10:Tool Use:让大模型从「会说」走向「会做」
这是「用第一性原理理解大模型」系列的第 10 篇。第 9 篇:RAG 解释了如何把外部知识放进上下文,让模型从「凭印象生成」走向「基于证据生成」。现在我们继续往前走一步:如果任务不只是读资料,而是要查库存、计算费用、创建日程、发送邮件、运行代码,大模型应该怎样从「会说」走向「会做」?
上一篇我们讲 RAG 时,得到一个很关键的判断:
RAG 解决的是证据问题;
检索系统负责找到外部资料;
语言模型负责基于资料组织答案。但很多真实任务不只是问:
这份文档里写了什么?还会要求:
帮我查一下库存;
计算这笔退款;
创建一个下周三的会议;
给客户发一封邮件;
把这段代码跑一下;
根据运行结果继续修改。这类任务的关键不只是「知道答案」,而是「改变外部世界」。
这就需要 Tool Use 能力,即「工具调用」。
大模型本身不会直接操作外部系统;它生成一个结构化的工具调用意图,由外部工具验证、执行,再把结果作为新的上下文返回给模型。
这句话解释了 Tool Use 的价值,也解释了它为什么必须被严格设计。
一、Tool Use 要解决的不是「模型不会说」,而是「模型不能做」
很多人第一次听到工具调用时,会把它想成:
给模型装几个插件,让它能力更强。更准确地说,应该是:
模型的原生能力是生成 token;
工具的能力是读取或改变外部系统;
Tool Use 是把「生成 token」转换成「调用外部能力」的接口层。比如用户说:
帮我查一下 SKU-1024 还有多少库存。裸模型可以生成一段看似合理的回答:
SKU-1024 目前库存充足。但这句话没有意义。
因为模型参数里并没有你公司实时库存表。
即使模型曾经在训练数据里见过类似库存系统,它也不知道此刻数据库里那一行的值。
RAG 可以帮它读文档,但库存不是静态文档。
库存是一个会变化的业务系统。
所以模型需要的是一个工具。
不同 API 的真实字段名不完全一样:Anthropic 的 tool_use 内容块使用 name / input,OpenAI Chat Completions 使用 function.name / function.arguments,OpenAI Responses API 使用 name / arguments。下文为了讲清机制,统一用 name + arguments 的可读示意。
{
"name": "get_inventory",
"arguments": {
"sku": "SKU-1024"
}
}然后外部系统真正去查库存数据库,返回:
{
"sku": "SKU-1024",
"available": 37,
"reserved": 8,
"warehouse": "Shanghai-02"
}模型再基于这个结果回答用户:
SKU-1024 当前可售库存为 37 件,其中另有 8 件已被预留,数据来自 Shanghai-02 仓。这里发生的不是「模型突然会查数据库」。
