24%
token C: 15%
other tokens: lower probabilitiesThis means that at each step, the model does not face one unique answer. It faces a table of candidates.
For example, suppose the context is:
Explain gradient descent in one sentence.The model may judge that several next tokens are reasonable:
"Gradient"
"It"
"A"
"This"Each opening can lead to a reasonable answer.
If it selects “Gradient”, the answer may continue:
Gradient descent is an optimization method...If it selects “It”, the answer may continue:
It is a method for gradually improving model parameters...If it selects “This”, the answer may continue:
This is a way to reduce error by repeatedly adjusting parameters...These are not necessarily wrong. They are different paths of expression.
So generation is not retrieval of one correct sentence. It is walking a path through a probability distribution.
This is why the same model can have two properties at once:
It is stable, because high-probability tokens usually fit the meaning and task.
It is not completely fixed, because there are often multiple reasonable paths.During training, the model uses the real next token to update its parameters.
During inference, the parameters are already fixed. The model is no longer learning. It computes a distribution under the current context, and a sampling strategy decides which path to take.
3. Sampling and Temperature: Why the Same Model Can Answer Differently
Once we have the next-token distribution, the system must choose.
The most direct method is to always select the highest-probability token.
This is called greedy decoding. You can think of it as “always take the safest next step.”
That approach is usually stable, but it can create problems:
The writing becomes conservative.
Answers can become repetitive.
Creative tasks feel flat.
If an early choice is bad, the decoder has little room to explore another path.Another method is sampling.
Sampling is not random chaos. It chooses according to the probability distribution:
Higher-probability tokens are more likely to be selected.
Lower-probability tokens can still be selected with small probability.
Very low-probability tokens are often filtered out.This is where temperature enters.
