07:推理与生成:temperature、上下文窗口和逐 token 输出
这是「用第一性原理理解大模型」系列的第 7 篇。第 6 篇:Scaling Law 与涌现 解释了为什么规模会改变模型的能力边界。现在我们看模型真正回答问题时发生了什么:同一个模型,为什么有时稳定、有时发散?为什么调 temperature 会改变风格?为什么上下文窗口会限制模型记忆?为什么它总是一个 token 一个 token 地输出?
前几篇文章,我们一直在讲模型是如何被训练出来的:
预训练让模型学会语言和世界结构;
微调让模型学会回应用户指令;
对齐让模型更倾向于有帮助、诚实、安全的行为;
规模让更多任务跨过可用阈值。但当你真正使用一个大模型时,发生的是另一个过程:
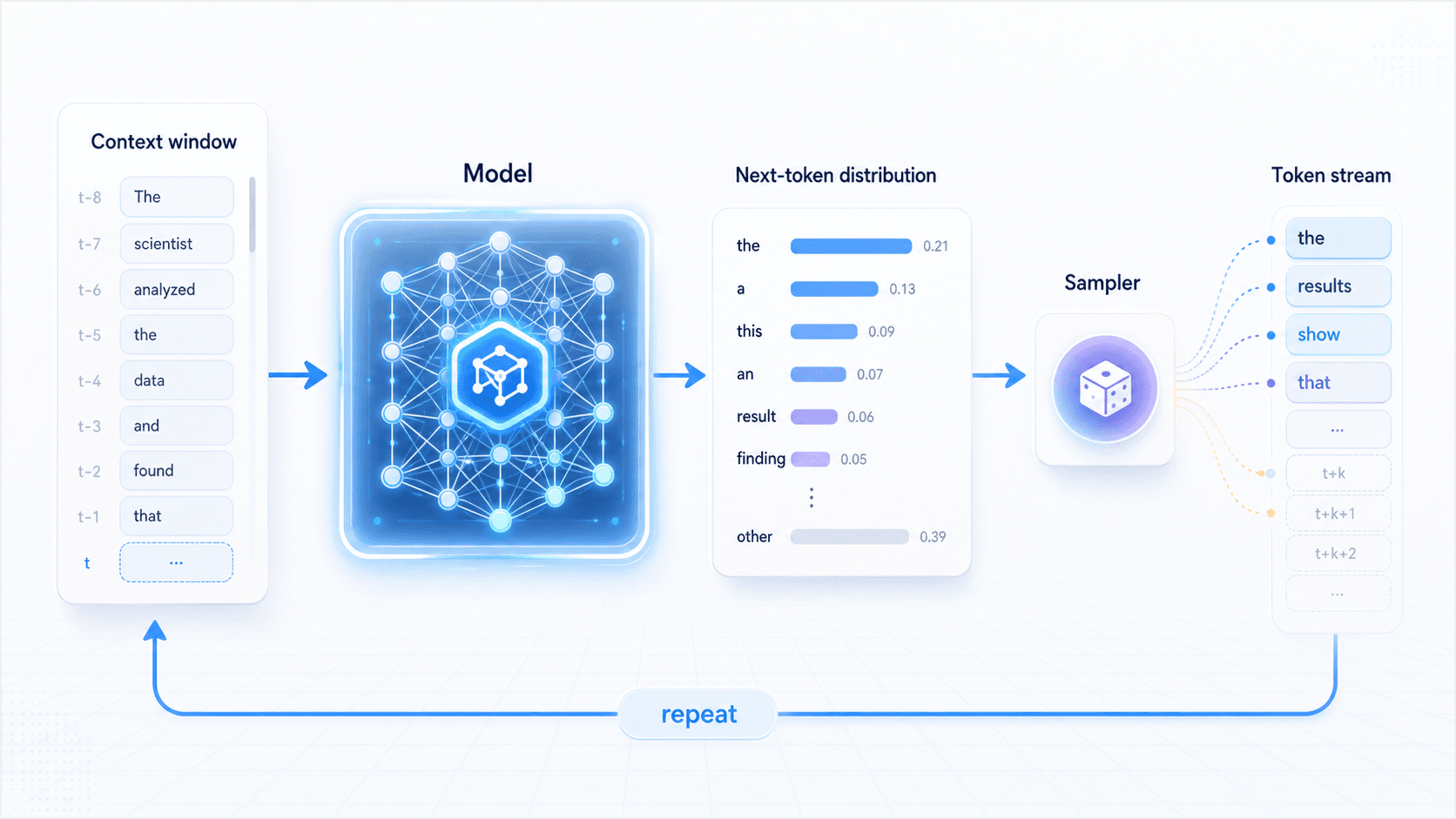
给它一段上下文;
模型计算下一个 token 的概率分布;
系统从这个分布里选出一个 token;
把这个 token 接回上下文;
然后重复。这个过程叫推理,也可以叫生成。
理解这一层之后,很多使用体验都会变得不神秘:
为什么同一个问题多问几次,回答会不一样;
为什么 temperature 低时更稳定,高时更发散;
为什么上下文太长后,模型会漏掉前面的信息;
为什么模型会流式输出,而不是一次性把完整答案吐出来;
为什么它有时会越写越偏,有时又能沿着目标稳定推进。本文的核心句是:
推理不是模型先想好完整答案再打印出来,而是不断把上下文变成下一 token 分布,再通过采样把一个个 token 接出来。
一、推理不是「把答案想好再吐出来」
先从一个直觉误区开始。
当你问模型:
请用一句话解释什么是梯度下降。我们很容易想象,模型像人一样先在脑子里想好一句完整答案:
梯度下降是一种通过沿着损失函数下降方向逐步调整参数的优化方法。然后再把这句话从头到尾打出来。
但大模型的生成方式不是这样。
更准确地说,模型在第一步并没有拿到一个「完整答案对象」。