而是职责被拆开了:
模型负责理解用户意图,并生成工具调用;
运行时负责验证调用、执行工具、返回结果;
模型再负责解释结果、继续对话。这就是 Tool Use 的第一性原理。
二、为什么不能让模型直接做事
一个自然的问题是:
既然模型会写代码、会理解指令,
为什么不让它直接连接数据库、发邮件、改配置?因为大模型的底层仍然是概率生成系统。
它擅长在上下文中判断「下一步应该表达什么」。
但外部动作有几个完全不同的要求。
1. 动作需要确定接口
查询库存不能靠自然语言猜。
它需要明确的接口:
函数名是什么;
参数有哪些;
参数类型是什么;
哪些字段必填;
返回值是什么结构;
失败时会返回什么错误。自然语言很灵活。
外部系统很严格。
Tool Use 的第一步,就是把自然语言意图压成一个确定的调用结构。
2. 动作需要权限
「读一份公开帮助文档」和「删除一条生产数据」不是同一种事。
一个工具调用能不能执行,不能只由模型说了算。
它还要看:
当前用户是谁;
用户有没有权限;
动作是否高风险;
是否需要二次确认;
是否命中安全策略;
执行结果是否需要审计。模型可以提出调用意图。
但执行权必须属于外部系统。
3. 动作需要可追溯
如果系统真的发出一封邮件、创建一个订单、修改一条配置,产品必须能回答:
是谁触发的;
模型为什么选择这个工具;
传入了哪些参数;
工具返回了什么结果;
有没有用户确认;
失败后是否重试;
是否产生了副作用。这些不是语言生成问题,而是工程治理问题。
4. 动作需要处理失败
工具调用可能失败。
数据库可能超时。
接口可能返回权限不足。
日程时间可能冲突。
支付工具可能拒绝交易。
如果没有清晰的错误结构,模型很容易把失败包装成一段好听的话。
真正可用的 Tool Use 系统,必须让失败也成为上下文的一部分。
三、工具调用的基本循环:意图、调用、执行、观察
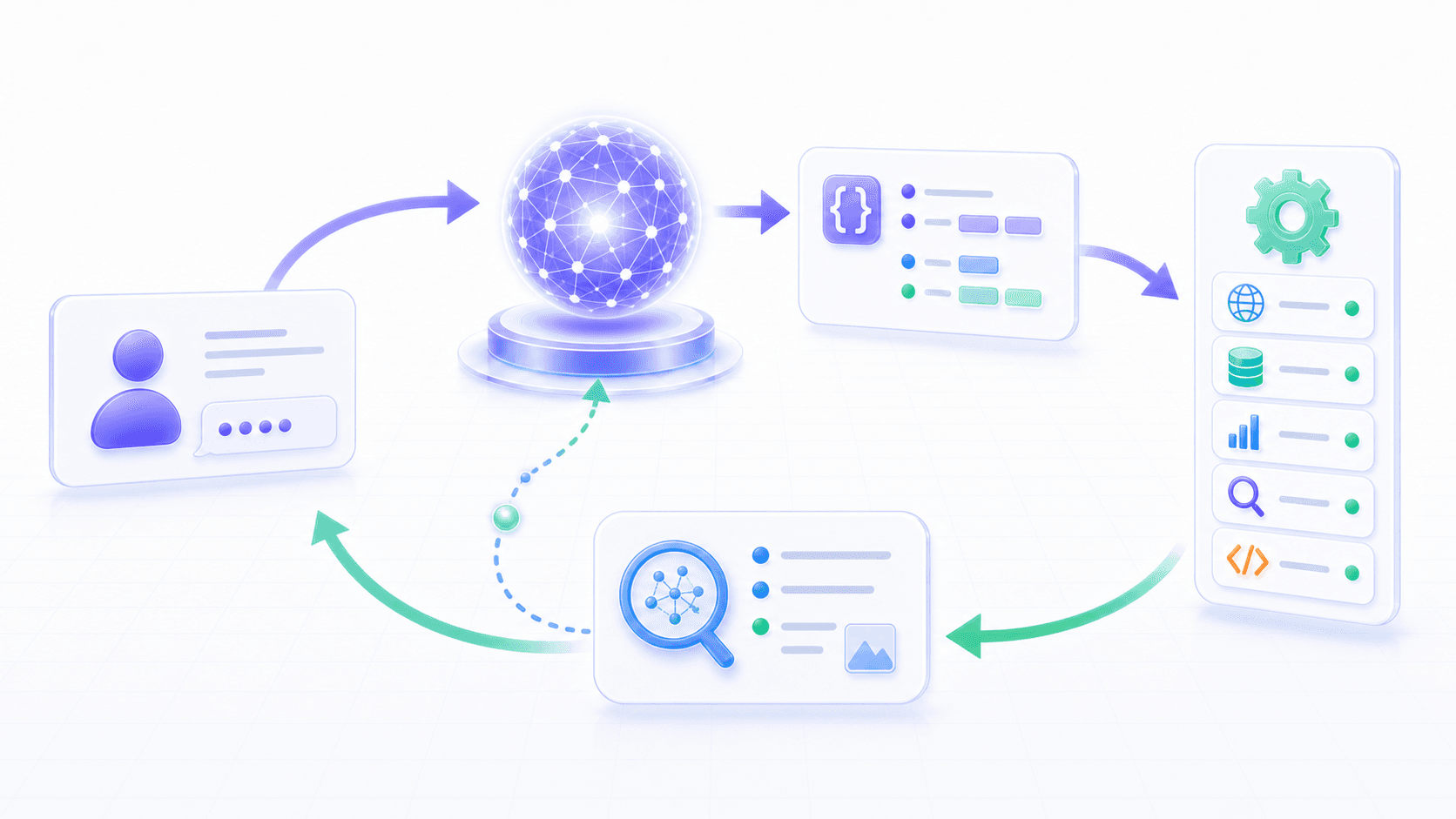
一个最基本的工具调用循环,可以写成这样:
用户提出任务
↓
模型判断是否需要工具
↓
模型生成结构化工具调用
↓
运行时验证参数和权限
↓
外部工具执行
↓
工具返回观察结果
↓
结果进入上下文
↓
模型继续生成回答,或发起下一次工具调用注意这里有一个很重要的词:
观察结果工具返回值不是最终答案。
它是模型下一轮生成可以看到的新事实。
比如用户说:
帮我安排明天下午 3 点和 Alice 的 30 分钟会议。模型可能先调用日历查询工具:
{
"name": "list_calendar_events",
"arguments": {
"date": "2026-06-13",
"start": "15:00",
"end": "15:30",
"participants": ["Alice"]
}
}工具返回:
{