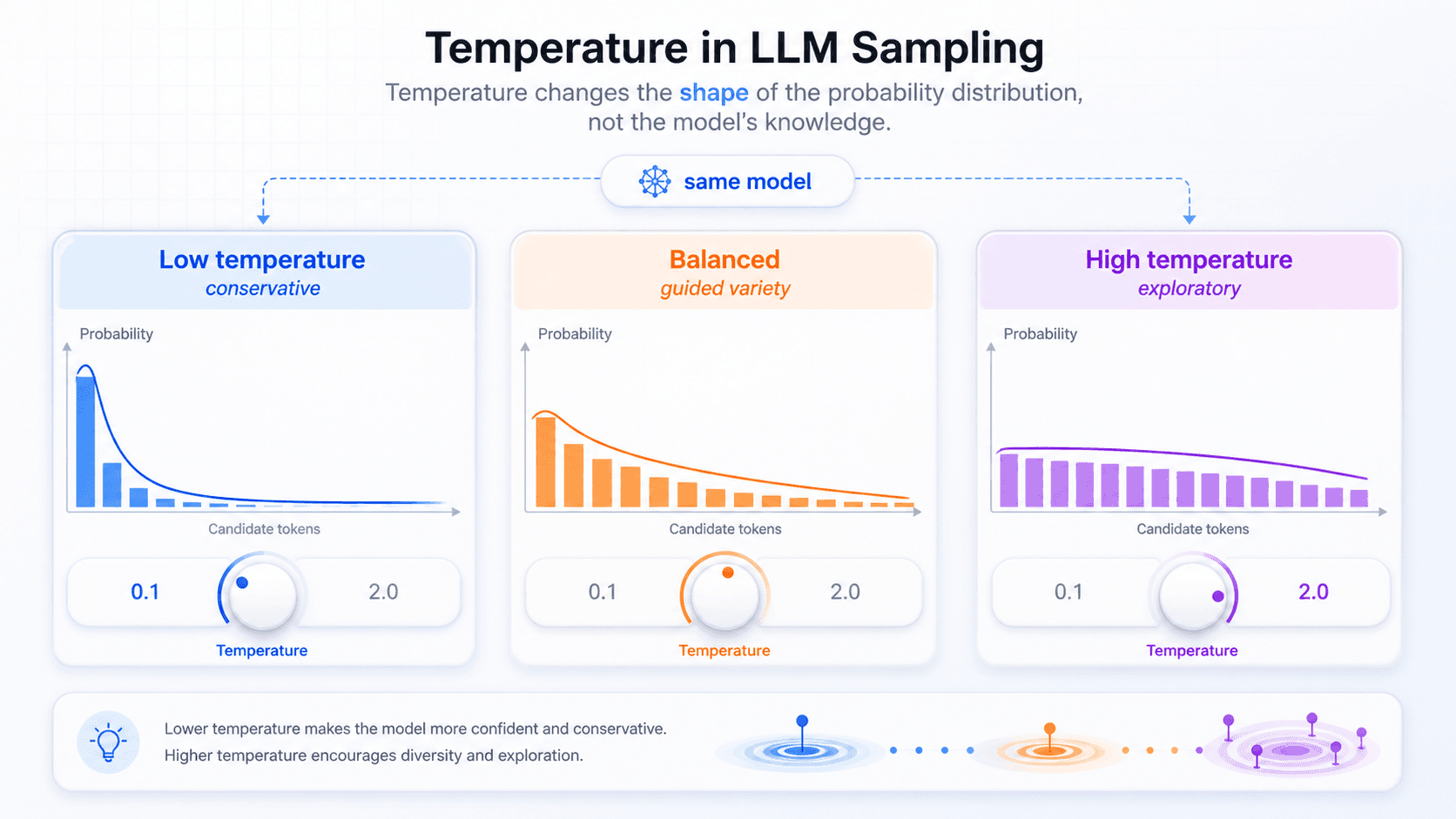
Temperature does not make the model better at reasoning. It does not add new knowledge to the model.
It changes the shape of the probability distribution before sampling.
More technically, the model first computes logits, then passes them through softmax to get probabilities. Temperature scales the logits before softmax: T=1 mostly preserves the original distribution, T<1 makes it sharper, and T>1 makes it flatter. In product settings, common values are roughly between 0 and 2. As T approaches 0, sampling behaves more like greedy decoding.
You can think of it as a randomness knob:
Low temperature: high-probability tokens become even higher, and low-probability tokens become even lower.
High temperature: the distribution becomes flatter, so more candidate tokens have a chance.At low temperature, the model behaves more like:
I will choose the most certain, conventional, safe next step.At high temperature, the model behaves more like:
I will allow more unusual expressions into the candidate set.That is why:
Code generation, field extraction, JSON output, and factual summaries usually benefit from lower temperature.
Brainstorming, naming, advertising copy, and story writing can benefit from moderately higher temperature.But higher temperature is not the same as better creativity.
If temperature is too high, low-quality tokens become easier to select, and the result may become:
loose logic;
format drift;
unstable facts;
inconsistent style;
less alignment with the user request.Another common sampling parameter is top-p.
The intuition of top-p is:
Sample only from the smallest set of candidate tokens whose cumulative probability reaches a threshold.For example, if top-p = 0.9, the system sorts tokens from high to low probability, then keeps the candidates whose cumulative probability reaches 90%, usually including the token that first pushes the cumulative total over the threshold. This filters out the long tail of very unlikely and often unstable tokens.
If temperature changes the shape of the distribution, top-p decides how large the candidate pool is.
Together, these parameters shape the stability and diversity of model output.