它拿到的是当前上下文,然后计算:
如果只看现在这些 token,
下一个 token 的概率分布应该是什么样?也就是说,模型并没有在第一步就固定完整答案。
它更像是在一条还没有完全确定的路上往前走。
第一步可能走向:
梯度……
它……
这是一种……每个开头都会改变后面更自然的延续方式。
如果它先选了「梯度」,后面很可能进入定义式表达。
如果它先选了「它」,后面更像口语解释。
如果它先选了「这是一种」,后面可能进入类比或功能描述。
所以,大模型生成答案时,不是从仓库里取出一段已经写好的文字,而是在概率空间里逐步确定一条表达路径。
这条路径一旦开始,就会逐渐产生惯性。
前面选出的词,会影响后面更容易出现的词。
前面采用的结构,会影响后面继续沿用的结构。
前面隐含的事实假设,也会影响后面继续展开的方向。
这就是为什么一个早期的小偏差,可能慢慢放大成后面的跑题、啰嗦或幻觉。
这也是为什么提示词、上下文管理和输出约束很重要。
它们不是在「命令模型脑子里想什么」,而是在塑造每一步生成时可见的上下文,让下一 token 分布更接近我们希望的方向。
二、下一 token 分布:模型每一步都在给候选项打分
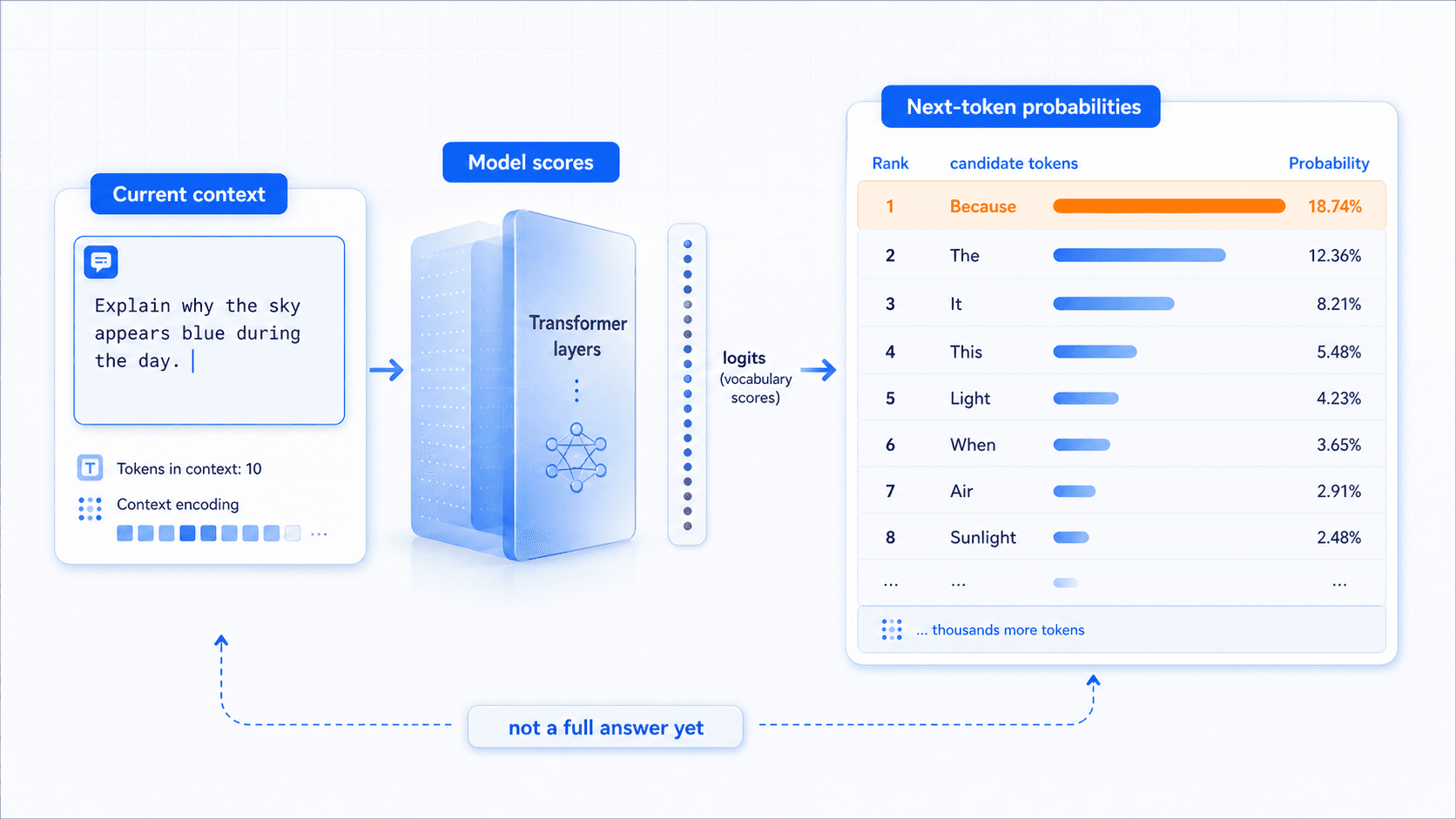
推理时,模型输出的第一样东西不是一句话,而是一组分数。
更准确地说,模型会对词表里的每个可能 token 给出一个原始分数。工程上常叫 logits。
这些分数经过转换后,会变成概率分布:
token A:概率 42%
token B:概率 24%
token C:概率 15%
其他 token:概率更低这意味着模型在每一步面对的不是一个唯一答案,而是一张候选表。
比如上下文是:
请用一句话解释什么是梯度下降。模型可能判断,接下来比较合理的 token 有很多种:
「梯度」
「它」
「这」
「一种」每种开头都可以通向一个合理答案。
如果选择「梯度」,后面可能会生成:
梯度下降是一种优化方法……如果选择「它」,后面可能会生成:
它是一种让模型参数逐步变好的方法……如果选择「这」,后面可能会生成:
这是一种通过不断调整参数来降低错误的方法……这些都不一定错,只是表达路径不同。
所以大模型的生成不是「检索唯一正确句子」,而是从一个概率分布里走出一条路径。
这也是为什么同一个模型可以同时表现出两种性质:
它很稳定,因为高概率 token 往往符合语义和任务;
它又不完全确定,因为概率分布里通常不止一条合理路径。训练阶段,模型通过真实下一个 token 来调整参数。
推理阶段,参数已经固定。模型不再学习,只是在给定上下文下计算分布,然后由采样策略决定走哪条路径。
三、采样与 temperature:同一个模型为什么会有不同回答
有了下一 token 分布后,系统要做一个选择。
最直接的方法是永远选概率最高的 token。
这叫 greedy decoding,可以理解成「每一步都选最稳的」。
这种方式通常更稳定,但也可能带来问题:
表达变得保守;
回答容易重复;
创意任务显得平;
一旦早期选错,也没有机会探索其他路径。另一种方式是采样。
采样不是随便乱选,而是按概率分布来选:
概率高的 token 更容易被选中;
概率低的 token 也有小概率被选中;
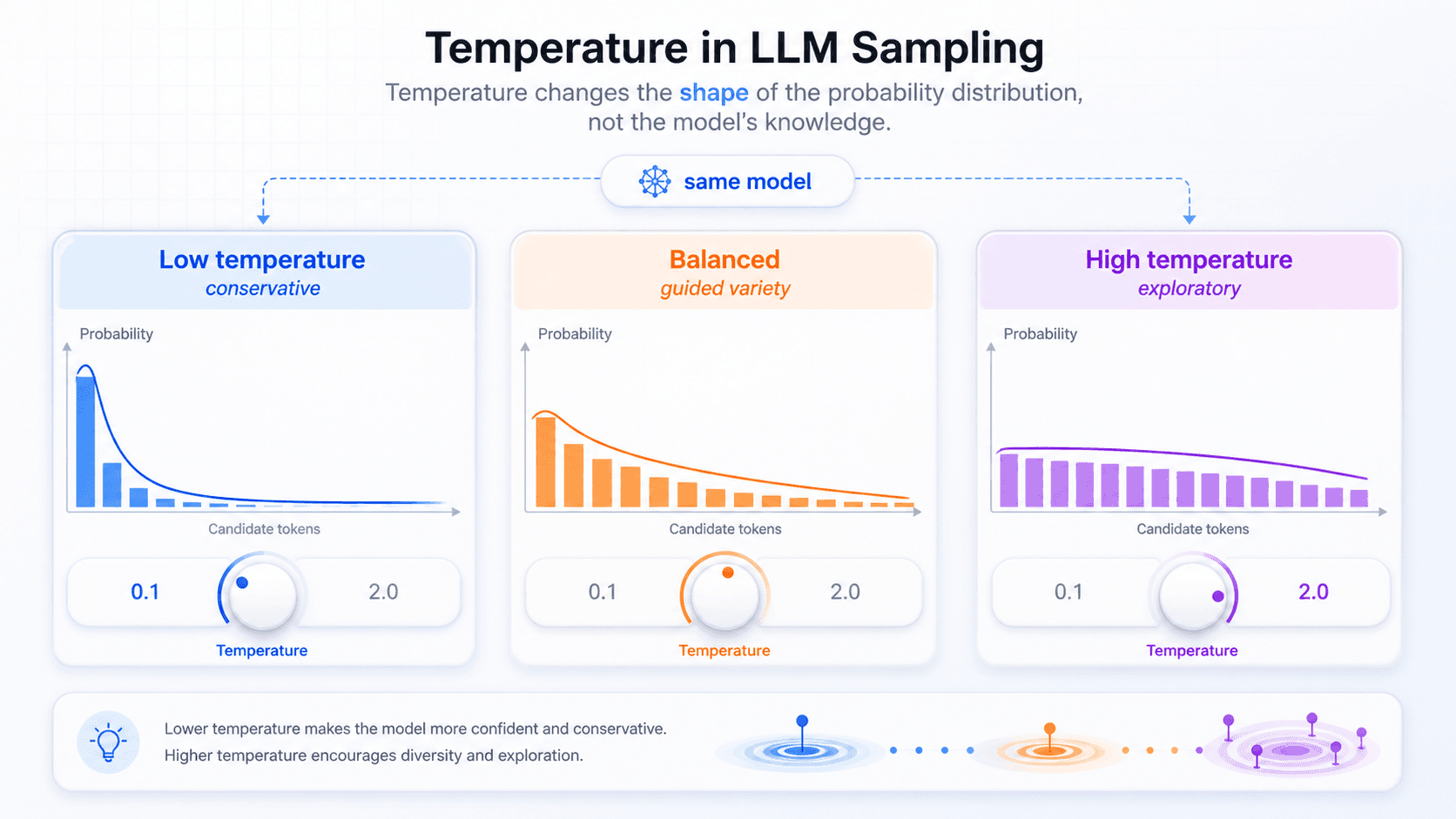
概率极低的 token 通常会被过滤掉。这就引出了 temperature。
temperature 不会改变模型本身会不会推理,也不会给模型增加新知识。
它改变的是采样前概率分布的形状。
更技术一点说,模型先算出一组 logits,再经过 softmax 变成概率。temperature 会在 softmax 之前缩放 logits:T=1 基本保留原始分布,T<1 会让分布更尖,T>1 会让分布更平。实际产品里常见范围大致在 0 到 2 之间;当 T 接近 0 时,采样会退化得很像 greedy decoding。