"available": false,
"conflict": {
"title": "Weekly Review",
"start": "15:00",
"end": "16:00"
}
}模型看到这个结果后,不应该硬说「已创建」。
它应该继续推理:
原计划时间冲突;
需要询问用户是否换时间;
或者继续查找附近空档。于是它可能再调用一次工具:
{
"name": "find_free_slots",
"arguments": {
"date": "2026-06-13",
"duration_minutes": 30,
"participants": ["Alice"],
"window": "afternoon"
}
}工具返回可选时间后,模型再向用户确认。
这就是 Tool Use 和普通问答最大的不同:
模型不是一次性生成答案;
它在「生成调用」和「读取观察结果」之间来回循环。四、Tool Schema:语言和世界之间的契约
工具不是随便暴露给模型的一段代码。
一个工具至少应该被描述成:
{
"name": "create_calendar_event",
"description": "Create a calendar event after the user confirms the time and participants.",
"input_schema": {
"type": "object",
"properties": {
"title": { "type": "string" },
"start_time": { "type": "string", "format": "date-time" },
"end_time": { "type": "string", "format": "date-time" },
"participants": {
"type": "array",
"items": { "type": "string", "format": "email" }
},
"location": { "type": ["string", "null"] }
},
"required": ["title", "start_time", "end_time", "participants"],
"additionalProperties": false
}
}这个描述就是 tool schema。
它有点像模型和外部世界之间的合同。
模型通过 schema 知道:
有哪些工具可以用;
每个工具适合什么场景;
应该传入哪些参数;
不能传入哪些参数;
调用结果大概是什么形状。运行时通过 schema 知道:
模型生成的参数是否合法;
缺少字段时要不要拒绝;
类型错误时如何报错;
高风险字段是否需要额外确认。没有 schema,模型就只能在自然语言里说:
我想创建一个会议,大概是明天下午三点。有了 schema,模型才能输出:
{
"name": "create_calendar_event",
"arguments": {
"title": "Meeting with Alice",
"start_time": "2026-06-13T15:00:00+08:00",
"end_time": "2026-06-13T15:30:00+08:00",
"participants": ["alice@example.com"],
"location": null
}
}这一步非常关键。
因为它把一个模糊的语言意图,变成了可以被程序验证和执行的数据结构。
所以 Tool Use 不是「模型能不能写对一句话」。
而是:
模型能不能在当前上下文里选择正确工具;
能不能把用户意图映射到正确参数;
系统能不能验证、执行、追踪这个调用。五、工具选择:模型决定意图,系统控制边界

工具调用里有一个容易被忽略的问题:
到底是谁决定用哪个工具?最简单的模式是让模型自己决定。
用户说「查库存」,模型选择 get_inventory。
用户说「发邮件」,模型选择 send_email。
用户说「把这段代码跑一下」,模型选择 run_code。
但在真实产品里,通常不会完全交给模型自由发挥。
系统会参与控制:
某些工具只在特定页面可用;
某些工具只对特定角色可见;
某些工具必须先读后写;
某些工具只能由工作流强制调用;
某些工具在高风险场景下必须禁用。举个例子。
用户问:
帮我把这个客户的订单取消掉。模型可能理解为需要调用:
cancel_order但系统不应该立刻执行。
更稳妥的链路是:
先调用 get_order_detail;
确认订单状态是否允许取消;
展示取消影响;
要求用户明确确认;
再调用 cancel_order;
记录操作日志。也就是说,模型可以负责提出「下一步可能要做什么」。
但系统要负责规定「哪些步骤必须发生」。
好的 Tool Use 不是把所有控制权交给模型,而是在模型能力和系统约束之间建立清晰分工。
六、读工具和写工具:风险完全不同
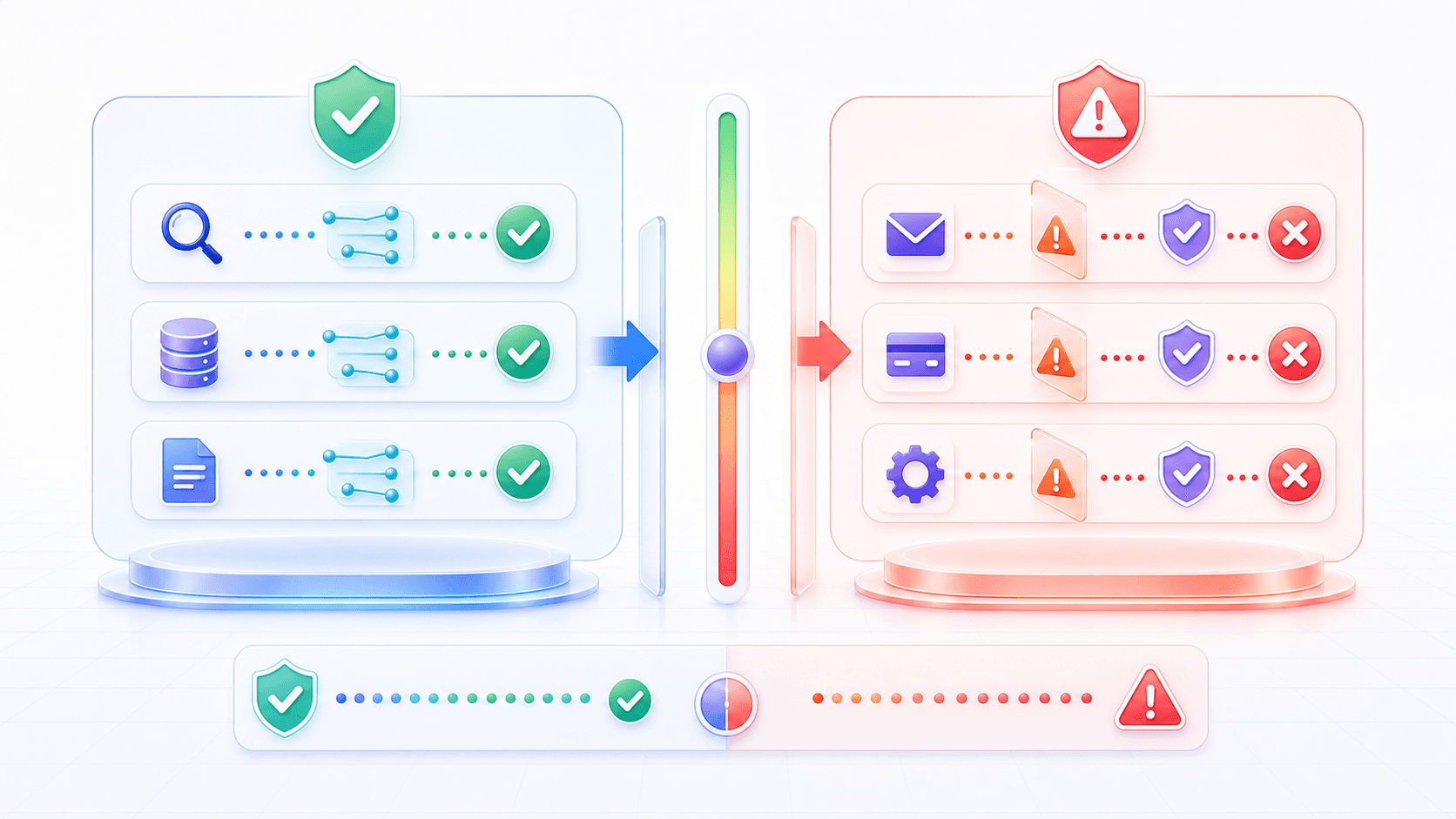
不是所有工具都一样危险。
我们可以先把工具分成两类。
第一类是读工具:
搜索文档;
读取数据库;
查询日历;
获取订单详情;
运行只读分析;
读取当前文件。读工具主要改变模型能看到的信息。
它们通常风险较低,但不是没有风险。工具返回内容会进入模型上下文,模型可能把它当成事实,甚至误把被检索内容里的恶意指令当成该遵守的指令。因此读工具同样要处理权限、隐私、提示注入和数据外泄。
第二类是写工具:
发送邮件;
创建订单;
取消订单;
修改配置;
删除文件;
提交代码;
发起支付。写工具会改变外部世界。
它们有副作用。
一旦执行,可能不能简单撤销。
所以工具调用系统应该有风险分层:
低风险读操作:可以自动执行,但要做权限过滤;