4. Context Window: The Model Remembers Tokens Placed in the Window
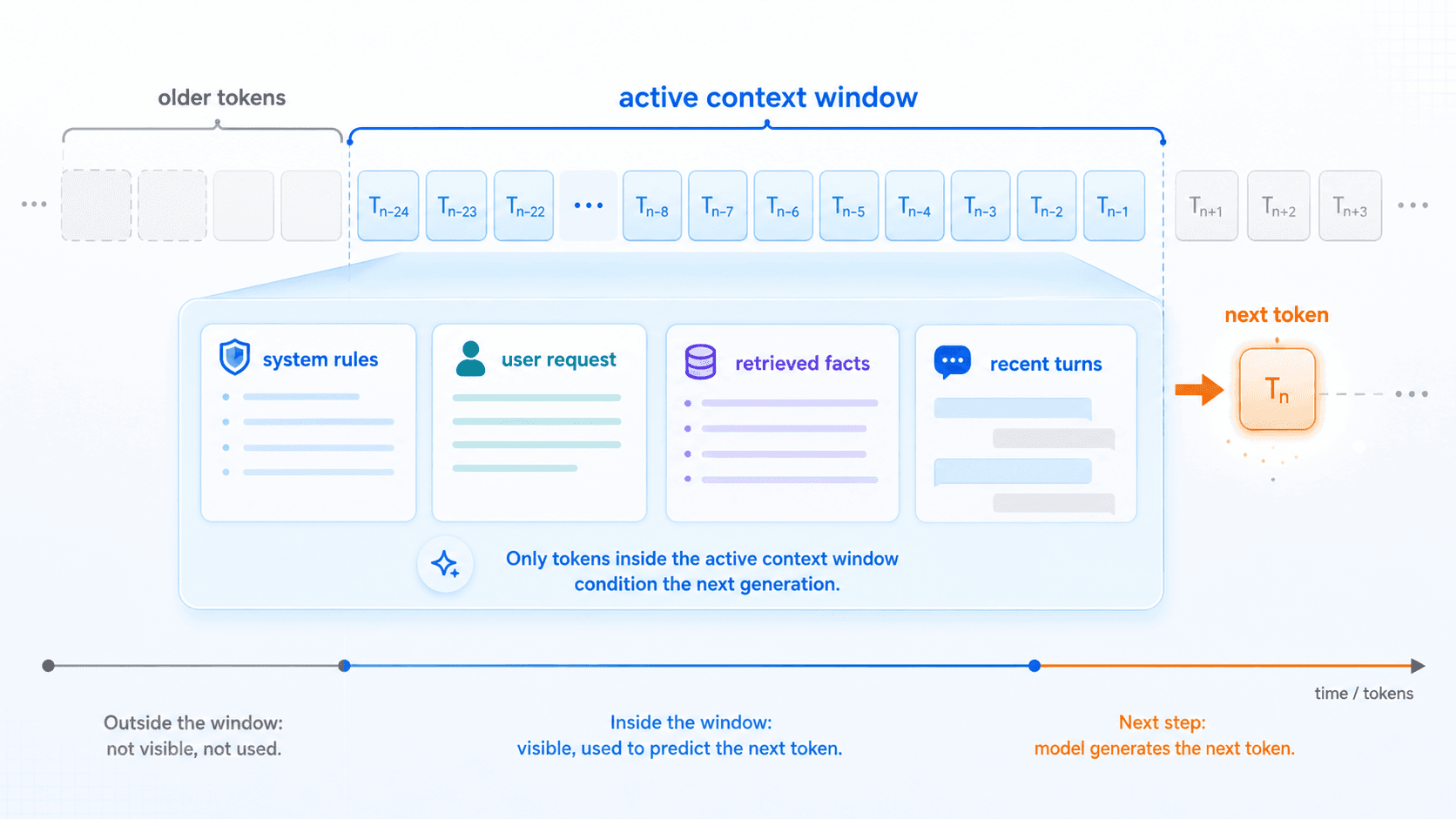
Now let us talk about the context window.
People often say:
This model has a good memory.But from first principles, what the model can actually use during one generation is the set of tokens inside the current context window.
Those tokens may include:
system prompts;
developer rules;
the current user request;
conversation history;
retrieved documents;
tool results;
the answer generated so far.Together, they form the world the model can currently “see.”
A larger context window allows the model to see more material.
But that does not mean the model has unlimited memory.
If a piece of information is not inside the current context window, the model cannot directly condition on it during this generation.
It may have seen similar patterns during training. It may guess from common sense. But that is not memory of this specific piece of information.
This explains several long-conversation problems:
early constraints get forgotten;
old information conflicts with new information;
important details are truncated;
too many retrieved documents dilute the main point;
the model struggles to focus on the truly relevant position.Long context is useful, but it is not magic.
A longer window means you can include more tokens. It also means the model must decide which tokens are relevant, which are background, which rules to follow, and which details to ignore.
For product work, context engineering includes at least four questions:
What to include: which information must enter the window.
What to remove: which history can be dropped or compressed.
How to order it: where important rules and current goals should appear.
How to verify it: whether the model actually used the key context.A good AI product does not dump every possible document into the prompt.