可以把它理解成一个「随机性旋钮」:
低 temperature:把高概率 token 变得更高,低概率 token 变得更低;
高 temperature:把分布拉平,让更多候选 token 有机会被选中。所以 temperature 低时,模型通常更像是在说:
我优先选择最确定、最常规、最安全的下一步。temperature 高时,模型更像是在说:
我允许更多不那么常规的表达进入候选范围。这就是为什么:
写代码、抽取字段、生成 JSON、总结事实时,通常应该降低 temperature;
头脑风暴、命名、广告文案、故事创作时,可以适当提高 temperature。但要注意,temperature 不是越高越有创造力。
过高的 temperature 会让低质量 token 也更容易被选中,结果可能变成:
逻辑松散;
格式漂移;
事实不稳;
前后风格不一致;
越写越不像用户要的东西。除了 temperature,常见采样参数还有 top-p。
top-p 的直觉是:
只从累计概率达到某个阈值的候选 token 集合里采样。比如 top-p = 0.9,系统会先按概率从高到低排列 token,然后只保留累计概率达到 90% 的那部分候选,通常也包含让累计概率首次超过阈值的那个 token。这样可以过滤掉尾部那些概率很低、质量可能不稳定的 token。
如果说 temperature 是改变分布形状,top-p 更像是决定「候选池开多大」。
这两个参数常常一起影响模型输出的稳定性和多样性。
四、上下文窗口:模型记住的是被放进窗口的 token
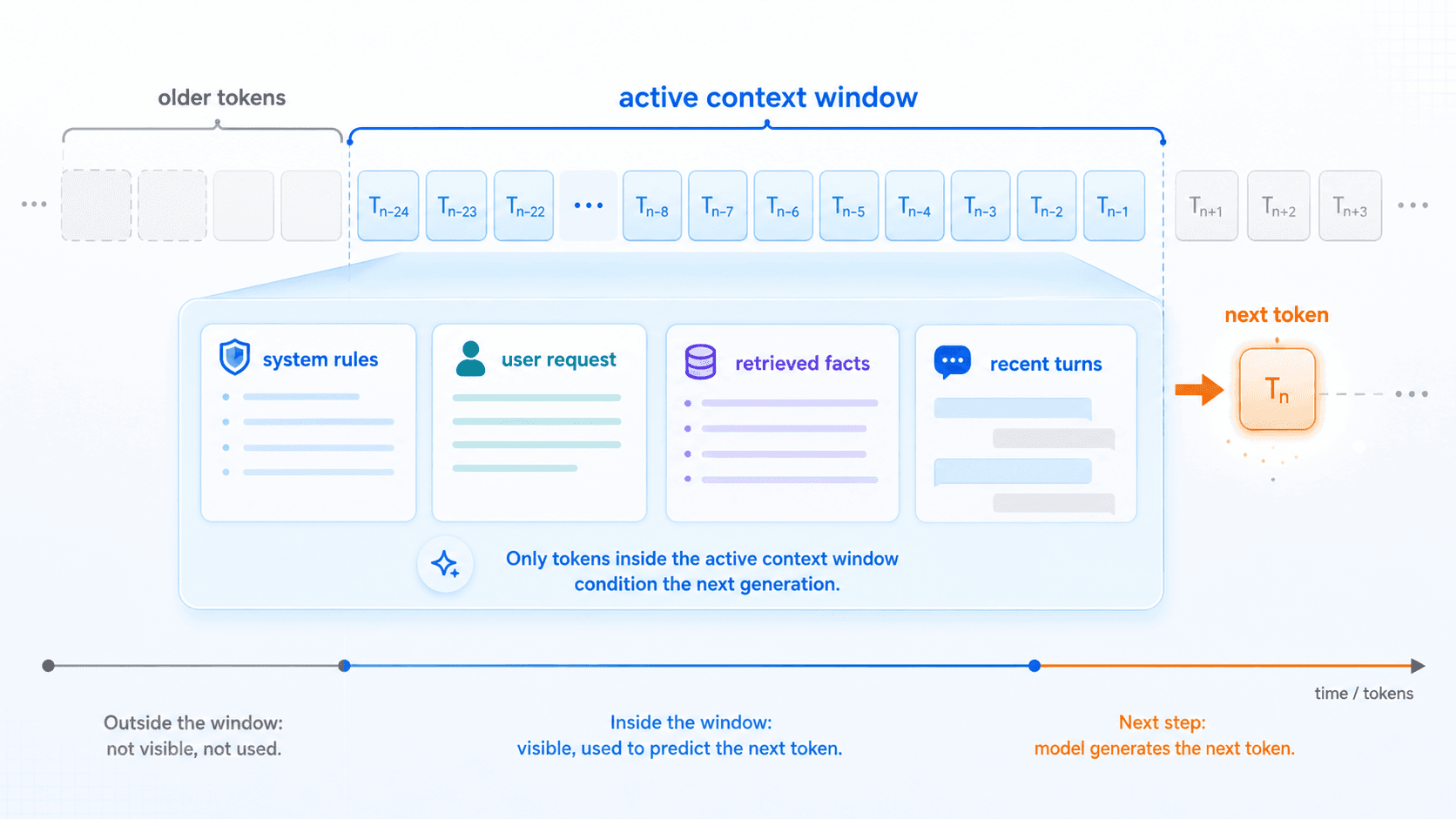
接下来讲上下文窗口。
很多人会说:
这个模型记忆很好。但从推理第一性原理看,模型在一次生成中真正能利用的是当前上下文窗口里的 token。
这些 token 可能包括:
系统提示词;
开发者规则;
用户当前问题;
历史对话;
检索到的资料;
