12:大模型工程:KV Cache、推理成本与部署系统
这是「用第一性原理理解大模型」系列的第 12 篇。第 11 篇:Agent 解释了大模型如何从聊天机器人变成任务执行系统。现在我们带入工程视角:如果每个回答都要一个 token 一个 token 地生成,那么成本、延迟、KV Cache、并发和部署架构会对 AI 产品产生哪些影响?它们为什么会成为产品能否规模化的关键?
前面几篇文章,我们已经把大模型从「会说」一路推到了「会做」:
RAG 让模型基于外部证据回答;
Tool Use 让模型把语言意图变成外部动作;
Agent 让模型围绕目标持续推进任务。但越往产品层走,一个问题越明显:
模型能力不等于产品能力。一个模型在 demo 里能回答,不代表它能在真实业务里稳定服务十万用户。
一个 Agent 在单次任务里能跑通,不代表它能承受并发、长上下文、工具延迟、失败重试和成本约束。
从第一性原理看,大模型工程要解决的不是「模型有没有智能」。
而是:
如何把一个逐 token 生成的概率模型,
变成低延迟、可并发、可观测、可控成本的在线服务。这篇文章就从这条线展开。
一、工程要解决的问题不是「模型不会答」,而是「模型要怎么稳定地答」

在本地或网页里试一个大模型时,我们通常关注的是:
它答得对不对;
它聪不聪明;
它会不会推理;
它能不能调用工具。但当它进入产品系统后,问题会变成:
首 token 多久出来;
每秒能生成多少 token;
高峰期能同时服务多少用户;
一次对话最长能放多少上下文;
工具调用失败怎么重试;
一次任务平均花多少钱;
什么时候该降级到便宜模型;
哪些请求应该排队、拒绝或拆分;
用户看见失败时,系统能不能解释原因。这听起来像「工程细节」,但却正是大模型产品的关键。
原因很简单:大模型产品的核心体验,直接由推理系统决定。
用户不会只感知模型能力。
用户还会感知:
等待时间;
输出速度;
回答稳定性;
长对话是否丢上下文;
工具结果是否及时;
失败后是否能恢复;
费用是否可接受。所以,大模型工程不是把模型「部署上去」这么简单。
它是在模型能力和产品体验之间,建立一套运行系统。
二、问题的起点:自回归生成

前面讲推理与生成时,我们已经看过大模型回答问题的基本循环:
已有上下文
↓
计算下一个 token 的概率分布
↓
选择一个 token
↓
把这个 token 追加到上下文
↓
继续预测下一个 token这就是所有工程问题的起点。
大模型不是一次性把完整答案吐出来。
它每生成一个输出 token,都要基于当前上下文,再做一次模型前向计算。
所以一次回答的耗时,大致可以拆成两段:
总耗时 ≈ 读取并处理输入上下文的时间
+ 一个 token 一个 token 生成输出的时间更常见的工程说法是:
Prefill 阶段:处理已有 prompt / context;
Decode 阶段:逐 token 生成新内容。这两个阶段的性质完全不同。
Prefill 更像是:
把用户问题、系统提示词、历史对话、RAG 资料、工具结果一起读进来。Decode 更像是:
在读完这些内容后,一步一步写出回答。这解释了为什么大模型产品常见两个体验指标:
TTFT(Time To First Token):第一个 token 多久出现;