It is more like arranging a clean desk for the model:
the task goal is clear;
the necessary material is visible;
irrelevant noise is minimized;
important constraints are not buried.5. Token-by-Token Output: Why Answers Appear Gradually
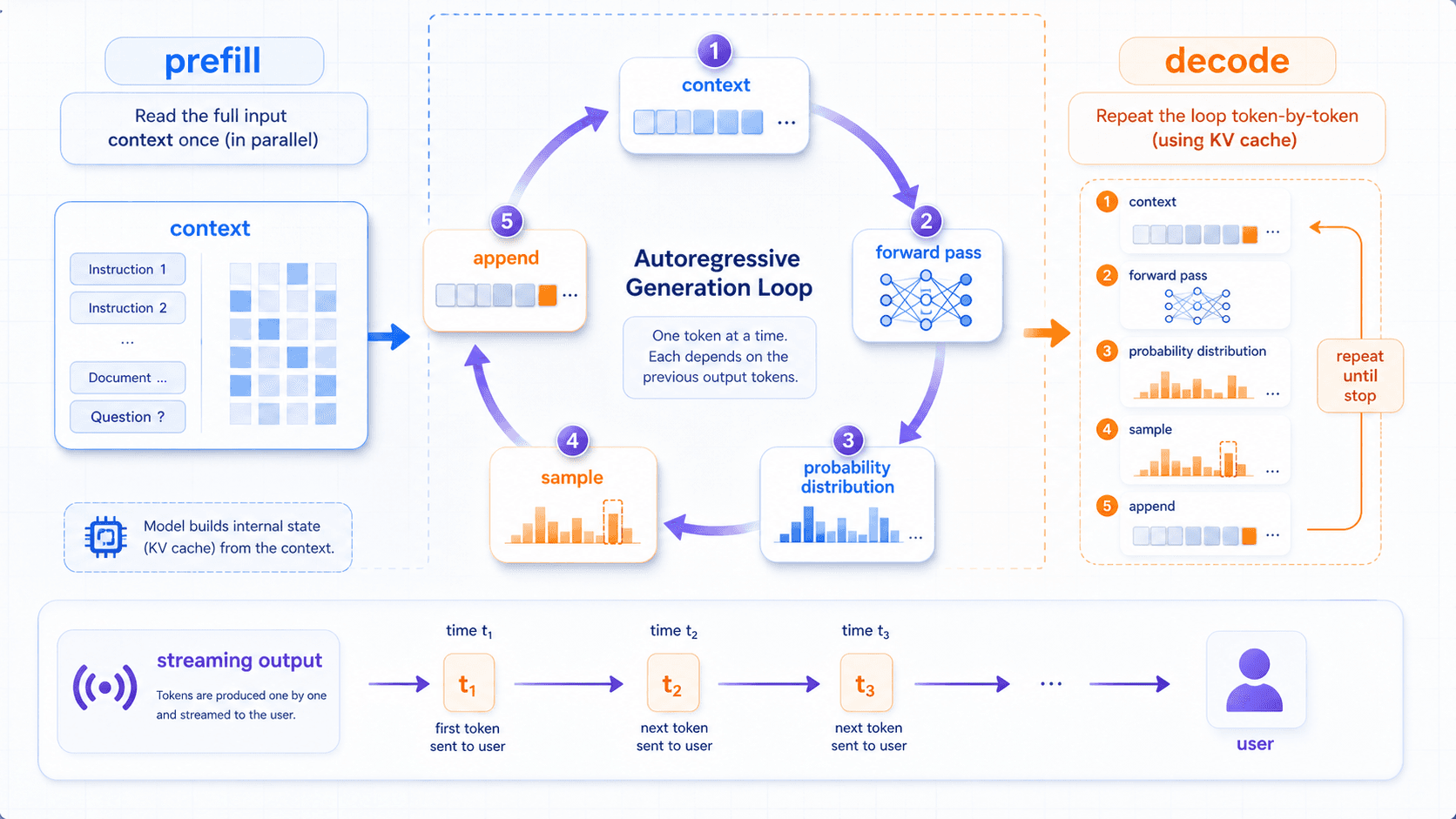
Now let us return to one of the most visible behaviors:
Why do large language models output one token at a time?It helps to separate two phases:
prefill: read the full input context;
decode: generate output one token at a time.During prefill, the model reads the system prompt, user request, conversation history, retrieved documents, and other input tokens. It computes their representations across layers and builds the KV cache used during later generation.