工具返回结果;
模型已经生成的部分回答。它们一起组成模型当下能「看见」的世界。
上下文窗口越大,模型能看到的材料越多。
但这不等于模型拥有了无限记忆。
如果一条信息没有被放进当前上下文窗口,模型在这一轮生成时就不能直接基于它来预测下一个 token。
它也许在训练中见过类似模式,也许能靠常识猜测,但那不是对这条具体信息的记忆。
这解释了为什么长对话会出现几类问题:
早期约束被遗忘;
旧信息和新信息冲突;
重要细节被截断;
检索资料太多,反而稀释了重点;
模型在长上下文里抓不住真正该关注的位置。长上下文很有用,但不是魔法。
更长的窗口意味着可以塞进更多 token,也意味着模型要在更多 token 里判断哪些相关、哪些不相关、哪些应该服从、哪些只是背景。
对产品来说,上下文工程至少包括四件事:
放什么:哪些信息必须进入窗口;
删什么:哪些历史可以丢弃或压缩;
排什么顺序:重要规则和最新目标放在哪里;
如何验证:模型是否真的使用了关键上下文。所以,好的 AI 产品不是把所有材料都一股脑塞进 prompt。
它更像是在给模型布置一张干净的桌面:
任务目标清楚;
必要资料可见;
无关噪声尽量少;
重要约束不会被淹没。五、逐 token 输出:为什么回答会一小段一小段出现
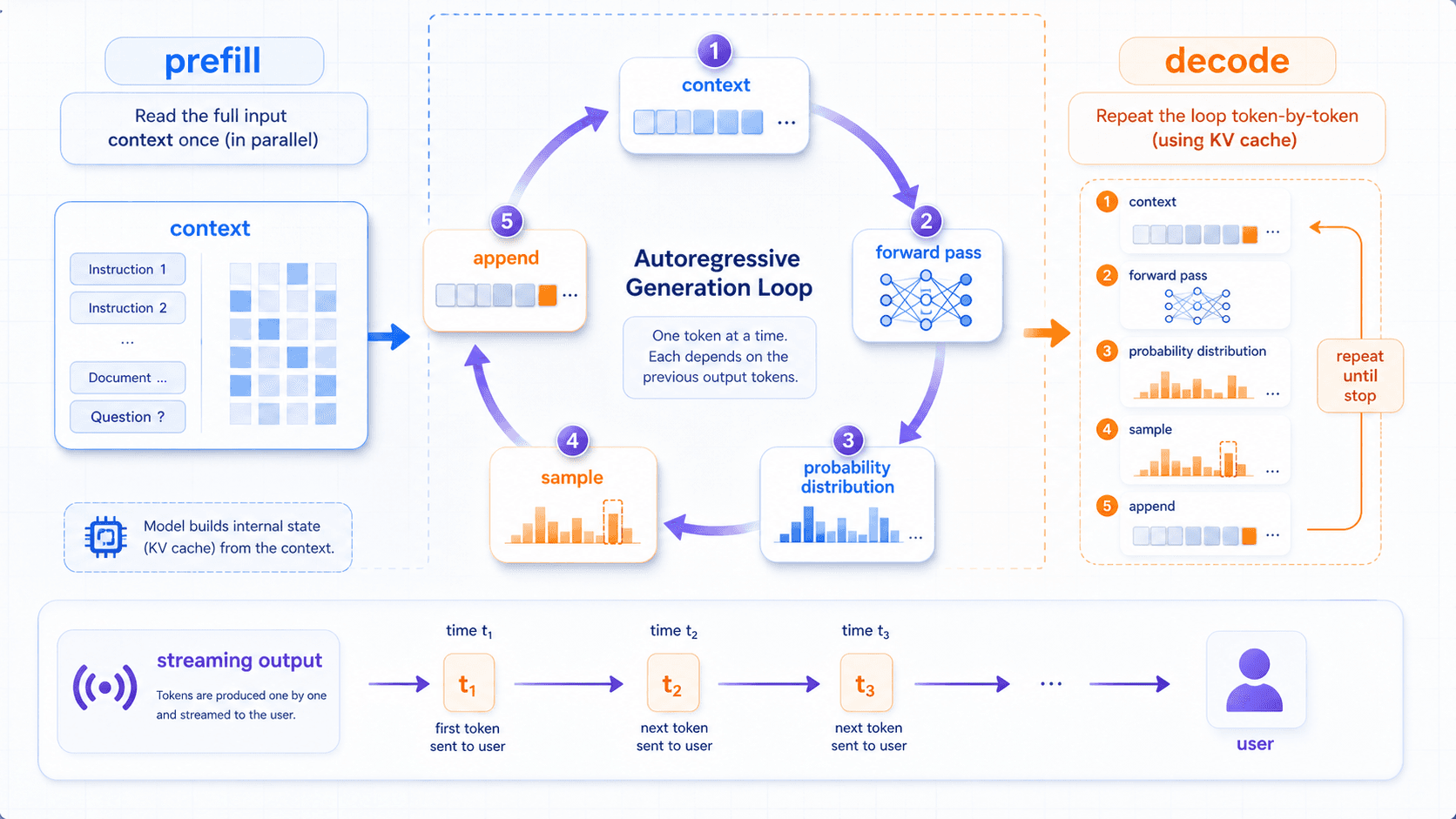
现在我们再回到一个最直观的体验:
为什么大模型总是一个 token 一个 token 地输出?这里要区分两个阶段:
prefill:先读完整个输入上下文;
decode:再逐 token 生成输出。prefill 阶段,模型会把系统提示词、用户问题、历史对话、检索资料等输入 token 一次性读进去,计算它们在各层里的表示,并建立后续生成要用的 KV cache。
这一阶段决定了「第一个 token 出来前要等多久」,也就是很多服务里说的首 token 延迟。
输入越长、上下文越复杂,prefill 通常越重。