Tokens per second:后续输出速度有多快。用户体感也正好对应这两件事:
先等多久;
开始输出后流得快不快。如果 prompt 很长,TTFT 往往会变慢。
如果回答很长,decode 时间会变长。
如果很多用户同时请求,调度、排队和显存压力都会出现。
所以从第一性原理看:
大模型推理不是一次函数调用;
它是一次上下文处理,加上一段强顺序性的 token 生成循环。理解这一点,后面的 KV Cache、成本和部署架构才会变得自然。
这一节先建立工程直觉。如果你想把「搬参数」和「做计算」进一步写成公式,并理解为什么 output token 往往比 input token 更贵、batch 的甜蜜点为什么会从硬件常数里推出来,可以继续读《LLM 定价的数学原理》系列的 01:工作原理、推理速度及推理成本 和 02:把推理过程写成方程。
三、Prefill 与 Decode:输入长和输出长贵在不同地方

我们可以把一次请求想成餐厅出餐。
Prefill 是后厨先读完整张订单:
客人是谁;
点了什么;
有没有忌口;
历史备注是什么;
有没有优惠券;
库存够不够。Decode 是厨师开始一道一道出菜。
读订单可以一次读很多信息。
但出菜有顺序,第一道没做完,后面的动作会受影响。
大模型生成也是类似的。
1. Prefill 主要受输入上下文影响
输入上下文越长,模型需要处理的 token 越多。
这些 token 可能来自:
系统提示词;
用户问题;
历史对话;
RAG 检索片段;
工具返回结果;
开发者塞进去的格式说明;
隐含的安全策略。这就是为什么很多 AI 产品会在长对话后变慢。
用户以为自己只是问了一个短问题。
但系统实际喂给模型的可能是:
短问题 + 很长的历史上下文 + 多段检索资料 + 工具结果 + 系统约束。模型看到的是 token,不是用户主观感觉里的「这一句话」。
2. Decode 主要受输出长度影响
输出越长,需要生成的 token 越多。
每个输出 token 都依赖前面已经生成的 token。
所以 decode 阶段天然很难完全并行。
这就是为什么:
让模型写一篇长文,比让模型回答一句话贵很多;
让 Agent 做多步任务,比让模型完成单轮回答贵很多;
让模型输出结构化长 JSON,可能比摘要短回答更慢。不是因为模型「懒」。
而是生成路径本来就是逐 token 推进。
3. 输入 token 和输出 token 的产品含义不同
输入 token 决定模型需要读多少。
输出 token 决定模型需要写多久。
在产品设计里,这会变成几个很具体的问题:
历史对话要保留多少;
RAG 资料要塞几段;
工具返回结果要不要裁剪;
是否需要让模型输出完整长文;
能不能先输出摘要,再按需展开;
是否可以把任务拆成多个短步骤。所以,「上下文越多越好」「输出越完整越好」在工程上都不成立。
上下文和输出都是能力,也是成本。
四、KV Cache:用显存换速度的关键机制
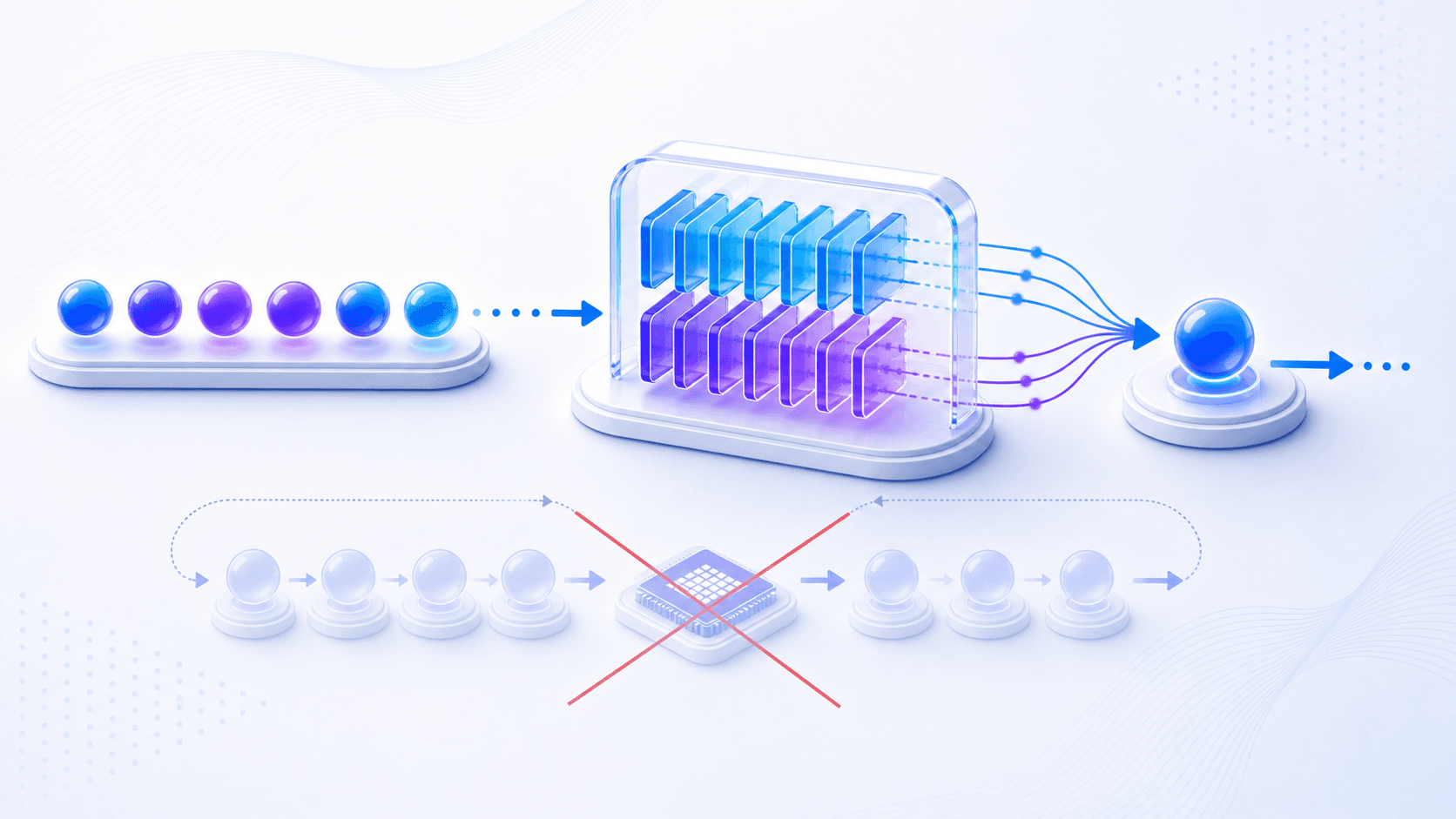
现在进入这篇文章最关键的概念:KV Cache。
在 Transformer 里,Attention 会让当前 token 参考前面的 token。