This phase determines how long the user waits before the first output token appears, often called time to first token.
The longer and more complex the input context is, the heavier prefill usually becomes.
During decode, the model starts producing output.
This is where autoregressive generation happens.
Autoregressive means:
The current output is appended back into the input,
becoming part of the condition for the next step.Token 1 depends on the original context.
Token 2 depends on the original context and token 1.
Token 100 depends on the original context and the first 99 generated tokens.
This is why the model cannot truly produce the final paragraph in parallel.
It can compute many representations in the input context in parallel during prefill, and the service can batch multiple user requests to improve throughput.
But for one answer, output token 37 must wait until output token 36 has been selected.
Token 36 becomes part of the context for token 37.
Engineering systems use KV cache to make this faster.
KV cache stores the key and value representations computed for previous tokens in each layer, so the model does not need to recompute the entire context from scratch for every new token.
But KV cache improves efficiency. It does not change the dependency:
The next token still has to wait until the current token has been selected.That is why output speed is often measured in tokens per second.
The model is not producing “an article” in one shot. During decode, it is continuously producing “the next token.”
For users, streaming reduces perceived waiting time.
As soon as the system receives the first output token, it can show it. It does not need to wait until the whole answer is complete.
For engineering, it creates challenges:
early token mistakes influence later tokens;
stopping midway can cut off an unfinished structure;
long answers consume more output tokens and time;
KV cache grows as context and output get longer;
without a stopping strategy, the model may keep adding irrelevant content.6. Stopping: How Does the Model Know It Is Done?
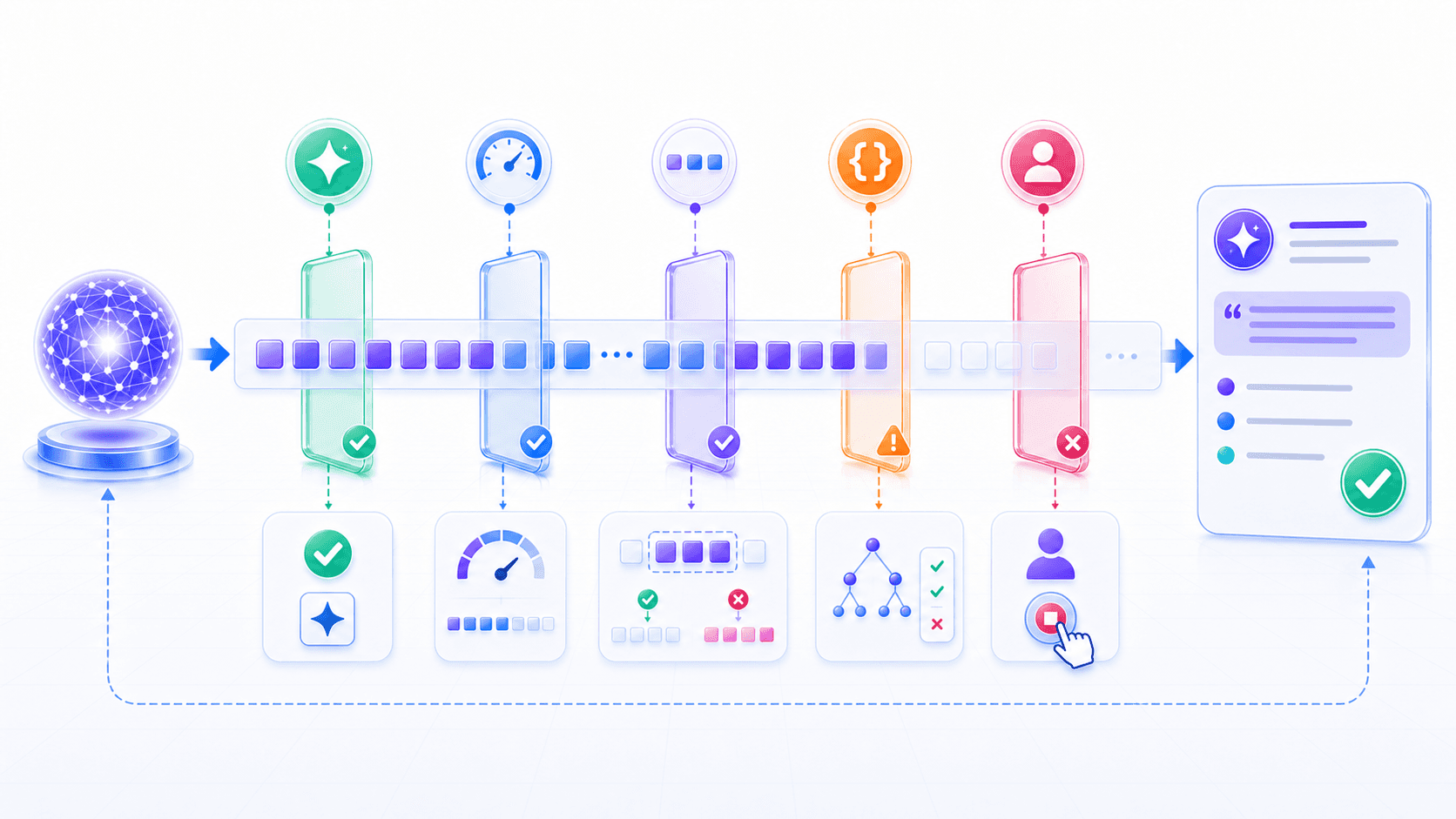
If the model generates one token at a time, when does it stop?
The answer is not mysterious.
There are usually several stopping mechanisms:
the model generates a special end token;
the output reaches the max_tokens limit;
the system sees a predefined stop sequence;
the product layer interrupts generation based on format, tool, or safety rules.From the model’s view, “ending” is just another possible next token.
When the context looks like a complete answer, the probability of an end token rises.
But the model does not always stop at exactly the right point.
It may stop too early:
only a conclusion, no explanation;
an unfinished list;