decode 阶段,模型开始生成输出。
这时才进入我们常说的自回归生成。
自回归的意思是:
当前输出会被接回输入,
成为下一步生成的条件。第 1 个 token 依赖原始上下文。
第 2 个 token 依赖原始上下文和第 1 个 token。
第 100 个 token 依赖原始上下文和前 99 个 token。
这就是为什么模型不能真正并行地产生整段最终答案。
它可以在 prefill 阶段并行计算输入里很多 token 的表示,也可以在服务端把多个用户请求组成 batch 来提高吞吐。
但对同一个回答来说,第 37 个输出 token 必须等第 36 个输出 token 已经确定。
因为第 36 个 token 会成为第 37 个 token 的上下文。
工程上,KV cache 可以让这个过程更快。
它会缓存前文 token 在各层里计算出的 key 和 value,避免每生成一个新 token 都从头重算整段上下文。
但 KV cache 解决的是计算效率,不改变生成依赖关系:
下一个 token 仍然要等当前 token 选出来以后才能生成。这也是为什么输出速度常用 token per second 来衡量。
模型不是一次性生产「一篇文章」,而是在 decode 阶段持续生产「下一个 token」。
对用户来说,流式输出的好处是降低感知等待时间。
系统只要拿到第一个输出 token,就可以先展示出来,不必等整段回答全部生成完成。
对工程来说,它也带来一些挑战:
早期 token 的错误会影响后续;
中途停止会截断未完成的结构;
长回答会消耗更多输出 token 和时间;
KV cache 会随着上下文和输出变长而变大;
如果没有停止策略,模型可能持续补充无关内容。六、停止生成:模型什么时候知道该结束
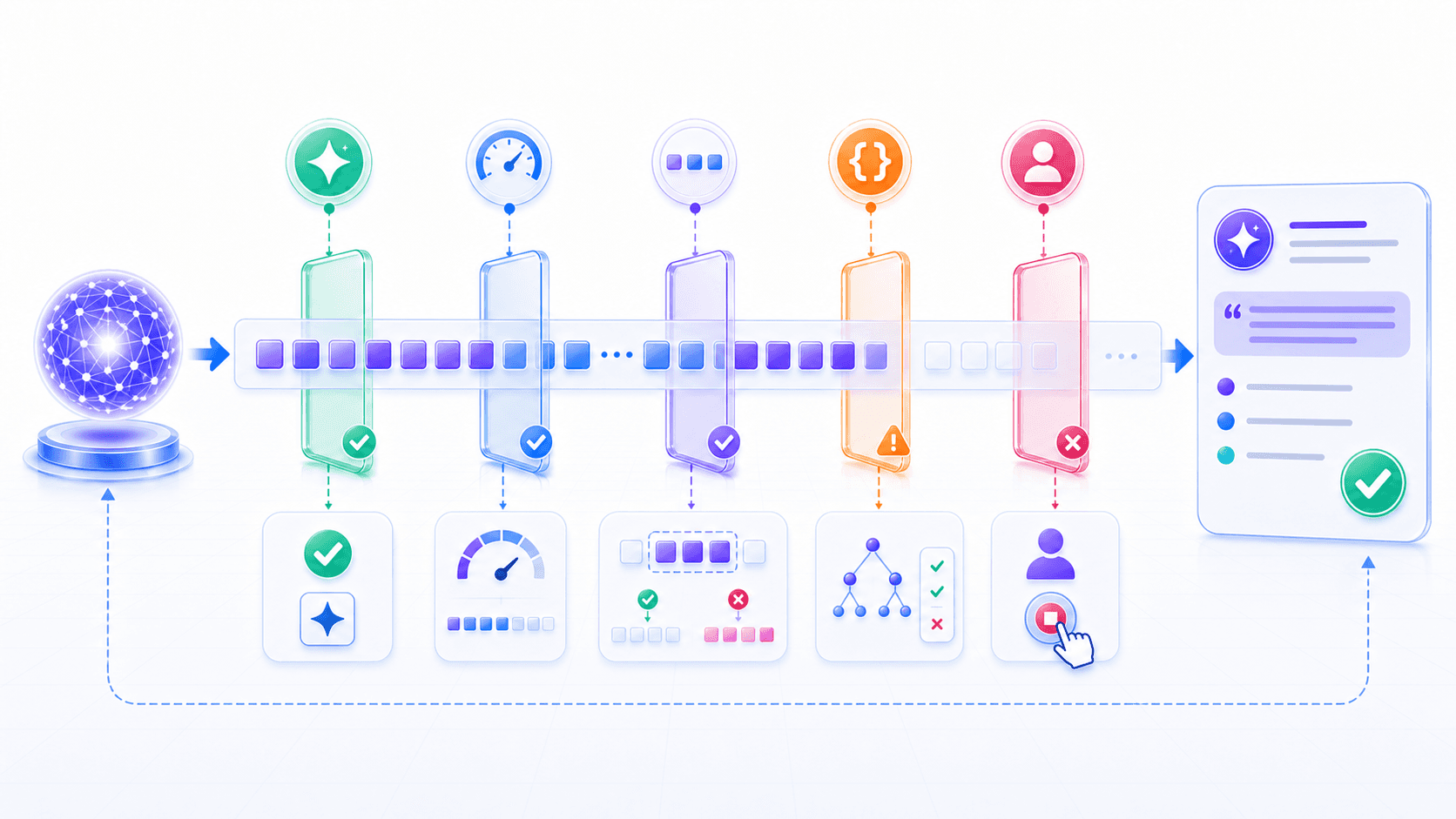
既然模型是一 token 一 token 地生成,那它什么时候停下来?