每一层都会把 token 表示投影成几类向量,其中和注意力查找最相关的是:
Query:当前 token 想找什么;
Key:历史 token 提供什么索引;
Value:历史 token 携带什么内容。如果没有缓存,模型每生成一个新 token,都要重新为整段历史上下文计算 Key 和 Value。
这会非常浪费。
因为历史 token 没变。
变的只是最后新生成的那个 token。
于是工程上会做一件很自然的事:
把过去 token 在每一层产生的 Key / Value 存下来;
生成下一个 token 时,只计算新 token 的部分;
再让新 token 去注意已经缓存的历史 Key / Value。这就是 KV Cache。
它的第一性原理可以这样说:
KV Cache 用显存保存历史 token 的注意力中间结果,
避免每生成一个新 token 都重新计算整段上下文。具体来说,prefill 阶段在处理输入上下文时,就把这段 prompt 在每一层的 Key / Value 算好并缓存下来;decode 阶段每生成一个新 token,只算它自己的部分,再复用缓存里的历史 Key / Value。
这也是大模型推理能跑得起来的关键优化。
如果没有 KV Cache,长对话和长输出会更慢得多。
KV Cache 还能再进一步。
如果很多请求共享同一段开头——比如同一个系统提示词、同一份少样本示例、同一篇长文档——那么这段前缀的 Key / Value 其实每次都一样。
既然一样,就没必要每个请求都重新算一遍。
可以把这段共享前缀的缓存保留下来,给后面的请求复用。这就是 prefix caching(前缀缓存),很多 API 把它包装成 prompt caching 对外计费。
它的产品含义很直接:
稳定不变的内容(系统提示词、规则、长文档)放在 prompt 前面,
重复调用时可以命中缓存,省掉重复的 prefill;
经常变化的内容放在后面,避免让缓存失效。所以同样一段长系统提示词,第一次要老老实实算,后面命中缓存的请求会更快、也更便宜。
但 KV Cache 不是免费午餐。
它带来的代价是显存占用。
五、KV Cache 为什么会成为长上下文和并发的瓶颈
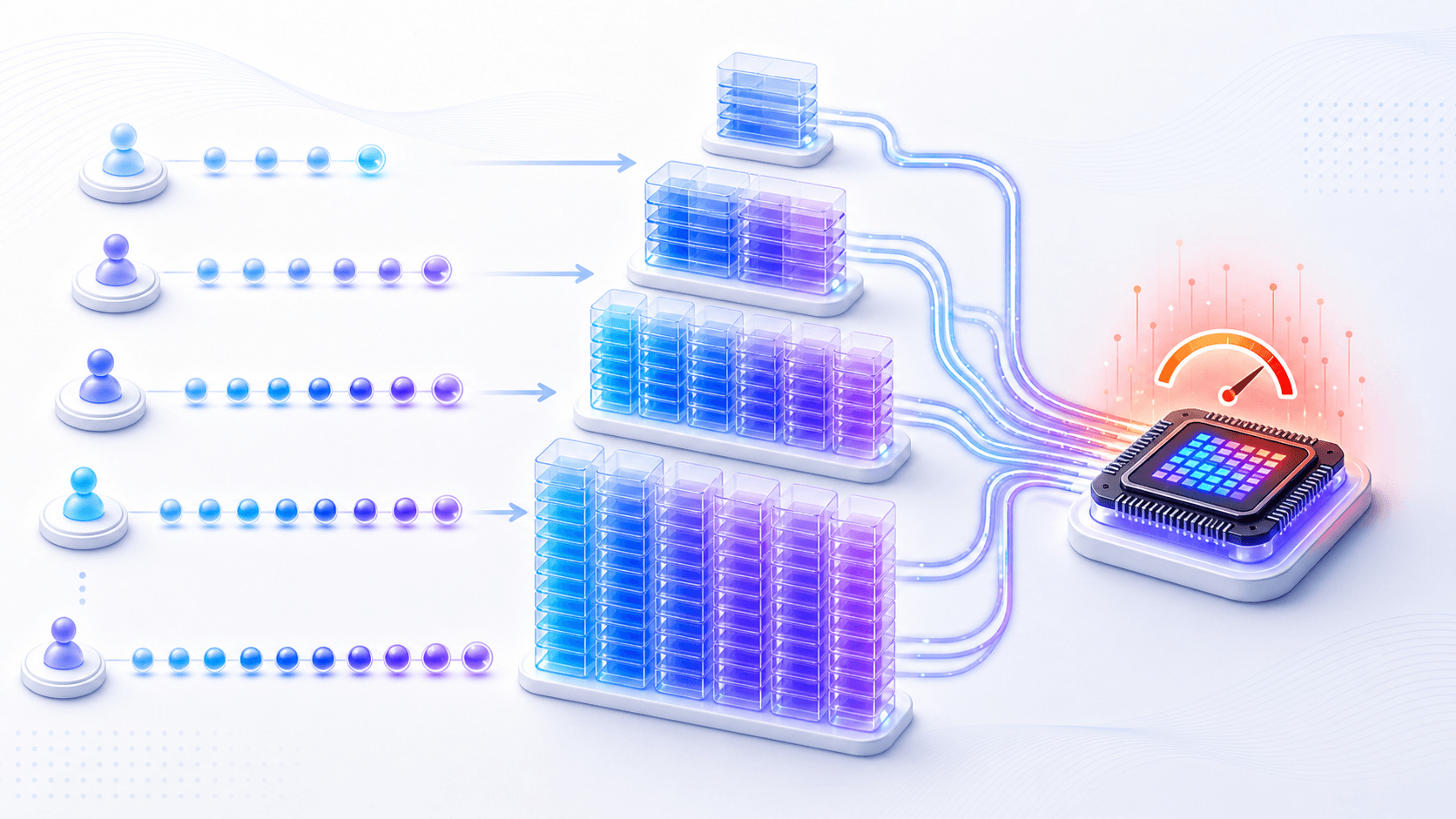
KV Cache 的大小大致和这些因素相关:
KV Cache 大小
≈ 请求数量
× 上下文 token 数
× 模型层数
× 每层需要保存的 Key / Value 维度
× 每个数值占用的字节数不用记公式。
只要记住一句话:
上下文越长,并发越高,KV Cache 吃掉的显存越多。这解释了很多产品现象。
1. 长上下文不是只多花一点输入 token
长上下文当然会增加 prefill 计算。
但更重要的是,它会让 KV Cache 变大。
如果一个用户带着很长上下文开始生成,系统就需要为这段上下文保留一份缓存。
如果同时有很多用户都在长上下文生成,显存压力会迅速上升。
所以长上下文产品不能只问:
模型最大支持多少 token?还要问:
在这个上下文长度下,我们能承受多少并发?
P95 延迟是多少?
单位任务成本是多少?