unclosed JSON;
missing final lines of code.It may also stop too late:
adding more after the summary;
expanding background after answering the question;
appending explanation after the required format is complete;
starting a new paragraph after the answer should have ended.Production systems usually do not rely entirely on the model to stop itself.
The more reliable approach is to design stopping and output constraints together.
For structured output, production systems often combine parsers, schemas, and validators: parse the JSON or tool call, check fields, types, enums, permissions, business rules, and cited evidence. Parse failures can trigger retries, but if the original task lacks enough information, the system should allow nulls, error codes, or requests for missing input instead of pressuring the model to invent fields. The full mechanism of tool calling appears in Post 10: Tool Use. For now, the important point is that stopping is not just waiting for the model to finish; the product layer needs ways to check, reject, retry, and degrade gracefully.
1. max_tokens and Post-processing: length control is not just truncation
If an answer must stay within a fixed length, max_tokens is a hard ceiling.
But max_tokens only prevents output from continuing. It does not guarantee a graceful ending.
It can cut a sentence, list, code block, or JSON object in the middle.
So fixed-length tasks often need post-processing:
remove extra prefixes or suffixes;
cut at sentence boundaries;
compress an overlong answer and regenerate;
check whether JSON, Markdown, or code blocks are closed;
send answers that violate length limits back to the model for rewriting.Post-processing is not about secretly changing the model’s answer. It is about shaping generated output into something the product can consume reliably.
2. Stop Sequences: brake at explicit boundaries
Some tasks can use stop sequences.
For example, if you only want the model to generate one field value, you can stop at a newline, delimiter, or specific tag.
This tells the system:
Once this boundary appears, stop sampling further tokens.Stop sequences work well when format boundaries are clear, but they are not universal.
If the stop sequence is too broad, it may cut valid content. If it is too weak, it may not prevent the model from continuing.
Stopping is not merely a writing issue. It is part of the generation system.
7. Product and Engineering: Treat Generation Settings as Experience Controls

Once we understand inference and generation, we can design AI products more clearly.
Many product problems are not simply “is the model smart enough?” They are:
Is the context correct?
Is sampling too exploratory?
Is the output space constrained?
Does the task need an external tool?