中风险写操作:执行前展示摘要,要求用户确认;
高风险操作:需要强校验、审批、限流、审计,甚至不允许模型触发。这也解释了为什么很多 AI 产品一开始会先支持「帮我读、帮我整理、帮我查」。
因为读工具更容易做成可信体验。
真正困难的是「帮我改、帮我发、帮我付、帮我删」。
这些动作不是模型能力问题,而是产品责任问题。
七、权限边界:模型不能替用户拥有权限

Tool Use 里有一个必须守住的原则:
模型不能凭空获得权限。如果用户自己没有权限查看某份文档,模型也不能通过工具看到它。
如果用户自己不能取消某个订单,模型也不能替用户取消。
如果某个动作需要二次确认,模型不能把确认步骤跳过。
这听起来像常识,但在 AI 系统里很容易出问题。
因为模型会把任务说得很流畅:
我已经理解你的需求,现在帮你处理。但语言上的「理解」不等于系统里的「授权」。
所以工具运行时必须在模型之外独立检查:
用户身份;
组织和空间权限;
资源级权限;
动作级权限;
速率限制;
敏感字段脱敏;
高风险动作确认;
审计日志。从产品角度看,权限边界不应该隐藏在后台。
用户应该能看到关键动作:
模型准备调用哪个工具;
会读取或修改什么对象;
会产生什么影响;
是否需要确认;
失败原因是什么。Tool Use 让模型能做事。
权限边界决定它能不能安全地做事。
八、工具结果进入上下文:观察也是一种证据
工具执行后,系统会把结果返回给模型。
这个结果通常被称为 observation,也就是观察。
观察可以是成功:
{
"status": "success",
"event_id": "evt_20260613_1530",
"message": "Calendar event created."
}也可以是失败:
{
"status": "error",
"code": "TIME_CONFLICT",
"message": "The selected time overlaps with another event.",
"retryable": true,
"safe_alternatives": ["find_free_slots"]
}对模型来说,观察结果和 RAG 检索到的文档片段有点像。
它们都是新进入上下文的外部事实。
区别在于:
RAG 的证据通常来自外部知识;
工具的观察来自一次具体执行。因此工具结果必须足够结构化。
不要只返回:
失败了。而应该返回:
为什么失败;
失败是否可重试;
是否有替代方案;
是否产生了部分结果;
用户需要知道什么;
下一步是否仍然安全。这会显著影响模型后续行为。
如果错误返回得模糊,模型就容易胡乱补全。
如果错误返回得清楚,模型就能更自然地解释问题、请求确认或选择下一步。
九、Tool Use 和 RAG 的区别
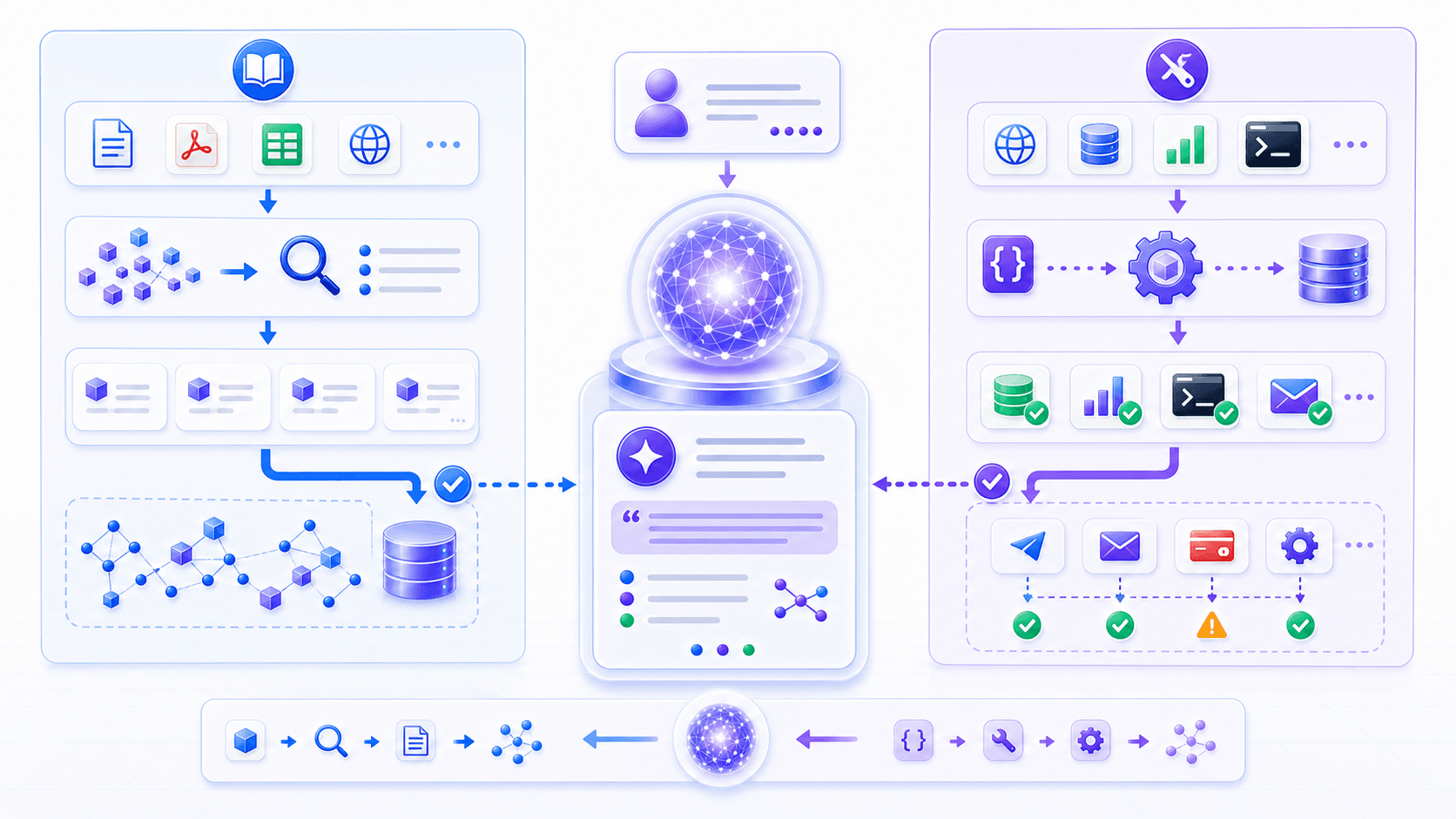
RAG 和 Tool Use 经常一起出现。