失败率会不会上升?2. 多轮对话会不断积累上下文债务
多轮对话看起来很自然。
但对推理系统来说,每一轮都可能在累积:
用户历史;
模型历史;
RAG 资料;
工具结果;
中间推理草稿;
系统约束。如果系统不做上下文管理,最终会出现两个问题:
越来越慢;
越来越贵。而且上下文越长,模型越不一定能稳定关注真正重要的部分。
所以大模型工程里,「上下文管理」不是 prompt 小技巧。
它是成本、延迟和质量的共同控制面。
3. Agent 会放大 KV Cache 问题
Agent 不只是一次问答。
它可能会:
规划;
调用工具;
读观察结果;
更新状态;
继续调用工具;
生成中间结论;
最后交付结果。如果每一步都把全部历史塞回模型,成本会很快失控。
所以成熟的 Agent 系统通常需要把「对话上下文」和「任务状态」分开。
不是所有历史都应该留在 prompt 里。
有些信息应该压缩。
有些信息应该结构化存储。
有些信息应该按需检索。
有些信息应该直接丢弃。
这就是 KV Cache 和上下文工程之间的关系。
如果你想更深入地理解 KV Cache 为什么会成为长上下文定价和架构优化的核心,可以读《LLM 定价的数学原理》04:拆开 KV cache。那一篇会把每个 token 的 KV 字节数、GQA / MLA / 跨层共享,以及如何从长上下文阶梯定价反推出内部架构讲得更细。
六、推理成本:贵的不只是模型调用本身
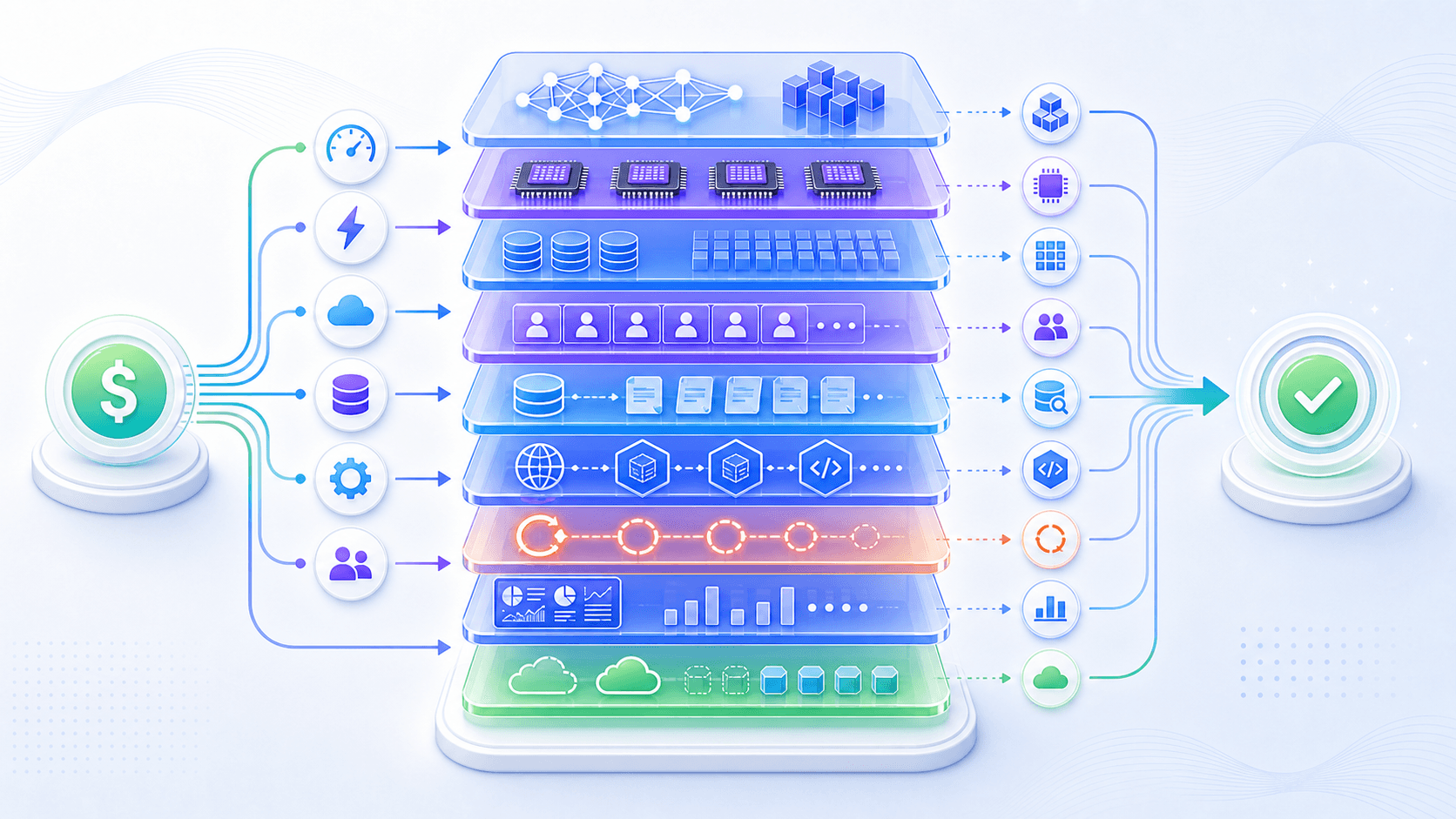
很多人理解大模型成本时,会先想到 API 价格:
输入 token 多少钱;
输出 token 多少钱。这是一个好入口,但不是完整答案。
从系统角度看,推理成本至少来自几层:
模型权重占用的显存;
prefill 和 decode 需要的计算;
KV Cache 占用的显存和带宽;
批处理和调度带来的等待;
RAG 检索、重排和数据库查询;
工具调用和外部系统延迟;
失败重试和多模型兜底;
日志、监控、评估和安全检查;
为了满足低延迟而预留的冗余容量。这就是为什么「便宜模型」不一定让任务总成本更低。
如果便宜模型经常失败,需要重试三次,或者需要更长 prompt 才能约束住,最终成本可能反而更高。
同样,「强模型」也不一定总是贵。
如果强模型一次解决问题、少走工具、少重试、输出更短,它在某些任务上可能更划算。
更准确的成本单位应该是:
每个成功任务的成本。而不是:
每个 token 的价格。这对 Agent 产品尤其重要。
一个 Agent 任务可能包含:
多次模型调用;
多次 RAG;
多次工具调用;
失败恢复;
人工确认;
最终交付。如果只看单次模型调用价格,就会低估真实成本。
如果只看 token 价格,也会忽略延迟、失败率和用户等待。
七、Batching 与调度:吞吐和延迟永远在拉扯
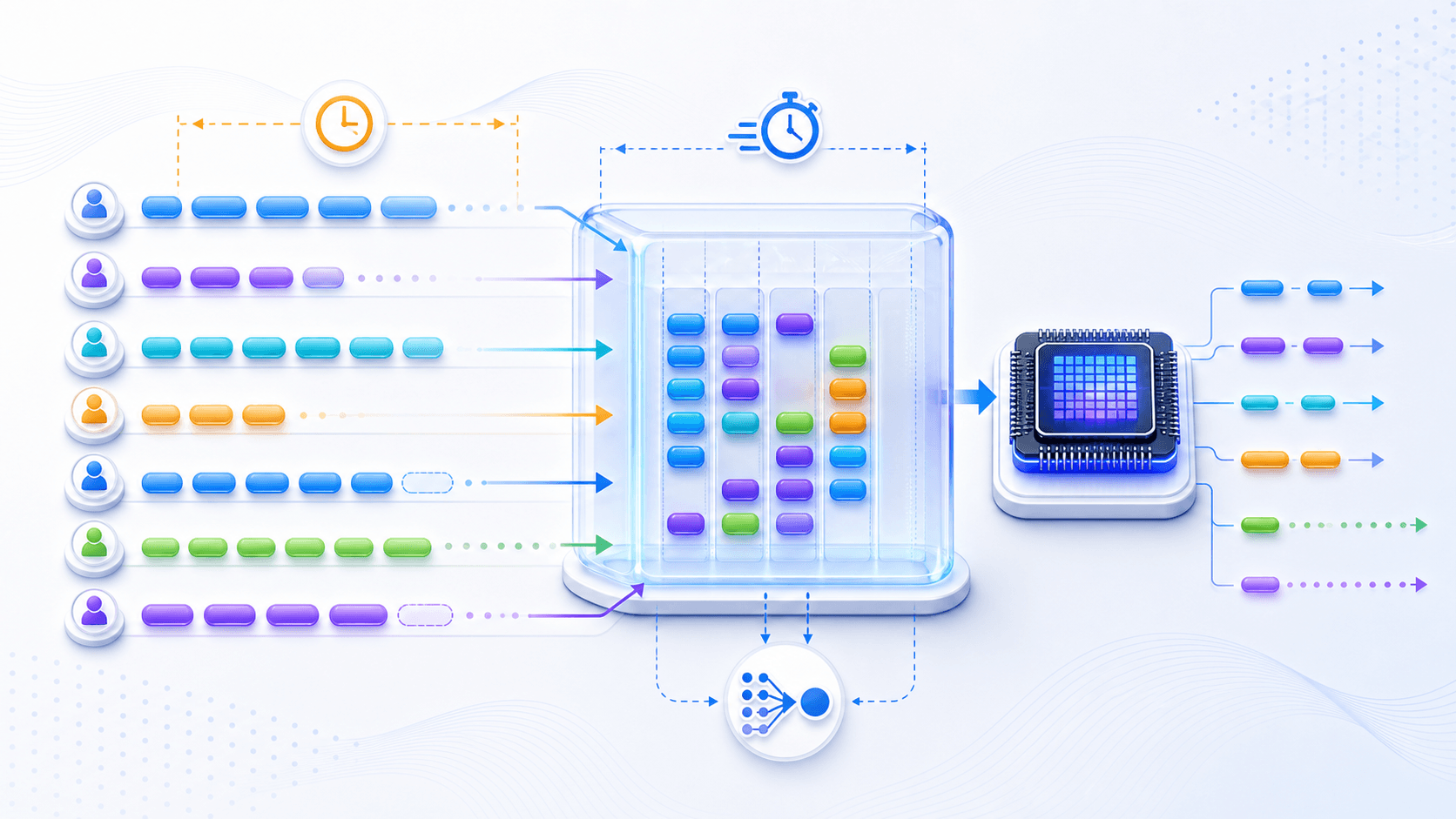
GPU 擅长并行计算。
如果一次只服务一个请求,很多算力会被浪费。
所以推理系统通常会把多个请求合在一起处理,也就是 batching。
直觉上像拼车:
单人专车等待少,但成本高;
拼车利用率高,但可能需要等其他人;
拼得太满,又会影响每个人的到达时间。大模型推理也是这样。
批处理能提高吞吐,让单位 token 成本下降。
但批处理也会带来排队和调度问题。
尤其在 decode 阶段,不同请求的输出长度不同:
有人只要一句话;
有人要一篇文章;
有人中途停止;
有人继续追加工具结果。所以现代推理系统通常不会只做静态 batch,而会做更动态的调度。
比如在老请求持续生成的同时,把新请求插进来,这通常叫连续批处理(continuous batching,也叫 in-flight batching)。
这里的核心不是某个具体技术名词,而是一个永恒权衡:
吞吐越高,单位成本越好;
延迟越低,用户体验越好;
显存越紧,长上下文和并发越难;
调度越复杂,系统可观测性越重要。流式输出也要放在这里理解。
Streaming 会让用户更早看到第一个 token。
它改善体感等待。
但它不会让模型跳过逐 token 生成。
也就是说:
流式输出改善体验;
批处理改善吞吐;
KV Cache 改善重复计算;
调度系统负责在它们之间做权衡。这一节只保留产品工程层面的判断。如果你想看「每 token 成本」如何由可摊销的参数搬运、摊不掉的 KV、算力下界共同构成,可以读 03:从推理耗时到推理成本。如果你还想继续看单卡之外的 GPU 集群、expert / pipeline parallelism、rack、scale-up 与互联如何影响成本下界,可以接着读 05:从单卡到集群。
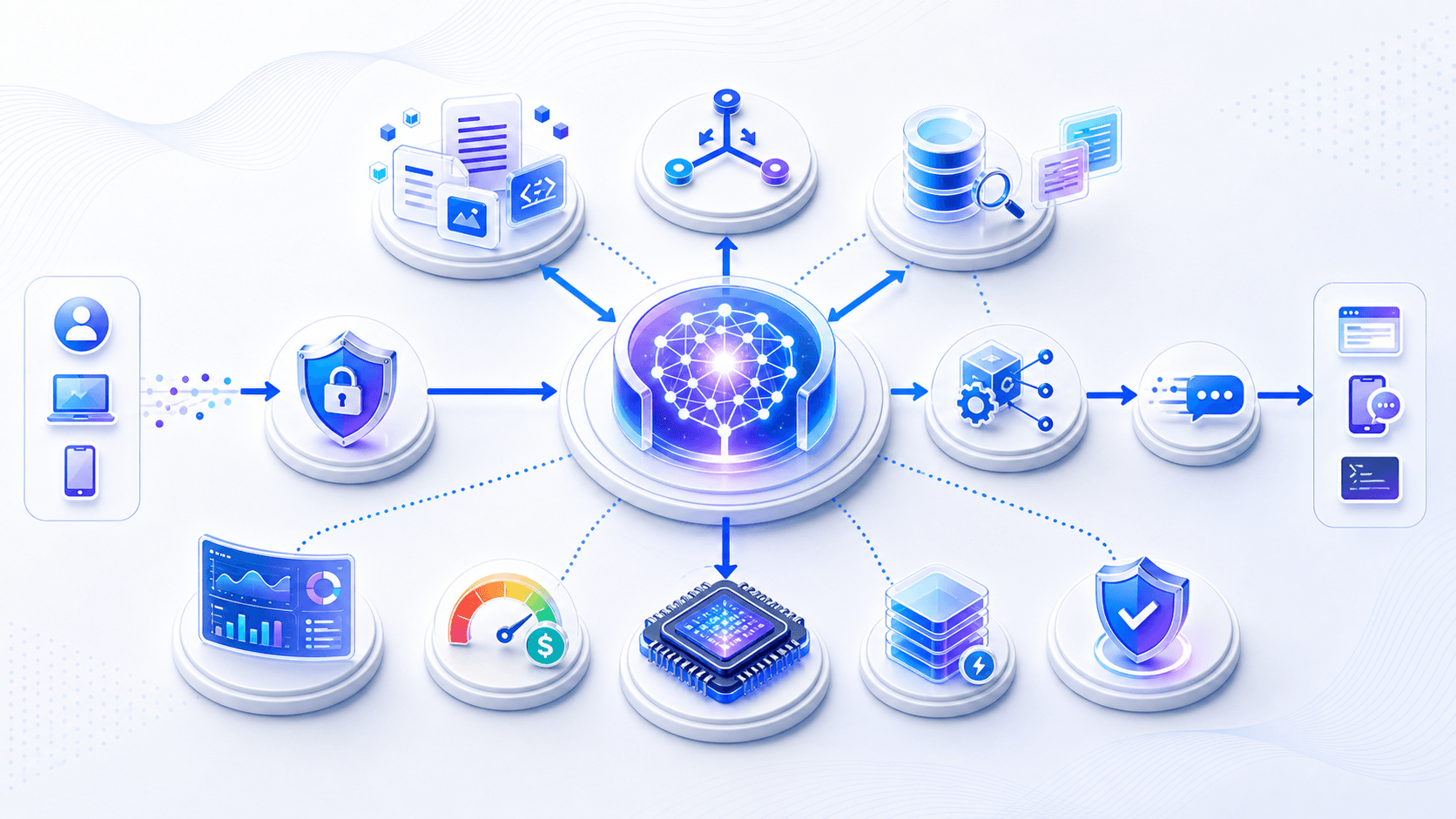
八、部署系统:大模型产品不是「一个模型 + 一个接口」
一个真实的大模型产品,通常不会是:
前端
↓
模型 API
↓
回答更接近:
用户请求
↓