Can failure be detected and recovered?Different scenarios need different generation strategies.
| Scenario | Better strategy |
|---|---|
| Factual summary | Low temperature, RAG, source references, fact checks |
| Code generation | Low temperature, explicit constraints, tests or static checks |
| JSON extraction | Low temperature, schema, retry on parse failure |
| Naming and creativity | Medium-high temperature, multiple samples, human selection |
| Customer support replies | Medium-low temperature, business knowledge base, compliance boundaries |
| Long task execution | Step decomposition, tool use, state management, staged verification |
A practical rule is:
If the task needs determinism, reduce randomness and add constraints and verification.
If the task needs diversity, allow sampling, generate multiple candidates, then select.Do not make one generation parameter carry every responsibility.
Temperature controls sampling shape. It does not guarantee factual correctness.
The context window provides visible material. It does not guarantee the model focuses on the right part.
A system prompt can express rules. It does not replace permissions, validators, and evaluation.
A reliable AI product usually combines these layers:
the model provides language and reasoning capability;
context supplies the information needed for the current task;
sampling parameters shape output style and stability;
tools handle lookup, calculation, and execution;
validators detect mistakes;
product interaction lets users confirm key decisions.This is the difference between “can talk” and “is usable.”
8. Common Misunderstandings
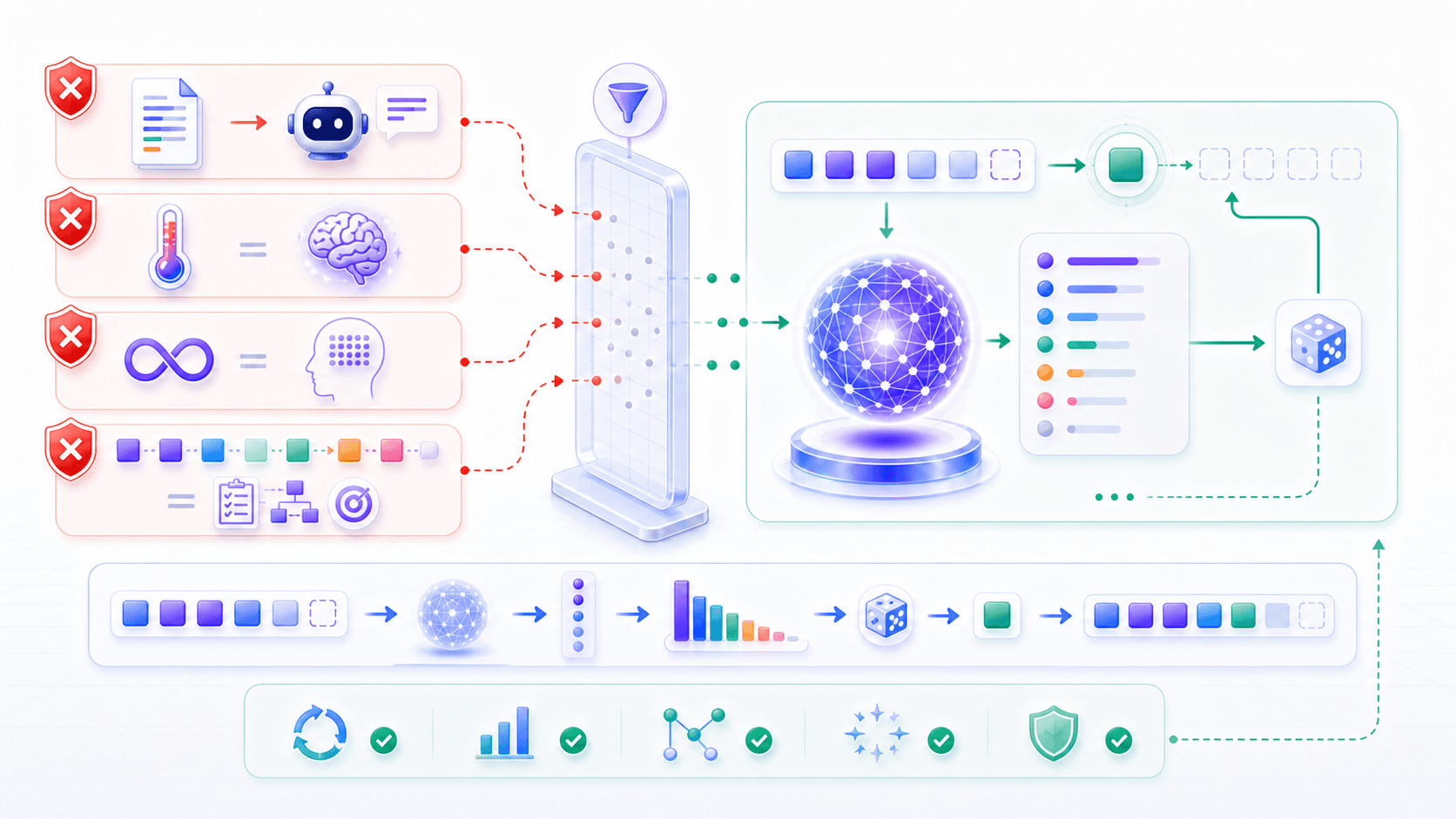
Misunderstanding 1: Higher temperature makes the model smarter.