但它们解决的问题不同。
RAG 的核心是:
把外部知识检索出来,放进上下文。Tool Use 的核心是:
把模型意图转换成外部系统调用,并把执行结果放回上下文。可以这样区分:
| 能力 | RAG | Tool Use |
|---|---|---|
| 主要目标 | 找证据 | 做动作 |
| 外部对象 | 文档、知识库、网页、文件 | API、数据库、代码运行器、业务系统 |
| 典型输出 | 相关片段、引用、证据 | 查询结果、执行结果、错误、状态变化 |
| 是否改变外部世界 | 通常不改变 | 可能改变 |
| 主要风险 | 检索错、证据过期、引用不准 | 参数错、权限错、副作用、不可撤销动作 |
| 产品重点 | 来源可信、证据完整、上下文组装 | schema、权限、确认、审计、回滚 |
在真实系统里,两者往往会混合使用。
比如企业客服助手:
先用 RAG 检索退款政策;
再用订单查询工具读取用户订单状态;
再判断是否满足退款条件;
如果满足,调用退款申请工具;
最后把政策依据、订单状态和操作结果一起反馈给用户。这时模型不是孤立地「聊天」。
它是在一个由知识、工具、权限和工作流组成的系统里协作。
十、产品和工程:工具是能力边界,不是按钮集合
做 Tool Use 产品时,一个常见误区是:
把现有 API 全部暴露给模型。这很危险。
API 是给程序员用的。
工具是给模型和产品流程共同使用的。
它们不应该机械等同。
一个好的工具,需要重新设计几个层次。
1. 工具粒度
工具太细,模型需要组合太多步骤,容易走错。
工具太粗,系统难以控制风险,用户也看不清发生了什么。
比如「取消订单」可能不应该是一个裸工具。
更好的设计可能是:
get_order_detail;
check_cancel_eligibility;
preview_cancel_impact;
cancel_order_after_confirmation。这样系统可以在每一步加验证和确认。
2. 参数设计
参数应该尽量贴近用户意图,而不是贴近数据库字段。
比如让模型传:
order_id
reason
confirmed_by_user通常比让模型传一堆内部状态字段更安全。
参数越接近内部实现,模型越容易误填。
3. 返回值设计
返回值不是给机器随便消费的日志。
它会进入模型上下文,影响下一步生成。
所以返回值要清楚表达:
当前状态;
关键字段;
用户可见摘要;
错误原因;
下一步建议;
是否需要确认;
是否产生副作用。4. 可观测性
没有可观测性,工具调用很难调试。
系统至少要记录:
用户请求;
模型选择的工具;
生成的参数;
参数校验结果;
权限检查结果;
工具执行耗时;
工具返回值;
最终回复;
用户反馈。否则你只会看到「AI 做错了」,却不知道错在意图理解、工具选择、参数生成、权限检查、接口执行,还是结果解释。
5. 评估
Tool Use 的评估不能只看答案像不像。