身份、权限、配额检查
↓
任务分类与模型路由
↓
上下文组装
↓
RAG / 工具 / 业务数据读取
↓
推理服务
↓
安全与格式校验
↓
结果流式返回
↓
日志、评估、成本统计这里每一层都会影响最终体验。
1. 网关层决定谁能用、用多少、走哪条路
网关不只是转发请求。
它通常要处理:
认证;
限流;
配额;
模型选择;
灰度;
降级;
审计;
成本归因。同一个用户请求,可能不应该永远打到同一个模型。
简单问题可以用小模型。
高风险问题可以用强模型。
长文写作可以走擅长长输出的模型。
低延迟场景可以走更快模型。
这就是模型路由的产品价值。
2. 上下文组装层决定模型真正看见什么
用户以为自己把一句话发给了模型。
但系统可能还会加上:
系统提示词;
产品规则;
用户画像;
历史摘要;
检索证据;
工具状态;
输出格式;
安全边界。这层决定模型的输入质量,也决定成本。
上下文组装做得差,强模型也会答差。
上下文组装做得好,小模型也可能足够。
3. 推理层决定速度、并发和稳定性
推理层要处理:
prefill;
decode;
KV Cache;
batching;
显存管理;
请求取消;
超时;
失败重试。这是最接近 GPU 和模型运行时的一层。
它决定系统能不能在高峰期活下来。
4. 业务层决定模型能不能产生真实价值
RAG、工具调用、数据库、工作流和审批,不是模型外面的装饰。
它们决定模型输出能不能落到真实任务上。
所以大模型部署系统的核心不是「把模型放到服务器上」。
而是:
把模型放进一套有权限、有上下文、有工具、有监控、有失败处理的产品运行系统。九、可观测性:你不能优化看不见的 token
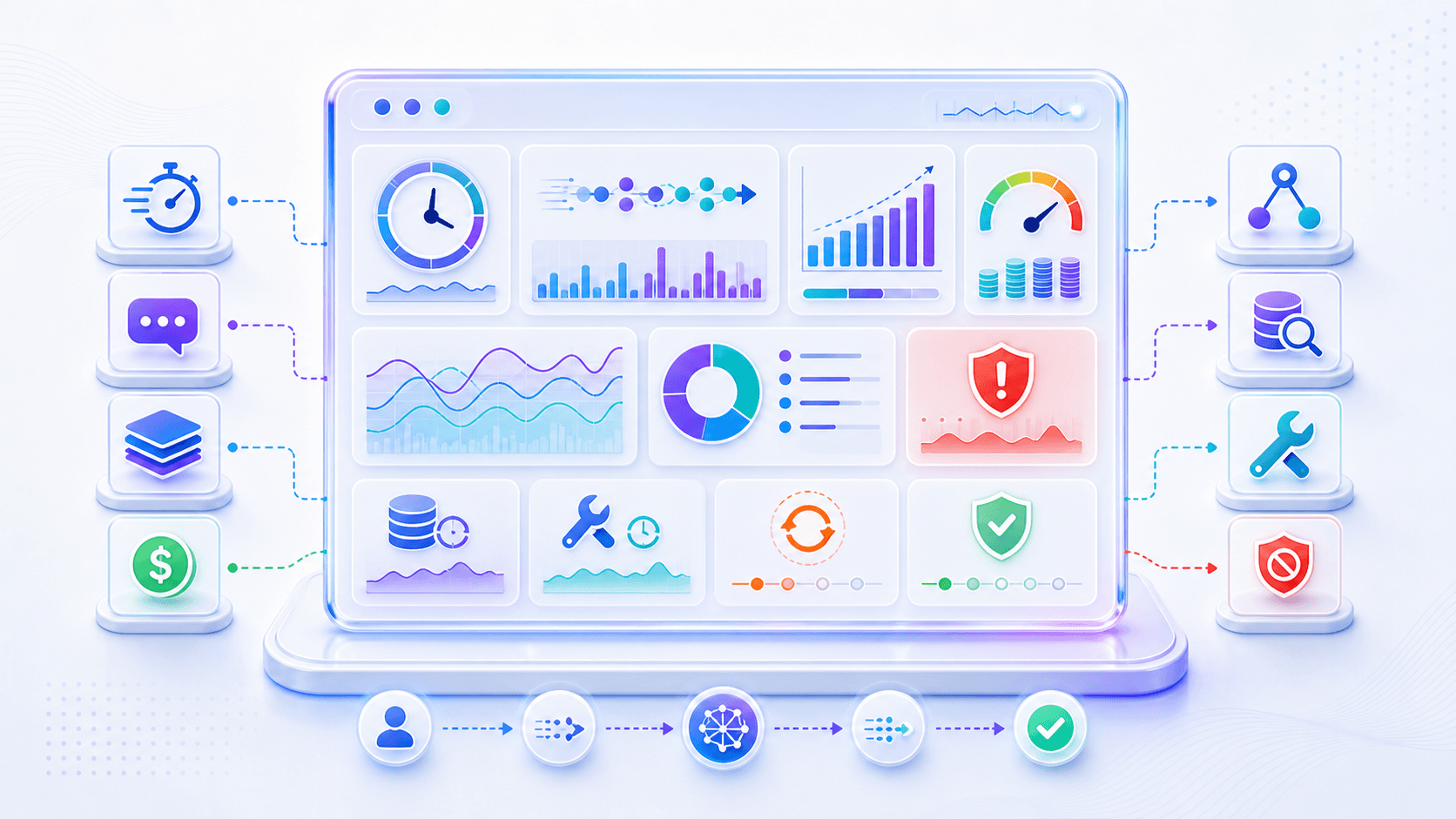
传统软件系统也需要监控。
但大模型系统有一些新的观测对象。
除了普通的接口耗时、错误率、CPU、内存之外,还要看:
输入 token 数;
输出 token 数;
上下文长度分布;
TTFT;
输出 tokens per second;
P50 / P95 / P99 延迟;
每次请求成本;
每个成功任务成本;
模型选择分布;
RAG 检索耗时;
工具调用耗时;
重试次数;
截断次数;
用户取消率;
格式校验失败率;
安全拦截率。这些指标不是为了好看。
它们会直接回答产品问题。
比如:
为什么最近回答变慢?
是 prompt 变长了,还是输出变长了?
是 RAG 慢,还是模型 decode 慢?