No. Temperature changes sampling randomness, not model capability. Higher temperature can produce more variety, but it can also produce more drift.
Misunderstanding 2: Temperature 0 guarantees identical output every time.
Not always. Low temperature or greedy decoding greatly reduces randomness, but real services can still be affected by concurrency, hardware numerical differences, and server-side policies. More precisely, it is closer to deterministic, not an absolute guarantee of identical text.
Misunderstanding 3: Context window equals long-term memory.
No. The context window is the token set visible during current inference. Long-term memory requires external storage, retrieval, summarization, and state management.
Misunderstanding 4: Token-by-token output means the model cannot plan.
Not exactly. A model can express plans during generation, and it can use learned task structures in its internal representations. But the final output is still constrained by the autoregressive process: later tokens depend on earlier tokens.
Misunderstanding 5: Longer context is always better.
Not always. Longer context can hold more information, but it can also introduce noise, conflicts, and attention dilution. The goal is not to fill the window. The goal is to make important information clearly visible.
9. Technical Appendix: What Reasoning Models and Test-Time Compute Change
Recent reasoning models raise a natural question: if models still generate token by token, why does giving them more “thinking time” improve complex tasks?
The key is that token-by-token generation has not been overturned. The system gives the model more inference budget.
You can think of it this way:
ordinary generation: quickly walk one token path from the current context;
reasoning models: before final output, use more intermediate steps to search, check, revise, and compress a solution path;
test-time compute: spend more computation during inference, not only during training.This has two direct product implications.
First, reasoning quality depends not only on model parameters, but also on how much compute, latency, and cost you are willing to spend on one request. Second, reasoning models are especially useful for math, code, planning, and complex analysis. They are not always the right choice for casual chat, rewriting, or low-risk replies.
So a reasoning model is not a model that suddenly escapes token generation. It is a model operating inside the same generation framework, but spending more inference budget to find a more reliable path for complex tasks.
10. Summary: Generation Is a Probability Path, Not Answer Printing
We can compress this post into a few sentences:
During inference, the model computes a next-token probability distribution from the current context.
A sampling strategy selects one token from that distribution.
The selected token is appended back into the context.
The loop repeats until a stopping condition is met.
Temperature, top-p, context window, and stopping strategy shape the final output together.Compressed into one sentence:
A large language model does not generate a prewritten answer. It walks a token path shaped by context, probability distributions, and sampling strategy.
Once we understand this, model output no longer looks like mysterious inspiration. It also no longer looks like a simple database lookup.
It is making probability choices at every step.
The job of product and engineering is to make the context clearer, the candidate space more appropriate, and mistakes easier to detect, so a probabilistic path becomes an experience users can trust.
11. Three Questions You Should Be Able to Answer
After reading this post, try answering these in your own words:
- Do temperature and top-p change model capability, or sampling behavior?
- Why does the context window provide visibility, not long-term memory or guaranteed attention?
- Why can reasoning models trade more test-time compute for better complex-task performance?
Next, we will examine one of the most important and most misunderstood problems: hallucination. Why can a model confidently say false things? What is the relationship between hallucination, the training objective, probabilistic generation, and the boundary of knowledge?