答案并不神秘。
通常有几类停止方式:
模型生成了表示结束的特殊 token;
输出达到 max_tokens 限制;
系统遇到预设 stop sequence;
产品层根据格式、工具调用或安全策略中断生成。从模型角度看,「结束」也只是下一个 token 的一种可能。
当上下文看起来像一个完整回答已经结束时,结束 token 的概率会上升。
但模型并不总是判断得刚好。
它可能停得太早:
只给结论,没有解释;
列表没写完;
JSON 结构没闭合;
代码少了最后几行。也可能停得太晚:
总结后又开始补充;
回答完问题后继续扩展背景;
格式已经完成,但还在追加解释;
一段话结束后又开启新段落。所以生产系统通常不会完全依赖模型自己停。
更稳的做法,是把「停止」和「输出约束」一起设计。
对于结构化输出,系统通常会把解析器、schema 和验证器连在一起:先确认 JSON 或工具调用能被解析,再检查字段、类型、枚举、权限、业务规则和引用依据。解析失败时可以重试,但如果原始信息不足,系统应该允许返回空值、错误码或补充信息请求,而不是逼模型编字段。工具调用的完整机制会在第 10 篇:Tool Use 里展开;这里先记住一点:停止生成不是只等模型说完,而是要让产品层能检查、拒绝、重试和降级。
1. max_tokens 和后处理:控制长度不只是截断
如果回答必须在固定长度内,max_tokens 是一道硬上限。
但 max_tokens 只会阻止输出继续变长,不会保证文本优雅结束。
它可能把句子、列表、代码或 JSON 截断在中间。
所以固定长度任务通常还需要后处理:
去掉多余前后缀;
截断到句子边界;
压缩超长回答后重新生成;
检查 JSON、Markdown、代码块是否闭合;
把不符合长度要求的答案送回模型改写。后处理不是为了「偷偷改模型答案」,而是为了把生成结果整理成产品可以稳定消费的形状。
2. stop sequence:用边界标记提前刹车
有些场景可以设置 stop sequence。
比如你只想要模型生成一个字段值,就可以在换行、分隔符或特定标签处停止。
这相当于告诉系统:
一旦生成到这个边界,就不要继续往下采样了。它适合格式边界清楚的任务,但不适合所有任务。
如果 stop sequence 设计得太粗糙,可能会误伤正常内容;如果设计得太弱,又挡不住模型继续补充。
停止不是一个写作问题,而是生成系统的一部分。
七、产品和工程:把生成参数当成体验旋钮

理解推理与生成后,我们就能更清楚地设计 AI 产品。
很多产品问题,本质上不是「模型聪不聪明」,而是:
上下文是否给对;
采样是否太发散;
输出空间是否被约束;
任务是否需要外部工具;
失败是否能被检测和恢复。不同场景应该使用不同的生成策略。
| 场景 | 更适合的策略 |
|---|---|
| 事实总结 | 低 temperature、RAG、引用来源、校验关键事实 |
| 代码生成 | 低 temperature、明确约束、测试或静态检查 |
| JSON 抽取 | 低 temperature、schema、解析失败重试 |
| 命名和创意 | 中高 temperature、多采样、人工挑选 |
| 客服回复 | 中低 temperature、业务知识库、合规边界 |
| 长任务执行 | 拆步骤、工具调用、状态管理、阶段性验证 |
一个很实用的判断是:
如果任务要求确定性,就减少随机性,增加约束和验证;
如果任务要求多样性,就允许采样,生成多个候选,再筛选。不要让一个生成参数承担所有责任。
temperature 只能控制采样形状,不能保证事实正确。
上下文窗口只能提供可见材料,不能保证模型关注重点。
system prompt 可以表达规则,但不能替代权限、校验和评估。
一个可靠的 AI 产品,通常会把这些层组合起来:
模型负责语言和推理能力;
上下文负责给足当前任务所需信息;
采样参数负责输出风格和稳定性;
工具负责查询、计算和执行;
校验器负责发现错误;
产品交互负责让用户确认关键节点。这就是从「会说」走向「可用」的关键。
八、常见误解
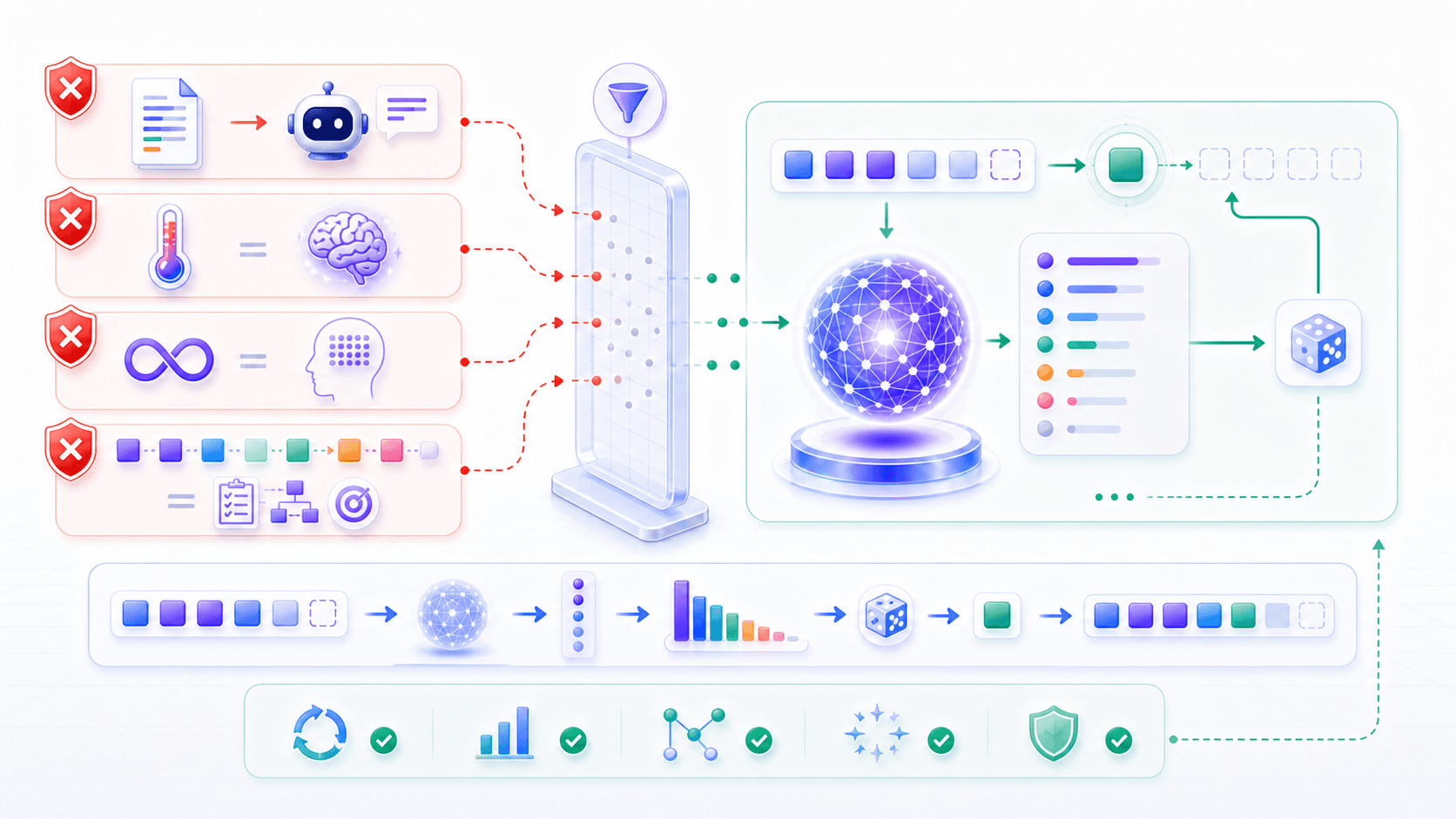
误解一:temperature 越高,模型越聪明。
不对。temperature 改变的是采样随机性,不是模型能力。高 temperature 可能带来更多创意,也可能带来更多漂移。
误解二:temperature 为 0 就一定完全确定。
不一定。低 temperature 或 greedy decoding 会显著降低随机性,但真实服务里还可能受到并发、硬件数值差异、服务端策略等因素影响。更准确地说,它是更接近确定,而不是绝对保证每次字字相同。
误解三:上下文窗口等于长期记忆。
不对。上下文窗口是当前推理可见的 token。长期记忆需要外部存储、检索、摘要和状态管理来实现。
误解四:逐 token 输出说明模型没有规划能力。
不完全。模型可以在生成过程中表达计划,也可以在内部表示里利用学到的任务结构。但最终输出仍然受自回归过程约束,后面的 token 依赖前面的 token。
误解五:上下文越长越好。
不一定。更长上下文能容纳更多信息,但也可能引入噪声、冲突和注意力稀释。关键不是塞满,而是让重要信息清楚可见。
九、技术附录:推理模型和 test-time compute 改变了什么
近年的推理模型会让人产生一个疑问:如果模型仍然是逐 token 生成,为什么给它更多「思考时间」会提升复杂任务表现?
关键在于,逐 token 生成没有被推翻,但系统给了模型更多推理预算。
你可以把它理解成:
普通生成:更快地从当前上下文走出一条 token 路径;
推理模型:在输出最终答案前,用更多中间步骤搜索、检查、修正和压缩解题路径;
test-time compute:把更多计算放到推理阶段,而不只是训练阶段。这对产品有两个直接含义。
第一,推理能力不只取决于模型参数,也取决于愿意在单次请求里花多少计算、延迟和成本。第二,推理模型更适合数学、代码、规划、复杂分析等高价值任务,不一定适合所有闲聊、改写和低风险回复。
所以,推理模型不是「模型突然脱离 token 生成」,而是在同一个生成框架里,用更多推理预算换取更稳的复杂任务路径。
十、总结:生成是概率路径,不是答案打印
现在我们可以把本文压缩成几句话:
推理时,模型根据当前上下文计算下一 token 的概率分布;
采样策略从分布里选出一个 token;
被选中的 token 会追加回上下文;
这个循环不断重复,直到遇到停止条件;
temperature、top-p、上下文窗口和停止策略共同塑造最终输出。如果再压缩成一句话:
大模型生成的不是预先写好的答案,而是在上下文、概率分布和采样策略共同作用下走出的一条 token 路径。
理解这一点后,我们就不会把模型输出看成神秘的「灵感」,也不会把它误解成简单的「查表」。
它是在每一步做概率选择。
而产品和工程的任务,就是让每一步的上下文更清楚、候选空间更合适、错误更容易被发现,最终把一条概率路径变成用户可以信任的体验。
十一、你应该能回答的三个问题
读完这一篇,可以试着用自己的话回答:
- temperature 和 top-p 改变的是模型能力,还是采样方式?
- 为什么上下文窗口提供的是「可见范围」,不是长期记忆或可靠注意力?
- 推理模型为什么可以用更多 test-time compute 换取复杂任务表现?
下一篇,我们会继续拆一个最重要、也最容易被误解的问题:幻觉。为什么模型会一本正经地胡说?它和训练目标、概率生成、知识边界之间到底是什么关系?