是用户请求变复杂,还是调度队列拥堵?
是小模型失败重试太多,还是强模型用得太多?
是 Agent 步数增加,还是工具失败率升高?没有这些指标,团队只能靠感觉调 prompt、换模型、加机器。
那很容易把问题越修越贵。
大模型工程的一条基本原则是:
先把 token、延迟、成本、质量和失败路径看见,
再谈优化。十、可靠性:失败不只来自模型答错
在普通认知里,大模型失败就是:
回答错了;
幻觉了;
没有遵守指令。但在工程系统里,失败类型更多:
上下文超长;
请求超时;
显存不足;
队列过长;
输出被截断;
工具调用失败;
RAG 没检索到证据;
格式校验不通过;
重试导致成本膨胀;
用户中途取消;
外部 API 限流;
模型版本变化导致行为漂移。这就是为什么 Agent 产品尤其需要状态管理。
当一个十步任务在第七步失败时,系统不应该只说:
出错了,请重试。更好的系统应该知道:
已经完成了哪几步;
失败发生在哪个工具;
是否可以安全重试;
重试会不会重复写入;
是否需要人工确认;
是否能从检查点继续。所以,大模型工程的可靠性不是只让模型「少犯错」。
而是让整个系统在模型、工具、数据、网络和用户行为都可能出错时,仍然能可控地前进。
十一、常见误解
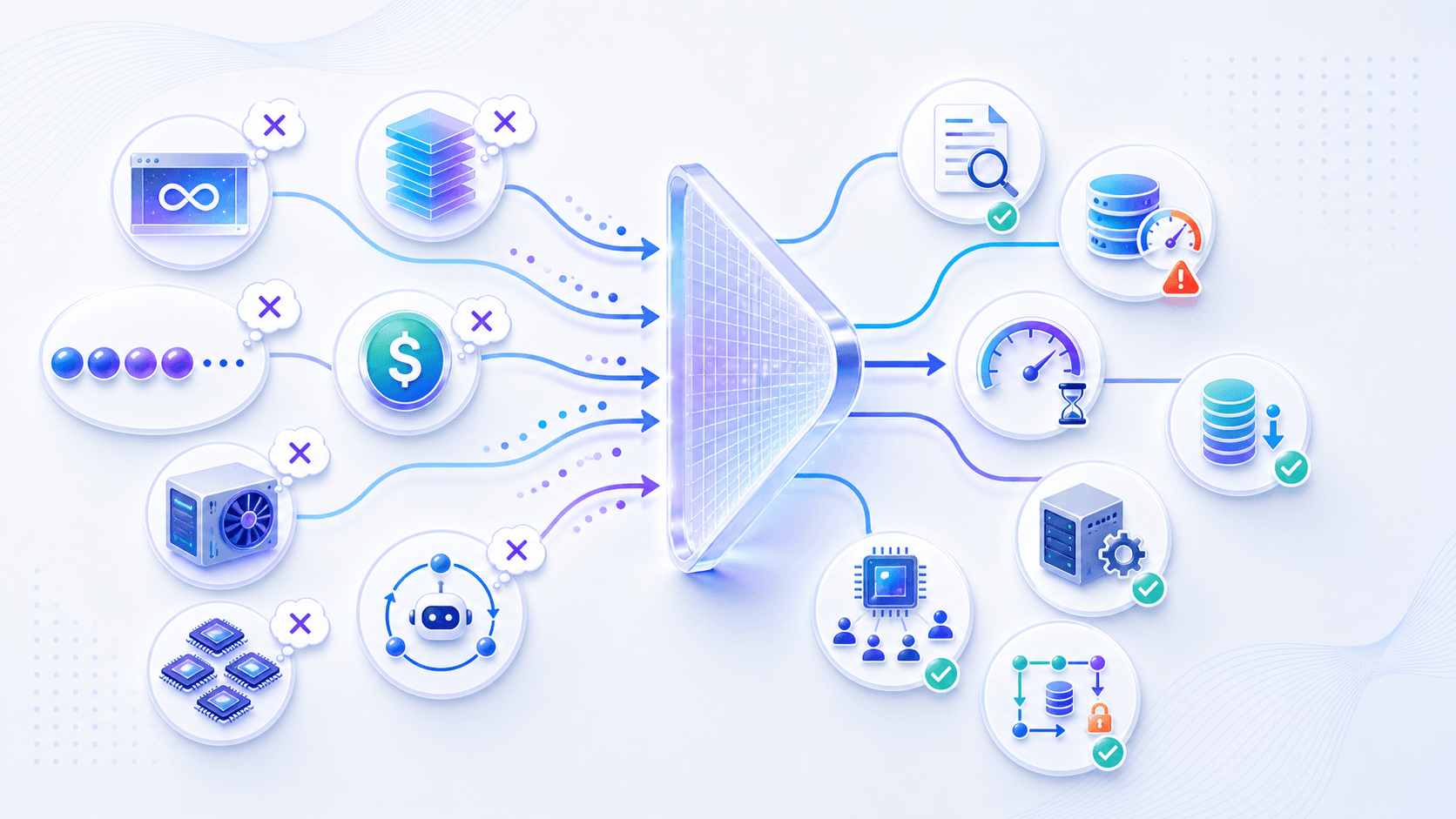
误解一:上下文窗口越大,产品就越聪明。
不一定。大上下文扩大了可读取范围,但也增加 prefill、KV Cache、成本和注意力干扰。真正重要的是把正确的信息放进上下文。
误解二:KV Cache 就是普通缓存。
不准确。KV Cache 缓存的是 Transformer 注意力里的中间状态,不是缓存最终答案,也不是 RAG 的文档缓存。
误解三:流式输出让模型算得更快。
流式输出主要改善体感等待。它让用户更早看到内容,但模型仍然要逐 token 生成。
误解四:便宜模型一定降低成本。
不一定。要看每个成功任务的总成本。如果便宜模型需要更长 prompt、更多重试、更多人工兜底,最终可能更贵。
误解五:自托管一定比 API 便宜。
也不一定。自托管要承担 GPU 利用率、调度、显存、运维、监控、峰值容量和模型升级成本。规模、稳定负载和团队能力足够时才可能划算。
误解六:加更多 GPU 就一定更快。
GPU 增加的是资源,不自动解决调度、KV Cache、网络、批处理、长尾延迟和应用层瓶颈。
误解七:Agent 的成本就是一次模型调用。