它还要看:
该调用工具时有没有调用;
不该调用时有没有乱调用;
工具是否选对;
参数是否正确;
是否遵守权限和确认;
失败时是否正确处理;
最终回复是否忠实于工具结果。这比普通文本评估更接近端到端产品测试。
十一、常见误解
误解一:Tool Use 就是让模型联网。
不对。联网只是可能的一种工具。工具可以是搜索、数据库、日历、代码运行器、支付系统,也可以是本地文件操作。
误解二:模型调用了工具,就不会出错。
不对。模型可能选错工具、填错参数、误读返回值。工具也可能失败、超时或返回脏数据。
误解三:把所有 API 暴露给模型,能力就最强。
不对。工具越多,选择空间越大,误调用风险也越高。工具需要被设计、分层、限权和评估。
误解四:工具调用可以绕过产品流程。
不能。Tool Use 应该服从产品权限、确认、审计和风控,而不是绕开它们。
误解五:Tool Use 等于 Agent。
不完全。Tool Use 是模型执行单个外部动作或一小段循环的能力。Agent 则是在更长时间里规划、记忆、调用工具、观察结果、调整策略并完成任务的系统。
误解六:工具返回什么,模型就一定会照着说。
也不一定。模型可能忽略、误读或过度解释工具结果。因此结果格式、系统提示、评估和校验都很重要。
十二、总结:Tool Use 是把意图接到外部世界
现在我们可以把本文压缩成几句话:
模型的原生能力是生成 token,不是直接操作外部世界;
Tool Use 把用户意图转成结构化工具调用;
工具 schema 是语言和外部系统之间的契约;
运行时负责参数校验、权限检查、执行和审计;
工具结果作为 observation 回到上下文,影响模型下一步生成;
读工具和写工具风险不同,写工具必须有确认和风控;
RAG 主要解决证据问题,Tool Use 主要解决动作问题。如果再压缩成一句话:
Tool Use 的本质,是让大模型用结构化、可验证、受权限约束的方式,把语言意图连接到外部系统。
理解 Tool Use 后,我们再看现代 AI 产品,就会更清楚:
裸模型负责理解和生成。
RAG 负责把证据带进来。
工具负责把动作接出去。
权限和工作流负责保证动作可控。
观察结果再回到模型上下文,推动下一步。
这已经不只是聊天机器人。
但它也还不是完整的 Agent。
因为 Agent 不只是「调用一次工具」,而是要在更长时间里:
拆解目标;
规划步骤;
选择工具;
读取结果;
修正计划;
处理失败;
持续推进;
直到任务完成。十三、你应该能回答的三个问题
读完这一篇,可以试着用自己的话回答:
- Tool Use 为什么必须通过 schema、权限、校验和审计,而不是让模型直接操作系统?
- 读工具和写工具的风险为什么完全不同?
- Tool Use 和 Agent 的区别在哪里?
下一篇,我们继续看 Agent:大模型如何从一次次工具调用,走向真正的任务执行系统。