不对。Agent 成本来自多步推理、工具调用、RAG、状态管理、失败恢复和最终验证。越自主的 Agent,越需要按任务级别估算成本。
十二、产品与工程含义

理解大模型工程后,我们会重新看 AI 产品设计。
一个好用的 AI 产品,不只是:
选一个强模型;
写一个好 prompt;
接一个聊天框。它还要回答:
哪些请求需要强模型;
哪些请求可以走小模型;
什么时候应该检索;
什么时候应该调用工具;
上下文如何裁剪和摘要;
长任务如何保存状态;
失败后如何恢复;
用户等待时看到什么;
成本超限时如何降级;
哪些指标决定产品是否健康。这就是为什么 AI Native 产品和传统 SaaS 不太一样。
传统 SaaS 里的按钮通常对应确定性的代码路径。
AI 产品里的同一个按钮,背后可能是一段概率生成、上下文组装、模型路由、工具调用和状态恢复的组合。
用户需要的是确定体验。
系统内部却是概率系统。
中间的桥,就是大模型工程。
十三、总结:工程把模型能力变成产品能力
现在我们可以把这篇文章压缩成几句话:
大模型不是一次性生成完整答案,而是逐 token 预测;
一次请求可以拆成 prefill 和 decode;
长输入主要影响上下文处理和 KV Cache;
长输出主要影响逐 token 生成时间;
KV Cache 用显存换速度,但会被长上下文和并发放大;
成本要按成功任务计算,而不是只看 token 单价;
batching、调度和流式输出共同影响吞吐与体感延迟;
部署系统需要网关、上下文、模型路由、工具、监控和失败恢复;
可观测性让团队看见 token、延迟、质量、成本和失败路径;
工程的目标,是把概率模型变成可规模化的产品服务。如果再压缩成一句话:
大模型工程的本质,是围绕逐 token 生成这个约束,管理上下文、显存、并发、成本、延迟和失败路径,把模型能力转化为稳定可用的产品能力。
到这里,我们已经从底层的 token 预测,一路走到了工程系统。
但还差一个重要问题:
既然 AI 系统内部是概率的,
产品应该如何让用户获得确定、可信、可控的体验?十四、你应该能回答的三个问题
读完这一篇,可以试着用自己的话回答:
- prefill 和 decode 为什么对应不同的成本与延迟瓶颈?
- KV Cache 为什么会让长上下文和并发变成工程问题?
- 为什么大模型成本应该按「成功任务」计算,而不只看 token 单价?
下一篇,我们进入 AI Native 产品设计:概率系统如何提供确定体验。